 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling On-Device GPU Inference for Large Generative Models
May 01, 2025Driven by the advancements in generative AI, large machine learning models have revolutionized domains such as image processing, audio synthesis, and speech recognition. While server-based deployments remain the locus of peak performance, the imperative for on-device inference, necessitated by privacy and efficiency considerations, persists. Recognizing GPUs as the on-device ML accelerator with the widest reach, we present ML Drift--an optimized framework that extends the capabilities of state-of-the-art GPU-accelerated inference engines. ML Drift enables on-device execution of generative AI workloads which contain 10 to 100x more parameters than existing on-device generative AI models. ML Drift addresses intricate engineering challenges associated with cross-GPU API development, and ensures broad compatibility across mobile and desktop/laptop platforms, thereby facilitating the deployment of significantly more complex models on resource-constrained devices. Our GPU-accelerated ML/AI inference engine achieves an order-of-magnitude performance improvement relative to existing open-source GPU inference engines.
Speed Is All You Need: On-Device Acceleration of Large Diffusion Models via GPU-Aware Optimizations
Apr 21, 2023



The rapid development and application of foundation models have revolutionized the field of artificial intelligence. Large diffusion models have gained significant attention for their ability to generate photorealistic images and support various tasks. On-device deployment of these models provides benefits such as lower server costs, offline functionality, and improved user privacy. However, common large diffusion models have over 1 billion parameters and pose challenges due to restricted computational and memory resources on devices. We present a series of implementation optimizations for large diffusion models that achieve the fastest reported inference latency to-date (under 12 seconds for Stable Diffusion 1.4 without int8 quantization on Samsung S23 Ultra for a 512x512 image with 20 iterations) on GPU-equipped mobile devices. These enhancements broaden the applicability of generative AI and improve the overall user experience across a wide range of devices.
Efficient Heterogeneous Video Segmentation at the Edge
Aug 24, 2022
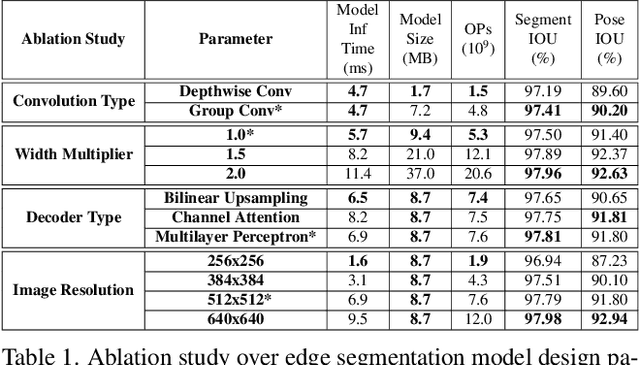
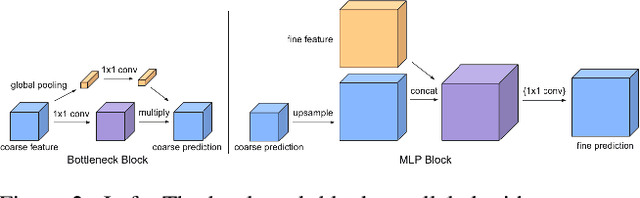
We introduce an efficient video segmentation system for resource-limited edge devices leveraging heterogeneous compute. Specifically, we design network models by searching across multiple dimensions of specifications for the neural architectures and operations on top of already light-weight backbones, targeting commercially available edge inference engines. We further analyze and optimize the heterogeneous data flows in our systems across the CPU, the GPU and the NPU. Our approach has empirically factored well into our real-time AR system, enabling remarkably higher accuracy with quadrupled effective resolutions, yet at much shorter end-to-end latency, much higher frame rate, and even lower power consumption on edge platforms.
On-Device Neural Net Inference with Mobile GPUs
Jul 03, 2019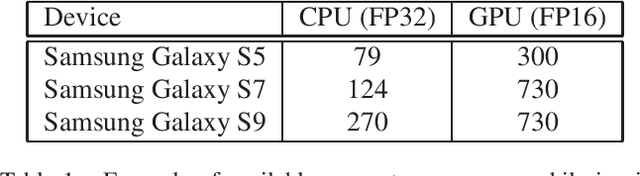
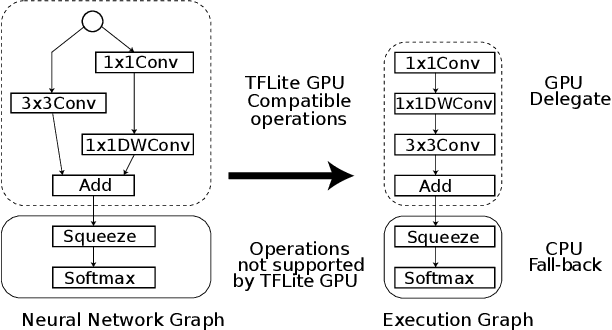
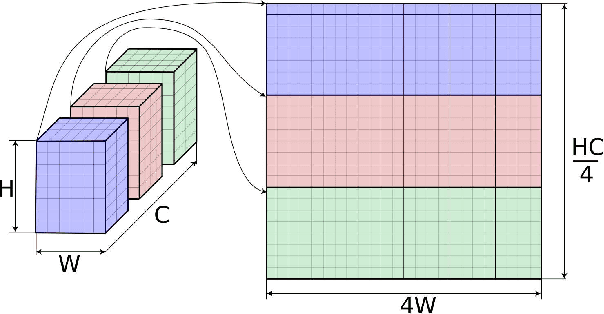

On-device inference of machine learning models for mobile phones is desirable due to its lower latency and increased privacy. Running such a compute-intensive task solely on the mobile CPU, however, can be difficult due to limited computing power, thermal constraints, and energy consumption. App developers and researchers have begun exploiting hardware accelerators to overcome these challenges. Recently, device manufacturers are adding neural processing units into high-end phones for on-device inference, but these account for only a small fraction of hand-held devices. In this paper, we present how we leverage the mobile GPU, a ubiquitous hardware accelerator on virtually every phone, to run inference of deep neural networks in real-time for both Android and iOS devices. By describing our architecture, we also discuss how to design networks that are mobile GPU-friendly. Our state-of-the-art mobile GPU inference engine is integrated into the open-source project TensorFlow Lite and publicly available at https://tensorflow.org/lite.