 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObjectron: A Large Scale Dataset of Object-Centric Videos in the Wild with Pose Annotations
Dec 18, 2020

3D object detection has recently become popular due to many applications in robotics, augmented reality, autonomy, and image retrieval. We introduce the Objectron dataset to advance the state of the art in 3D object detection and foster new research and applications, such as 3D object tracking, view synthesis, and improved 3D shape representation. The dataset contains object-centric short videos with pose annotations for nine categories and includes 4 million annotated images in 14,819 annotated videos. We also propose a new evaluation metric, 3D Intersection over Union, for 3D object detection. We demonstrate the usefulness of our dataset in 3D object detection tasks by providing baseline models trained on this dataset. Our dataset and evaluation source code are available online at http://www.objectron.dev
Instant 3D Object Tracking with Applications in Augmented Reality
Jun 23, 2020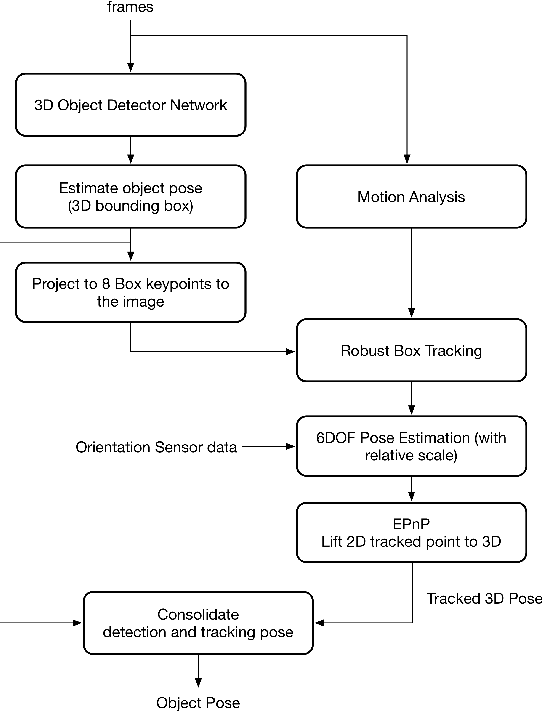


Tracking object poses in 3D is a crucial building block for Augmented Reality applications. We propose an instant motion tracking system that tracks an object's pose in space (represented by its 3D bounding box) in real-time on mobile devices. Our system does not require any prior sensory calibration or initialization to function. We employ a deep neural network to detect objects and estimate their initial 3D pose. Then the estimated pose is tracked using a robust planar tracker. Our tracker is capable of performing relative-scale 9-DoF tracking in real-time on mobile devices. By combining use of CPU and GPU efficiently, we achieve 26-FPS+ performance on mobile devices.
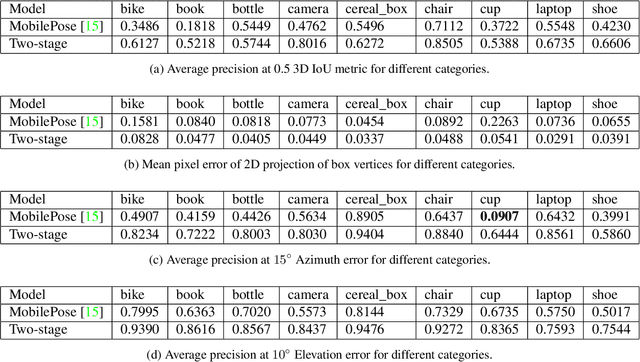
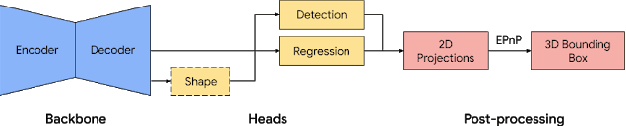
MobilePose: Real-Time Pose Estimation for Unseen Objects with Weak Shape Supervision
Mar 07, 2020



In this paper, we address the problem of detecting unseen objects from RGB images and estimating their poses in 3D. We propose two mobile friendly networks: MobilePose-Base and MobilePose-Shape. The former is used when there is only pose supervision, and the latter is for the case when shape supervision is available, even a weak one. We revisit shape features used in previous methods, including segmentation and coordinate map. We explain when and why pixel-level shape supervision can improve pose estimation. Consequently, we add shape prediction as an intermediate layer in the MobilePose-Shape, and let the network learn pose from shape. Our models are trained on mixed real and synthetic data, with weak and noisy shape supervision. They are ultra lightweight that can run in real-time on modern mobile devices (e.g. 36 FPS on Galaxy S20). Comparing with previous single-shot solutions, our method has higher accuracy, while using a significantly smaller model (2~3% in model size or number of parameters).