 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlazeEdit: Generalist Image Editing on Mobile Devices with Image-to-Image Diffusion Models
May 27, 2026The remarkable generation quality of modern diffusion models often comes at the cost of massive parameter counts, which necessitate server-side inference with significant computational costs and potential privacy risks. Consequently, there is growing momentum toward developing efficient on-device alternatives. While recent efforts have optimized text-to-image models for mobile hardware, they remain relatively bulky, typically ranging from 0.5B to 1B parameters. We present BlazeEdit, a highly efficient, generalist image-to-image diffusion model tailored for on-device deployment. By identifying that many practical image editing tasks do not require text-based guidance, we eliminate the text-conditioning components and develop a multi-task architecture that consolidates object removal, outpainting, tone correction, relighting, and sticker generation into a single, compact model of only 195M parameters. BlazeEdit achieves a substantial reduction in download size and memory overhead while maintaining competitive generation quality. It completes a full inference pass in just 290ms on a Pixel 10, delivering a seamless, privacy-preserving, and lightning-fast experience for generalist image editing on the edge.
Blendshapes GHUM: Real-time Monocular Facial Blendshape Prediction
Sep 11, 2023We present Blendshapes GHUM, an on-device ML pipeline that predicts 52 facial blendshape coefficients at 30+ FPS on modern mobile phones, from a single monocular RGB image and enables facial motion capture applications like virtual avatars. Our main contributions are: i) an annotation-free offline method for obtaining blendshape coefficients from real-world human scans, ii) a lightweight real-time model that predicts blendshape coefficients based on facial landmarks.
Efficient Heterogeneous Video Segmentation at the Edge
Aug 24, 2022
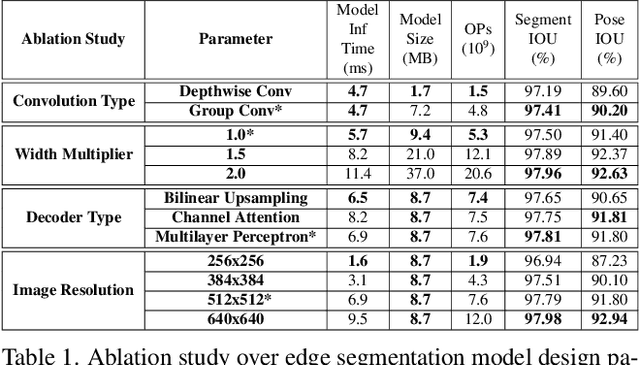
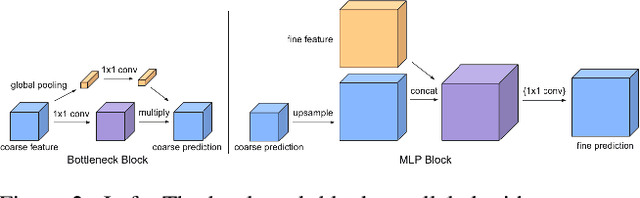
We introduce an efficient video segmentation system for resource-limited edge devices leveraging heterogeneous compute. Specifically, we design network models by searching across multiple dimensions of specifications for the neural architectures and operations on top of already light-weight backbones, targeting commercially available edge inference engines. We further analyze and optimize the heterogeneous data flows in our systems across the CPU, the GPU and the NPU. Our approach has empirically factored well into our real-time AR system, enabling remarkably higher accuracy with quadrupled effective resolutions, yet at much shorter end-to-end latency, much higher frame rate, and even lower power consumption on edge platforms.
BlazePose GHUM Holistic: Real-time 3D Human Landmarks and Pose Estimation
Jun 23, 2022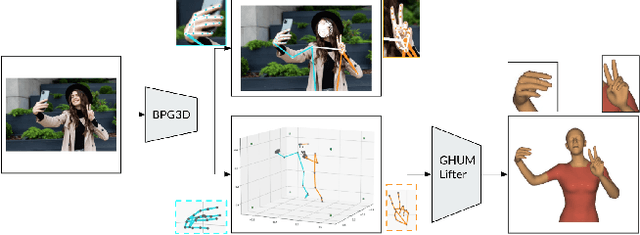
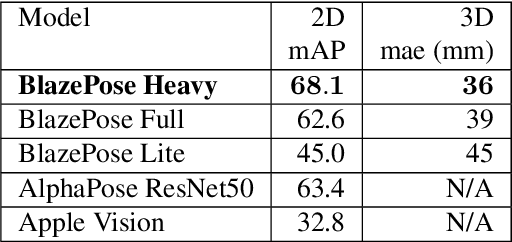
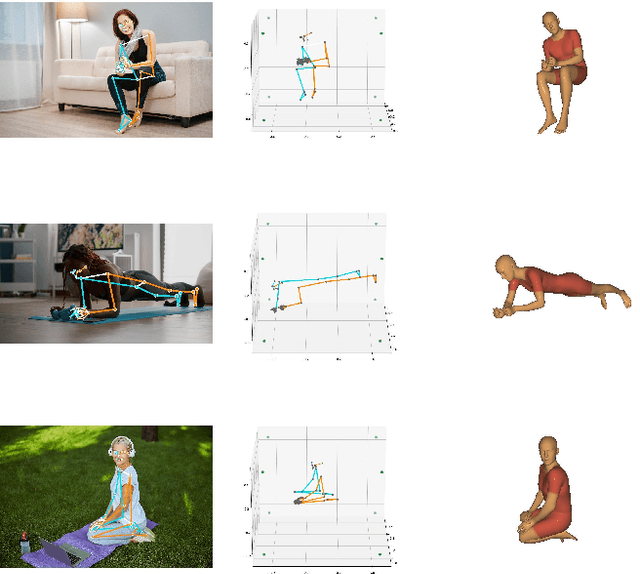
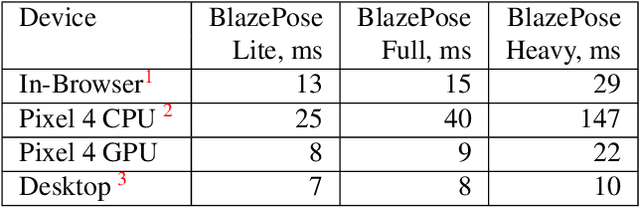
We present BlazePose GHUM Holistic, a lightweight neural network pipeline for 3D human body landmarks and pose estimation, specifically tailored to real-time on-device inference. BlazePose GHUM Holistic enables motion capture from a single RGB image including avatar control, fitness tracking and AR/VR effects. Our main contributions include i) a novel method for 3D ground truth data acquisition, ii) updated 3D body tracking with additional hand landmarks and iii) full body pose estimation from a monocular image.
Real-time Pupil Tracking from Monocular Video for Digital Puppetry
Jun 19, 2020
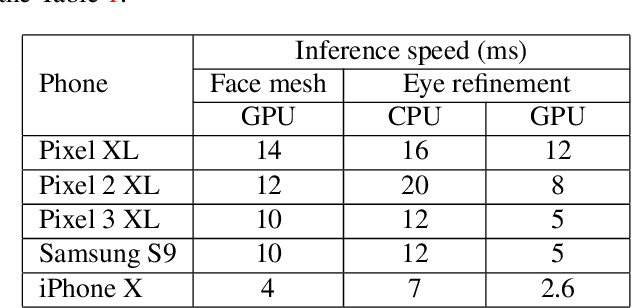
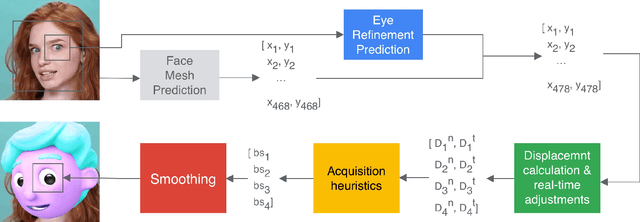
We present a simple, real-time approach for pupil tracking from live video on mobile devices. Our method extends a state-of-the-art face mesh detector with two new components: a tiny neural network that predicts positions of the pupils in 2D, and a displacement-based estimation of the pupil blend shape coefficients. Our technique can be used to accurately control the pupil movements of a virtual puppet, and lends liveliness and energy to it. The proposed approach runs at over 50 FPS on modern phones, and enables its usage in any real-time puppeteering pipeline.
Attention Mesh: High-fidelity Face Mesh Prediction in Real-time
Jun 19, 2020
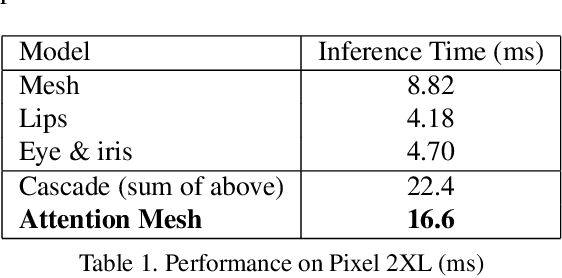
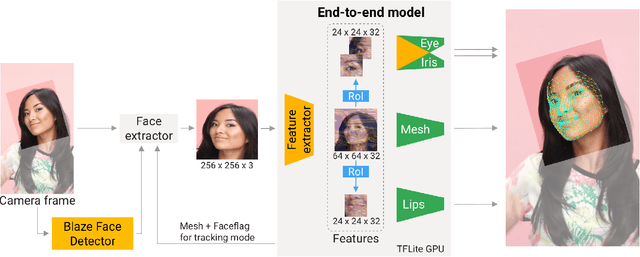
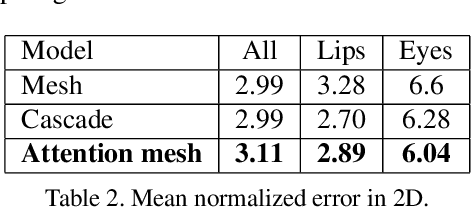
We present Attention Mesh, a lightweight architecture for 3D face mesh prediction that uses attention to semantically meaningful regions. Our neural network is designed for real-time on-device inference and runs at over 50 FPS on a Pixel 2 phone. Our solution enables applications like AR makeup, eye tracking and AR puppeteering that rely on highly accurate landmarks for eye and lips regions. Our main contribution is a unified network architecture that achieves the same accuracy on facial landmarks as a multi-stage cascaded approach, while being 30 percent faster.
BlazePose: On-device Real-time Body Pose tracking
Jun 17, 2020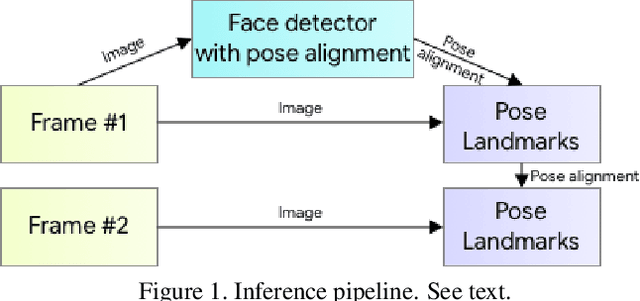
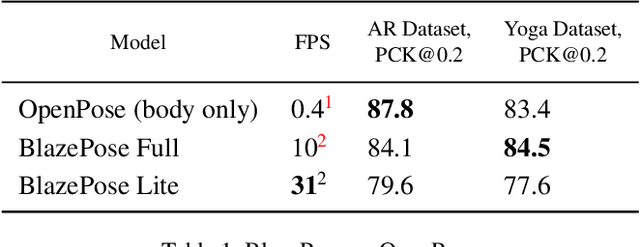
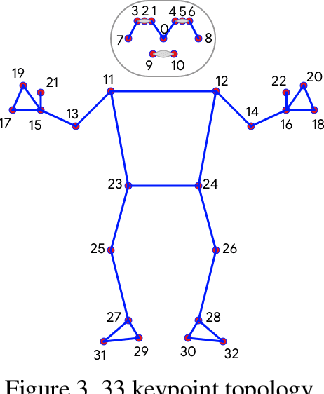
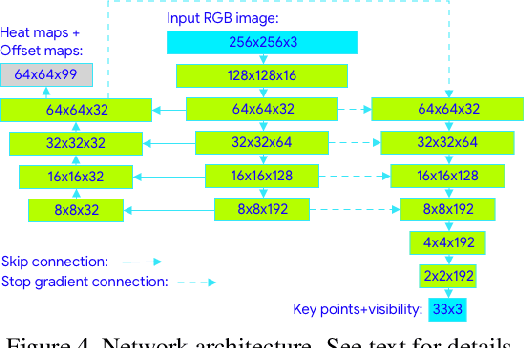
We present BlazePose, a lightweight convolutional neural network architecture for human pose estimation that is tailored for real-time inference on mobile devices. During inference, the network produces 33 body keypoints for a single person and runs at over 30 frames per second on a Pixel 2 phone. This makes it particularly suited to real-time use cases like fitness tracking and sign language recognition. Our main contributions include a novel body pose tracking solution and a lightweight body pose estimation neural network that uses both heatmaps and regression to keypoint coordinates.
BlazeFace: Sub-millisecond Neural Face Detection on Mobile GPUs
Jul 14, 2019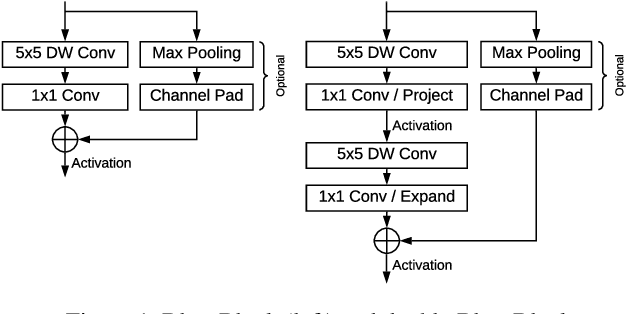
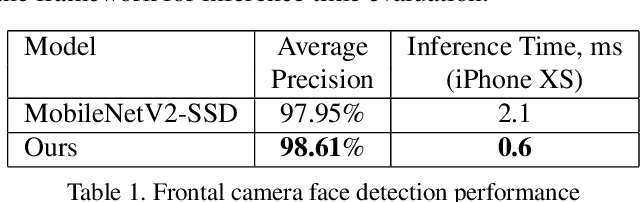
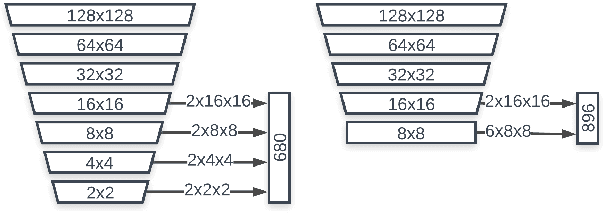
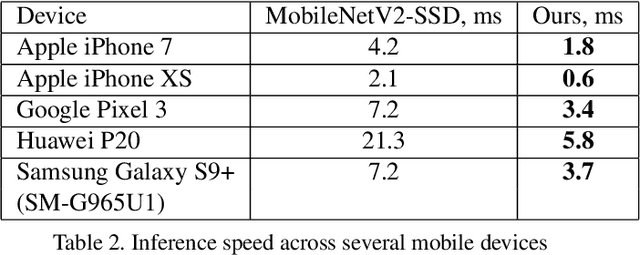
We present BlazeFace, a lightweight and well-performing face detector tailored for mobile GPU inference. It runs at a speed of 200-1000+ FPS on flagship devices. This super-realtime performance enables it to be applied to any augmented reality pipeline that requires an accurate facial region of interest as an input for task-specific models, such as 2D/3D facial keypoint or geometry estimation, facial features or expression classification, and face region segmentation. Our contributions include a lightweight feature extraction network inspired by, but distinct from MobileNetV1/V2, a GPU-friendly anchor scheme modified from Single Shot MultiBox Detector (SSD), and an improved tie resolution strategy alternative to non-maximum suppression.
Floors are Flat: Leveraging Semantics for Real-Time Surface Normal Prediction
Jun 16, 2019
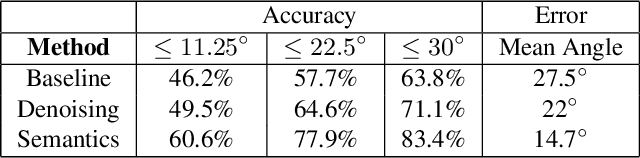

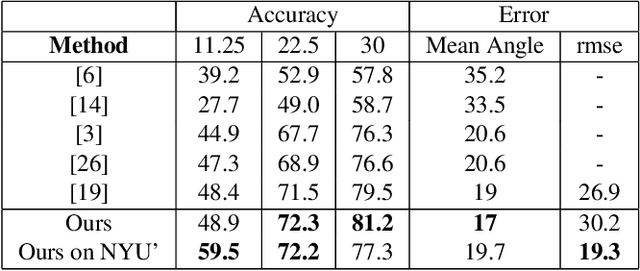
We propose 4 insights that help to significantly improve the performance of deep learning models that predict surface normals and semantic labels from a single RGB image. These insights are: (1) denoise the "ground truth" surface normals in the training set to ensure consistency with the semantic labels; (2) concurrently train on a mix of real and synthetic data, instead of pretraining on synthetic and finetuning on real; (3) jointly predict normals and semantics using a shared model, but only backpropagate errors on pixels that have valid training labels; (4) slim down the model and use grayscale instead of color inputs. Despite the simplicity of these steps, we demonstrate consistently improved results on several datasets, using a model that runs at 12 fps on a standard mobile phone.