 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-time Pupil Tracking from Monocular Video for Digital Puppetry
Jun 19, 2020
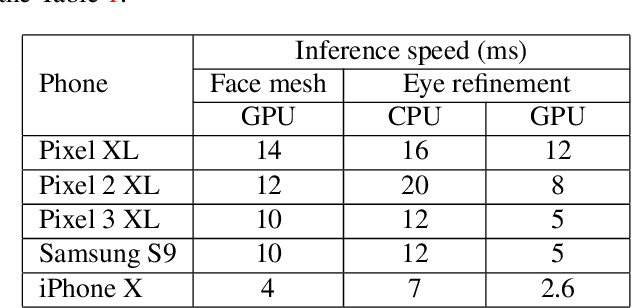
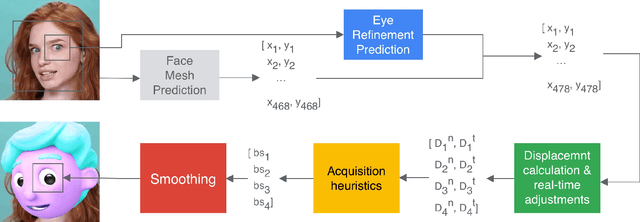
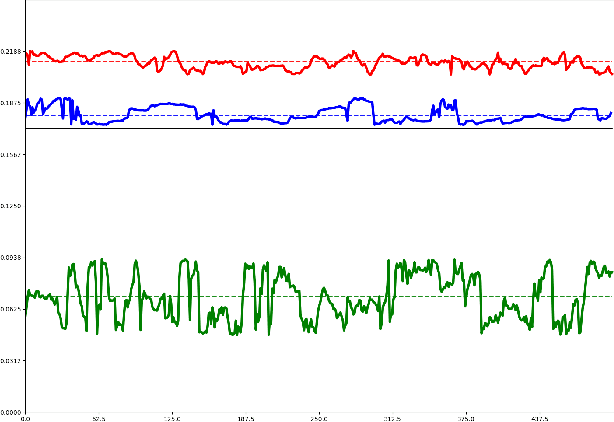
We present a simple, real-time approach for pupil tracking from live video on mobile devices. Our method extends a state-of-the-art face mesh detector with two new components: a tiny neural network that predicts positions of the pupils in 2D, and a displacement-based estimation of the pupil blend shape coefficients. Our technique can be used to accurately control the pupil movements of a virtual puppet, and lends liveliness and energy to it. The proposed approach runs at over 50 FPS on modern phones, and enables its usage in any real-time puppeteering pipeline.
MediaPipe Hands: On-device Real-time Hand Tracking
Jun 18, 2020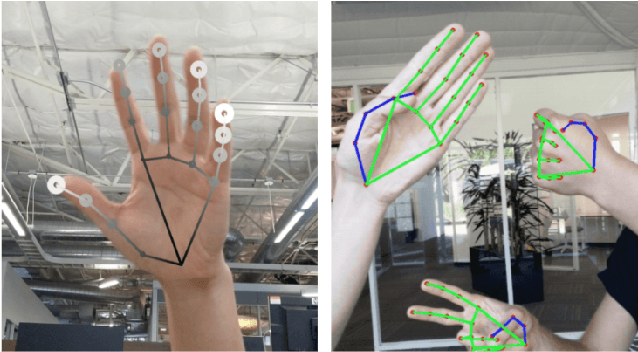
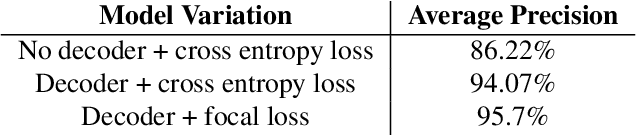

We present a real-time on-device hand tracking pipeline that predicts hand skeleton from single RGB camera for AR/VR applications. The pipeline consists of two models: 1) a palm detector, 2) a hand landmark model. It's implemented via MediaPipe, a framework for building cross-platform ML solutions. The proposed model and pipeline architecture demonstrates real-time inference speed on mobile GPUs and high prediction quality. MediaPipe Hands is open sourced at https://mediapipe.dev.
Real-time Hair Segmentation and Recoloring on Mobile GPUs
Jul 15, 2019
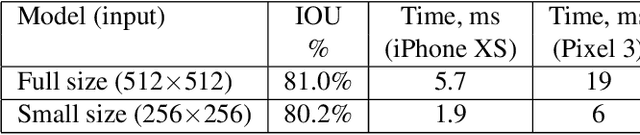

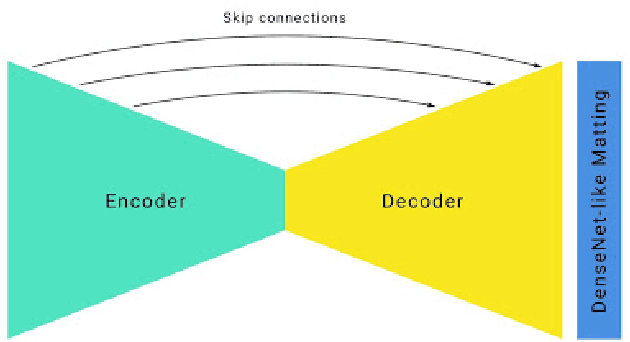
We present a novel approach for neural network-based hair segmentation from a single camera input specifically designed for real-time, mobile application. Our relatively small neural network produces a high-quality hair segmentation mask that is well suited for AR effects, e.g. virtual hair recoloring. The proposed model achieves real-time inference speed on mobile GPUs (30-100+ FPS, depending on the device) with high accuracy. We also propose a very realistic hair recoloring scheme. Our method has been deployed in major AR application and is used by millions of users.
BlazeFace: Sub-millisecond Neural Face Detection on Mobile GPUs
Jul 14, 2019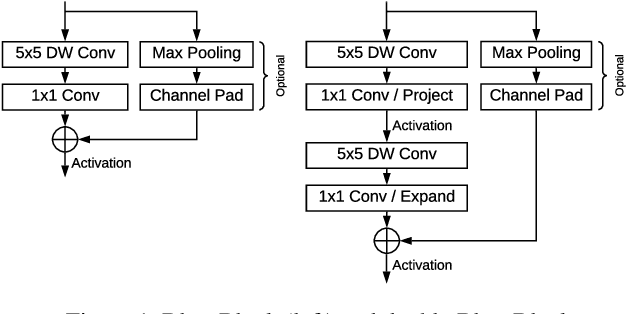
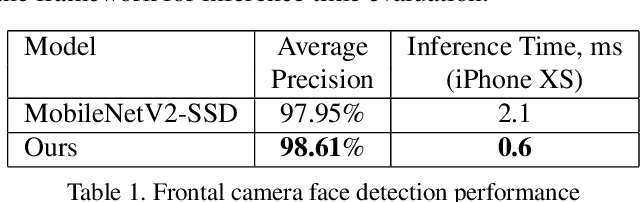
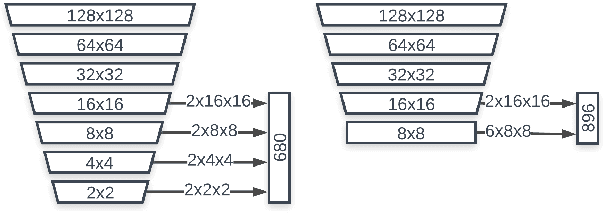
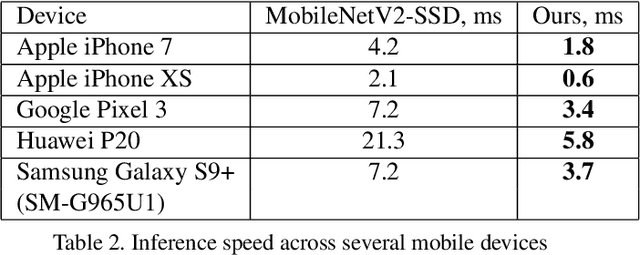
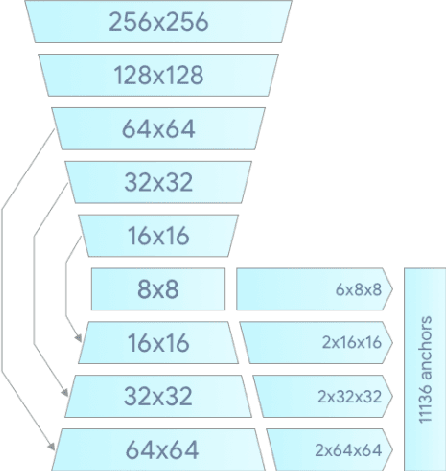
We present BlazeFace, a lightweight and well-performing face detector tailored for mobile GPU inference. It runs at a speed of 200-1000+ FPS on flagship devices. This super-realtime performance enables it to be applied to any augmented reality pipeline that requires an accurate facial region of interest as an input for task-specific models, such as 2D/3D facial keypoint or geometry estimation, facial features or expression classification, and face region segmentation. Our contributions include a lightweight feature extraction network inspired by, but distinct from MobileNetV1/V2, a GPU-friendly anchor scheme modified from Single Shot MultiBox Detector (SSD), and an improved tie resolution strategy alternative to non-maximum suppression.