 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObjectron: A Large Scale Dataset of Object-Centric Videos in the Wild with Pose Annotations
Dec 18, 2020

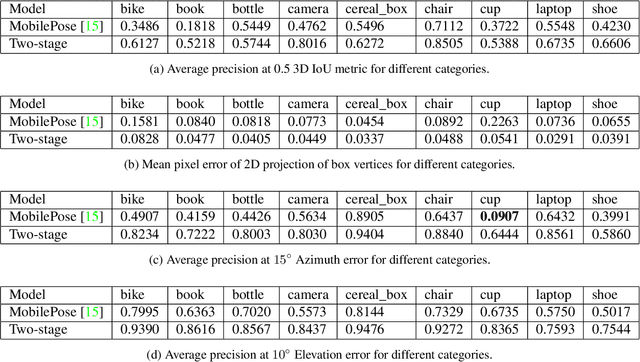
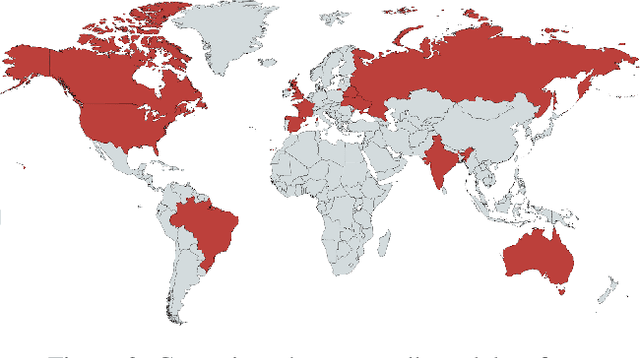
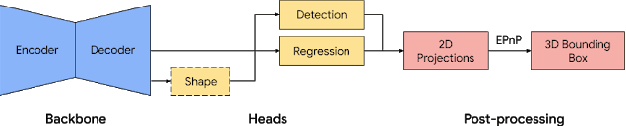
3D object detection has recently become popular due to many applications in robotics, augmented reality, autonomy, and image retrieval. We introduce the Objectron dataset to advance the state of the art in 3D object detection and foster new research and applications, such as 3D object tracking, view synthesis, and improved 3D shape representation. The dataset contains object-centric short videos with pose annotations for nine categories and includes 4 million annotated images in 14,819 annotated videos. We also propose a new evaluation metric, 3D Intersection over Union, for 3D object detection. We demonstrate the usefulness of our dataset in 3D object detection tasks by providing baseline models trained on this dataset. Our dataset and evaluation source code are available online at http://www.objectron.dev
Instant 3D Object Tracking with Applications in Augmented Reality
Jun 23, 2020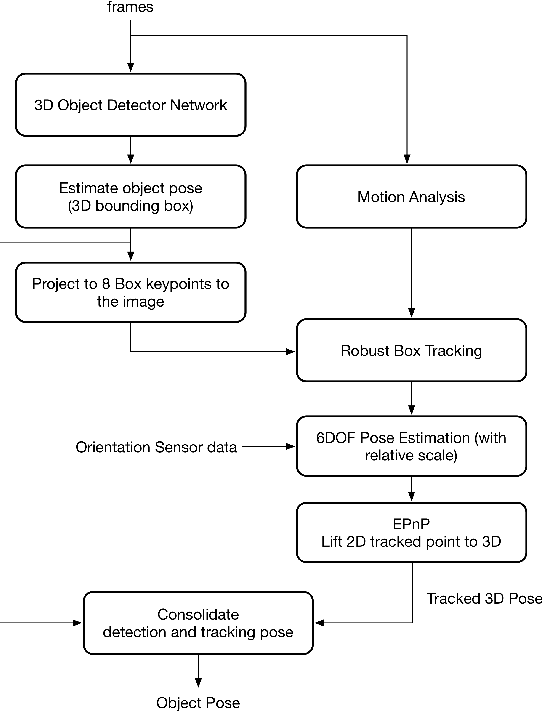


Tracking object poses in 3D is a crucial building block for Augmented Reality applications. We propose an instant motion tracking system that tracks an object's pose in space (represented by its 3D bounding box) in real-time on mobile devices. Our system does not require any prior sensory calibration or initialization to function. We employ a deep neural network to detect objects and estimate their initial 3D pose. Then the estimated pose is tracked using a robust planar tracker. Our tracker is capable of performing relative-scale 9-DoF tracking in real-time on mobile devices. By combining use of CPU and GPU efficiently, we achieve 26-FPS+ performance on mobile devices.
Real-time Pupil Tracking from Monocular Video for Digital Puppetry
Jun 19, 2020
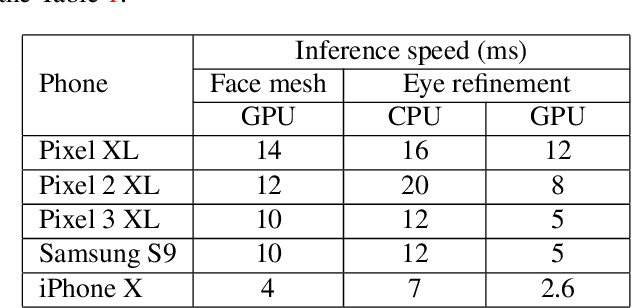
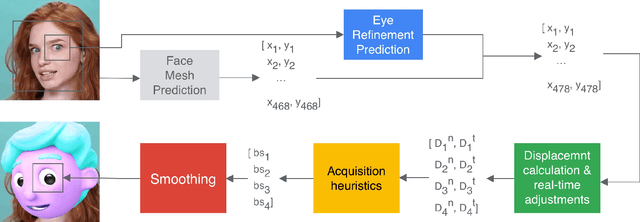
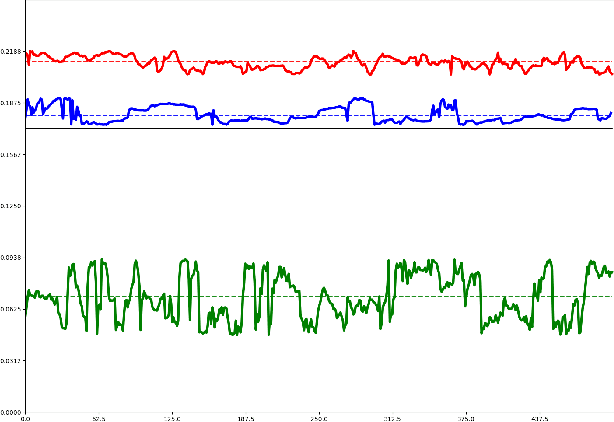
We present a simple, real-time approach for pupil tracking from live video on mobile devices. Our method extends a state-of-the-art face mesh detector with two new components: a tiny neural network that predicts positions of the pupils in 2D, and a displacement-based estimation of the pupil blend shape coefficients. Our technique can be used to accurately control the pupil movements of a virtual puppet, and lends liveliness and energy to it. The proposed approach runs at over 50 FPS on modern phones, and enables its usage in any real-time puppeteering pipeline.
Attention Mesh: High-fidelity Face Mesh Prediction in Real-time
Jun 19, 2020
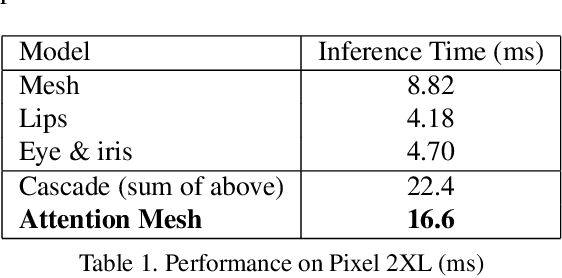
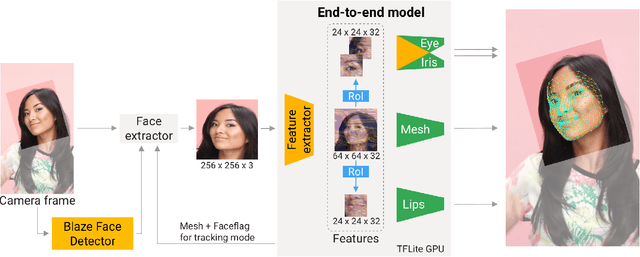
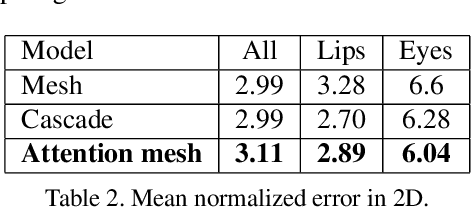
We present Attention Mesh, a lightweight architecture for 3D face mesh prediction that uses attention to semantically meaningful regions. Our neural network is designed for real-time on-device inference and runs at over 50 FPS on a Pixel 2 phone. Our solution enables applications like AR makeup, eye tracking and AR puppeteering that rely on highly accurate landmarks for eye and lips regions. Our main contribution is a unified network architecture that achieves the same accuracy on facial landmarks as a multi-stage cascaded approach, while being 30 percent faster.
The Two-Pass Softmax Algorithm
Jan 13, 2020


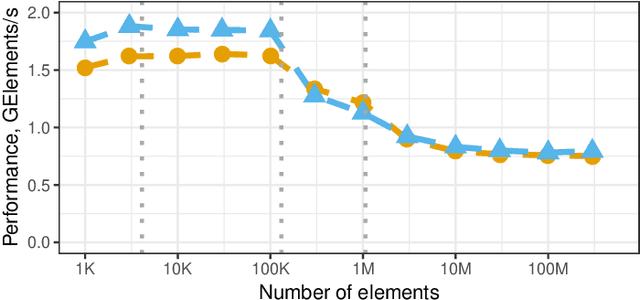
The softmax (also called softargmax) function is widely used in machine learning models to normalize real-valued scores into a probability distribution. To avoid floating-point overflow, the softmax function is conventionally implemented in three passes: the first pass to compute the normalization constant, and two other passes to compute outputs from normalized inputs. We analyze two variants of the Three-Pass algorithm and demonstrate that in a well-optimized implementation on HPC-class processors performance of all three passes is limited by memory bandwidth. We then present a novel algorithm for softmax computation in just two passes. The proposed Two-Pass algorithm avoids both numerical overflow and the extra normalization pass by employing an exotic representation for intermediate values, where each value is represented as a pair of floating-point numbers: one representing the "mantissa" and another representing the "exponent". Performance evaluation demonstrates that on out-of-cache inputs on an Intel Skylake-X processor the new Two-Pass algorithm outperforms the traditional Three-Pass algorithm by up to 28% in AVX512 implementation, and by up to 18% in AVX2 implementation. The proposed Two-Pass algorithm also outperforms the traditional Three-Pass algorithm on Intel Broadwell and AMD Zen 2 processors. To foster reproducibility, we released an open-source implementation of the new Two-Pass Softmax algorithm and other experiments in this paper as a part of XNNPACK library at GitHub.com/google/XNNPACK.
Real-time Hair Segmentation and Recoloring on Mobile GPUs
Jul 15, 2019
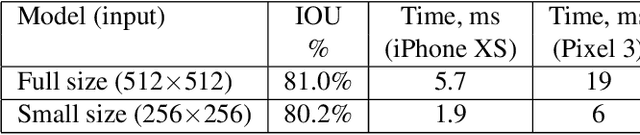

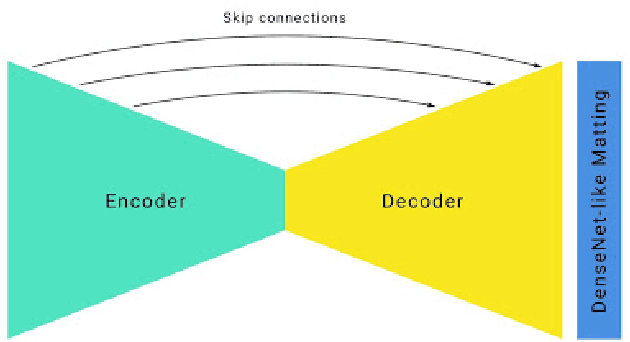
We present a novel approach for neural network-based hair segmentation from a single camera input specifically designed for real-time, mobile application. Our relatively small neural network produces a high-quality hair segmentation mask that is well suited for AR effects, e.g. virtual hair recoloring. The proposed model achieves real-time inference speed on mobile GPUs (30-100+ FPS, depending on the device) with high accuracy. We also propose a very realistic hair recoloring scheme. Our method has been deployed in major AR application and is used by millions of users.
Real-time Facial Surface Geometry from Monocular Video on Mobile GPUs
Jul 15, 2019
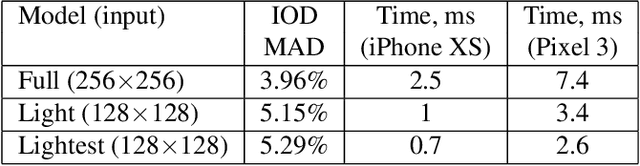

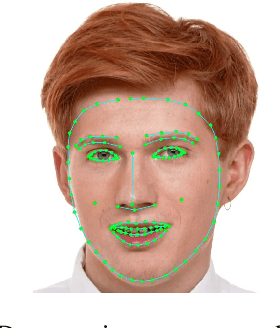
We present an end-to-end neural network-based model for inferring an approximate 3D mesh representation of a human face from single camera input for AR applications. The relatively dense mesh model of 468 vertices is well-suited for face-based AR effects. The proposed model demonstrates super-realtime inference speed on mobile GPUs (100-1000+ FPS, depending on the device and model variant) and a high prediction quality that is comparable to the variance in manual annotations of the same image.
Enriched Deep Recurrent Visual Attention Model for Multiple Object Recognition
Jun 12, 2017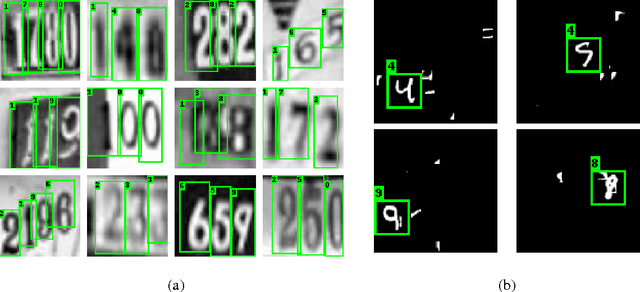

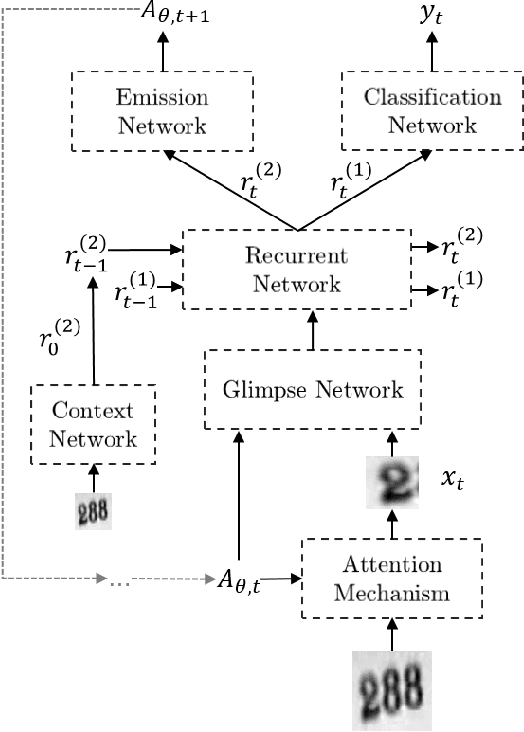
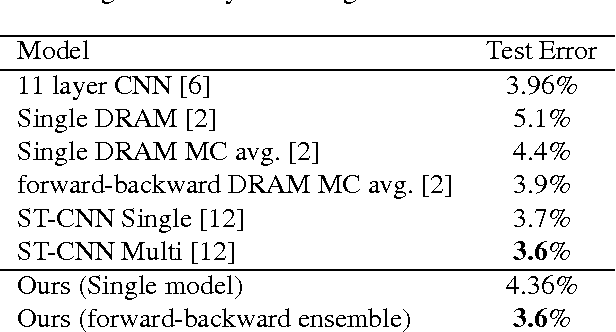
We design an Enriched Deep Recurrent Visual Attention Model (EDRAM) - an improved attention-based architecture for multiple object recognition. The proposed model is a fully differentiable unit that can be optimized end-to-end by using Stochastic Gradient Descent (SGD). The Spatial Transformer (ST) was employed as visual attention mechanism which allows to learn the geometric transformation of objects within images. With the combination of the Spatial Transformer and the powerful recurrent architecture, the proposed EDRAM can localize and recognize objects simultaneously. EDRAM has been evaluated on two publicly available datasets including MNIST Cluttered (with 70K cluttered digits) and SVHN (with up to 250k real world images of house numbers). Experiments show that it obtains superior performance as compared with the state-of-the-art models.
WordFence: Text Detection in Natural Images with Border Awareness
May 15, 2017
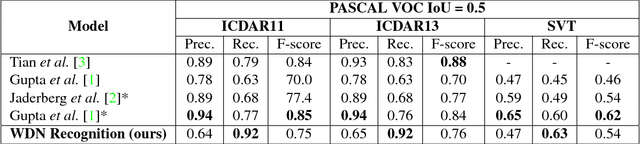

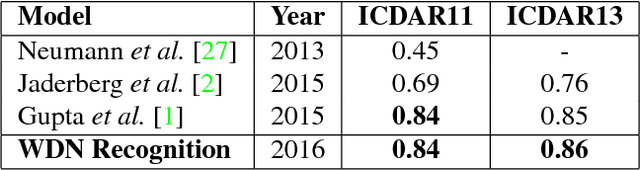
In recent years, text recognition has achieved remarkable success in recognizing scanned document text. However, word recognition in natural images is still an open problem, which generally requires time consuming post-processing steps. We present a novel architecture for individual word detection in scene images based on semantic segmentation. Our contributions are twofold: the concept of WordFence, which detects border areas surrounding each individual word and a novel pixelwise weighted softmax loss function which penalizes background and emphasizes small text regions. WordFence ensures that each word is detected individually, and the new loss function provides a strong training signal to both text and word border localization. The proposed technique avoids intensive post-processing, producing an end-to-end word detection system. We achieve superior localization recall on common benchmark datasets - 92% recall on ICDAR11 and ICDAR13 and 63% recall on SVT. Furthermore, our end-to-end word recognition system achieves state-of-the-art 86% F-Score on ICDAR13.