 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnriched Deep Recurrent Visual Attention Model for Multiple Object Recognition
Paper and Code
Jun 12, 2017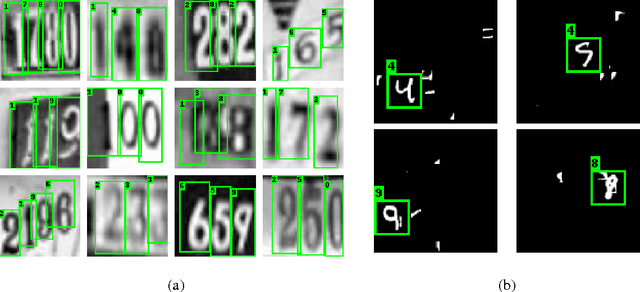

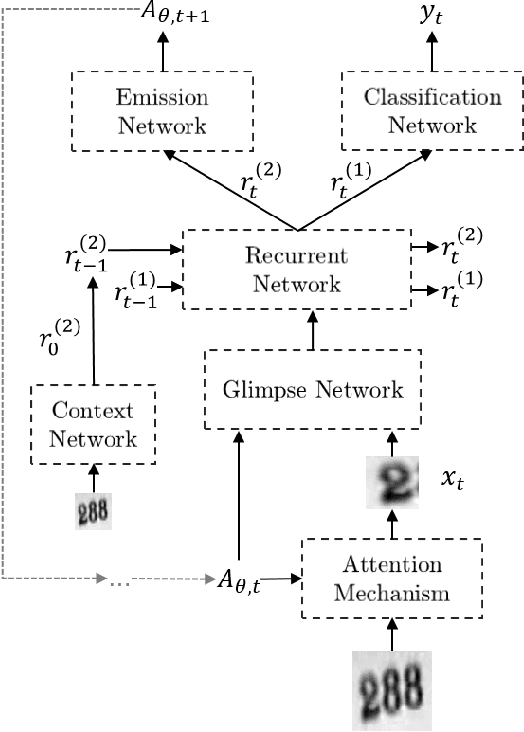
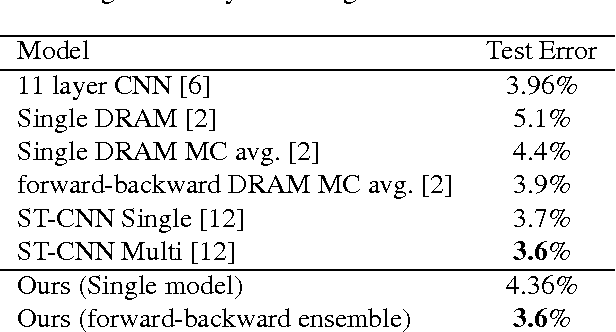
We design an Enriched Deep Recurrent Visual Attention Model (EDRAM) - an improved attention-based architecture for multiple object recognition. The proposed model is a fully differentiable unit that can be optimized end-to-end by using Stochastic Gradient Descent (SGD). The Spatial Transformer (ST) was employed as visual attention mechanism which allows to learn the geometric transformation of objects within images. With the combination of the Spatial Transformer and the powerful recurrent architecture, the proposed EDRAM can localize and recognize objects simultaneously. EDRAM has been evaluated on two publicly available datasets including MNIST Cluttered (with 70K cluttered digits) and SVHN (with up to 250k real world images of house numbers). Experiments show that it obtains superior performance as compared with the state-of-the-art models.