 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling On-Device GPU Inference for Large Generative Models
May 01, 2025


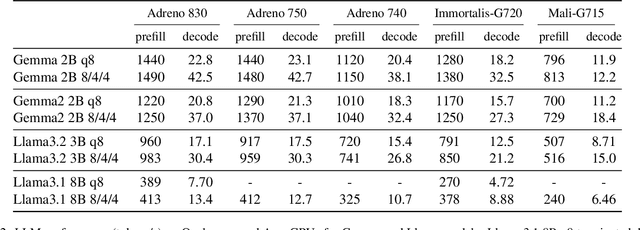
Driven by the advancements in generative AI, large machine learning models have revolutionized domains such as image processing, audio synthesis, and speech recognition. While server-based deployments remain the locus of peak performance, the imperative for on-device inference, necessitated by privacy and efficiency considerations, persists. Recognizing GPUs as the on-device ML accelerator with the widest reach, we present ML Drift--an optimized framework that extends the capabilities of state-of-the-art GPU-accelerated inference engines. ML Drift enables on-device execution of generative AI workloads which contain 10 to 100x more parameters than existing on-device generative AI models. ML Drift addresses intricate engineering challenges associated with cross-GPU API development, and ensures broad compatibility across mobile and desktop/laptop platforms, thereby facilitating the deployment of significantly more complex models on resource-constrained devices. Our GPU-accelerated ML/AI inference engine achieves an order-of-magnitude performance improvement relative to existing open-source GPU inference engines.
PRDP: Proximal Reward Difference Prediction for Large-Scale Reward Finetuning of Diffusion Models
Feb 13, 2024



Reward finetuning has emerged as a promising approach to aligning foundation models with downstream objectives. Remarkable success has been achieved in the language domain by using reinforcement learning (RL) to maximize rewards that reflect human preference. However, in the vision domain, existing RL-based reward finetuning methods are limited by their instability in large-scale training, rendering them incapable of generalizing to complex, unseen prompts. In this paper, we propose Proximal Reward Difference Prediction (PRDP), enabling stable black-box reward finetuning for diffusion models for the first time on large-scale prompt datasets with over 100K prompts. Our key innovation is the Reward Difference Prediction (RDP) objective that has the same optimal solution as the RL objective while enjoying better training stability. Specifically, the RDP objective is a supervised regression objective that tasks the diffusion model with predicting the reward difference of generated image pairs from their denoising trajectories. We theoretically prove that the diffusion model that obtains perfect reward difference prediction is exactly the maximizer of the RL objective. We further develop an online algorithm with proximal updates to stably optimize the RDP objective. In experiments, we demonstrate that PRDP can match the reward maximization ability of well-established RL-based methods in small-scale training. Furthermore, through large-scale training on text prompts from the Human Preference Dataset v2 and the Pick-a-Pic v1 dataset, PRDP achieves superior generation quality on a diverse set of complex, unseen prompts whereas RL-based methods completely fail.
Binaural Angular Separation Network
Jan 16, 2024



We propose a neural network model that can separate target speech sources from interfering sources at different angular regions using two microphones. The model is trained with simulated room impulse responses (RIRs) using omni-directional microphones without needing to collect real RIRs. By relying on specific angular regions and multiple room simulations, the model utilizes consistent time difference of arrival (TDOA) cues, or what we call delay contrast, to separate target and interference sources while remaining robust in various reverberation environments. We demonstrate the model is not only generalizable to a commercially available device with a slightly different microphone geometry, but also outperforms our previous work which uses one additional microphone on the same device. The model runs in real-time on-device and is suitable for low-latency streaming applications such as telephony and video conferencing.
StreamVC: Real-Time Low-Latency Voice Conversion
Jan 05, 2024We present StreamVC, a streaming voice conversion solution that preserves the content and prosody of any source speech while matching the voice timbre from any target speech. Unlike previous approaches, StreamVC produces the resulting waveform at low latency from the input signal even on a mobile platform, making it applicable to real-time communication scenarios like calls and video conferencing, and addressing use cases such as voice anonymization in these scenarios. Our design leverages the architecture and training strategy of the SoundStream neural audio codec for lightweight high-quality speech synthesis. We demonstrate the feasibility of learning soft speech units causally, as well as the effectiveness of supplying whitened fundamental frequency information to improve pitch stability without leaking the source timbre information.
On-device Real-time Custom Hand Gesture Recognition
Sep 19, 2023



Most existing hand gesture recognition (HGR) systems are limited to a predefined set of gestures. However, users and developers often want to recognize new, unseen gestures. This is challenging due to the vast diversity of all plausible hand shapes, e.g. it is impossible for developers to include all hand gestures in a predefined list. In this paper, we present a user-friendly framework that lets users easily customize and deploy their own gesture recognition pipeline. Our framework provides a pre-trained single-hand embedding model that can be fine-tuned for custom gesture recognition. Users can perform gestures in front of a webcam to collect a small amount of images per gesture. We also offer a low-code solution to train and deploy the custom gesture recognition model. This makes it easy for users with limited ML expertise to use our framework. We further provide a no-code web front-end for users without any ML expertise. This makes it even easier to build and test the end-to-end pipeline. The resulting custom HGR is then ready to be run on-device for real-time scenarios. This can be done by calling a simple function in our open-sourced model inference API, MediaPipe Tasks. This entire process only takes a few minutes.
Blendshapes GHUM: Real-time Monocular Facial Blendshape Prediction
Sep 11, 2023We present Blendshapes GHUM, an on-device ML pipeline that predicts 52 facial blendshape coefficients at 30+ FPS on modern mobile phones, from a single monocular RGB image and enables facial motion capture applications like virtual avatars. Our main contributions are: i) an annotation-free offline method for obtaining blendshape coefficients from real-world human scans, ii) a lightweight real-time model that predicts blendshape coefficients based on facial landmarks.
Towards Authentic Face Restoration with Iterative Diffusion Models and Beyond
Jul 18, 2023



An authentic face restoration system is becoming increasingly demanding in many computer vision applications, e.g., image enhancement, video communication, and taking portrait. Most of the advanced face restoration models can recover high-quality faces from low-quality ones but usually fail to faithfully generate realistic and high-frequency details that are favored by users. To achieve authentic restoration, we propose $\textbf{IDM}$, an $\textbf{I}$teratively learned face restoration system based on denoising $\textbf{D}$iffusion $\textbf{M}$odels (DDMs). We define the criterion of an authentic face restoration system, and argue that denoising diffusion models are naturally endowed with this property from two aspects: intrinsic iterative refinement and extrinsic iterative enhancement. Intrinsic learning can preserve the content well and gradually refine the high-quality details, while extrinsic enhancement helps clean the data and improve the restoration task one step further. We demonstrate superior performance on blind face restoration tasks. Beyond restoration, we find the authentically cleaned data by the proposed restoration system is also helpful to image generation tasks in terms of training stabilization and sample quality. Without modifying the models, we achieve better quality than state-of-the-art on FFHQ and ImageNet generation using either GANs or diffusion models.
Semi-Implicit Denoising Diffusion Models (SIDDMs)
Jun 23, 2023



Despite the proliferation of generative models, achieving fast sampling during inference without compromising sample diversity and quality remains challenging. Existing models such as Denoising Diffusion Probabilistic Models (DDPM) deliver high-quality, diverse samples but are slowed by an inherently high number of iterative steps. The Denoising Diffusion Generative Adversarial Networks (DDGAN) attempted to circumvent this limitation by integrating a GAN model for larger jumps in the diffusion process. However, DDGAN encountered scalability limitations when applied to large datasets. To address these limitations, we introduce a novel approach that tackles the problem by matching implicit and explicit factors. More specifically, our approach involves utilizing an implicit model to match the marginal distributions of noisy data and the explicit conditional distribution of the forward diffusion. This combination allows us to effectively match the joint denoising distributions. Unlike DDPM but similar to DDGAN, we do not enforce a parametric distribution for the reverse step, enabling us to take large steps during inference. Similar to the DDPM but unlike DDGAN, we take advantage of the exact form of the diffusion process. We demonstrate that our proposed method obtains comparable generative performance to diffusion-based models and vastly superior results to models with a small number of sampling steps.
Speed Is All You Need: On-Device Acceleration of Large Diffusion Models via GPU-Aware Optimizations
Apr 21, 2023



The rapid development and application of foundation models have revolutionized the field of artificial intelligence. Large diffusion models have gained significant attention for their ability to generate photorealistic images and support various tasks. On-device deployment of these models provides benefits such as lower server costs, offline functionality, and improved user privacy. However, common large diffusion models have over 1 billion parameters and pose challenges due to restricted computational and memory resources on devices. We present a series of implementation optimizations for large diffusion models that achieve the fastest reported inference latency to-date (under 12 seconds for Stable Diffusion 1.4 without int8 quantization on Samsung S23 Ultra for a 512x512 image with 20 iterations) on GPU-equipped mobile devices. These enhancements broaden the applicability of generative AI and improve the overall user experience across a wide range of devices.
Guided Speech Enhancement Network
Mar 13, 2023High quality speech capture has been widely studied for both voice communication and human computer interface reasons. To improve the capture performance, we can often find multi-microphone speech enhancement techniques deployed on various devices. Multi-microphone speech enhancement problem is often decomposed into two decoupled steps: a beamformer that provides spatial filtering and a single-channel speech enhancement model that cleans up the beamformer output. In this work, we propose a speech enhancement solution that takes both the raw microphone and beamformer outputs as the input for an ML model. We devise a simple yet effective training scheme that allows the model to learn from the cues of the beamformer by contrasting the two inputs and greatly boost its capability in spatial rejection, while conducting the general tasks of denoising and dereverberation. The proposed solution takes advantage of classical spatial filtering algorithms instead of competing with them. By design, the beamformer module then could be selected separately and does not require a large amount of data to be optimized for a given form factor, and the network model can be considered as a standalone module which is highly transferable independently from the microphone array. We name the ML module in our solution as GSENet, short for Guided Speech Enhancement Network. We demonstrate its effectiveness on real world data collected on multi-microphone devices in terms of the suppression of noise and interfering speech.