 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreamVC: Real-Time Low-Latency Voice Conversion
Jan 05, 2024We present StreamVC, a streaming voice conversion solution that preserves the content and prosody of any source speech while matching the voice timbre from any target speech. Unlike previous approaches, StreamVC produces the resulting waveform at low latency from the input signal even on a mobile platform, making it applicable to real-time communication scenarios like calls and video conferencing, and addressing use cases such as voice anonymization in these scenarios. Our design leverages the architecture and training strategy of the SoundStream neural audio codec for lightweight high-quality speech synthesis. We demonstrate the feasibility of learning soft speech units causally, as well as the effectiveness of supplying whitened fundamental frequency information to improve pitch stability without leaking the source timbre information.
Attention Mesh: High-fidelity Face Mesh Prediction in Real-time
Jun 19, 2020
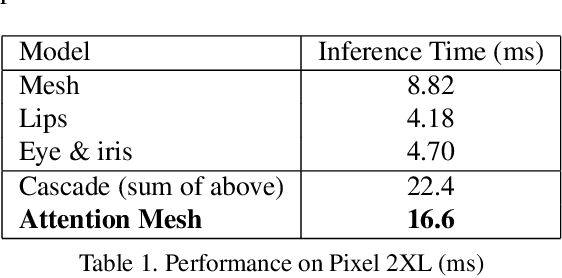
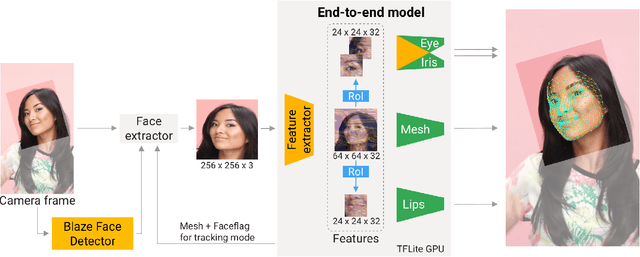
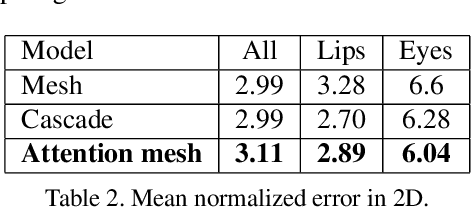
We present Attention Mesh, a lightweight architecture for 3D face mesh prediction that uses attention to semantically meaningful regions. Our neural network is designed for real-time on-device inference and runs at over 50 FPS on a Pixel 2 phone. Our solution enables applications like AR makeup, eye tracking and AR puppeteering that rely on highly accurate landmarks for eye and lips regions. Our main contribution is a unified network architecture that achieves the same accuracy on facial landmarks as a multi-stage cascaded approach, while being 30 percent faster.
Real-time Hair Segmentation and Recoloring on Mobile GPUs
Jul 15, 2019
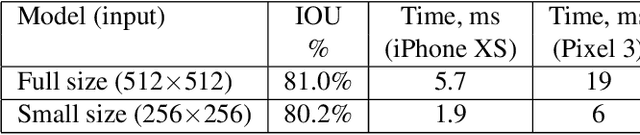

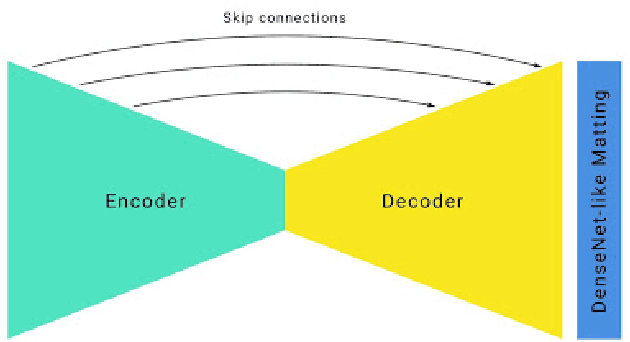
We present a novel approach for neural network-based hair segmentation from a single camera input specifically designed for real-time, mobile application. Our relatively small neural network produces a high-quality hair segmentation mask that is well suited for AR effects, e.g. virtual hair recoloring. The proposed model achieves real-time inference speed on mobile GPUs (30-100+ FPS, depending on the device) with high accuracy. We also propose a very realistic hair recoloring scheme. Our method has been deployed in major AR application and is used by millions of users.
Real-time Facial Surface Geometry from Monocular Video on Mobile GPUs
Jul 15, 2019
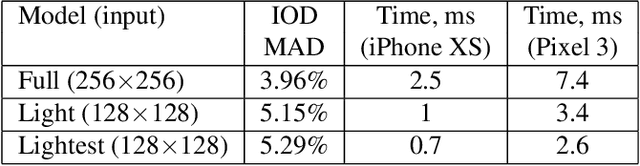

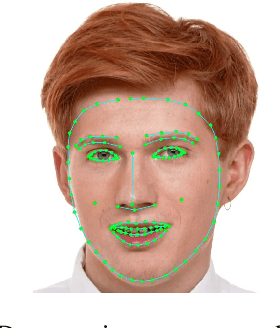
We present an end-to-end neural network-based model for inferring an approximate 3D mesh representation of a human face from single camera input for AR applications. The relatively dense mesh model of 468 vertices is well-suited for face-based AR effects. The proposed model demonstrates super-realtime inference speed on mobile GPUs (100-1000+ FPS, depending on the device and model variant) and a high prediction quality that is comparable to the variance in manual annotations of the same image.
BlazeFace: Sub-millisecond Neural Face Detection on Mobile GPUs
Jul 14, 2019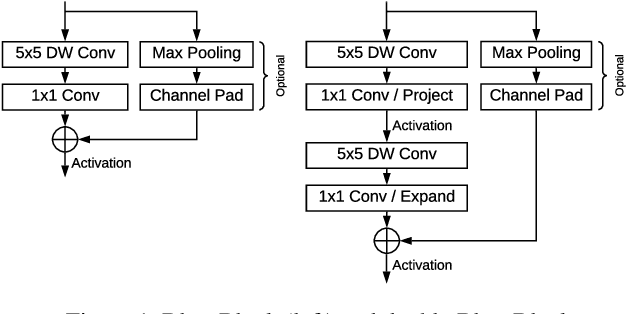
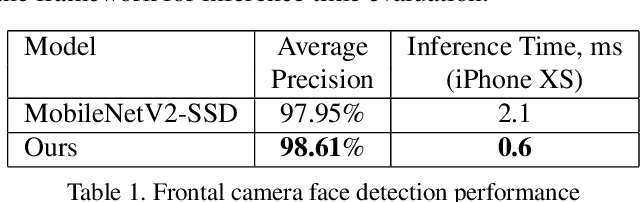
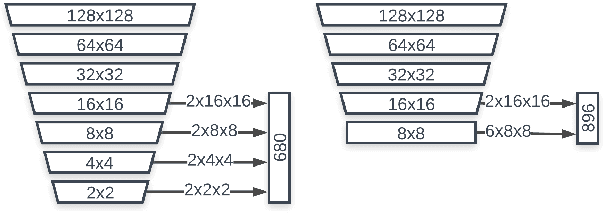
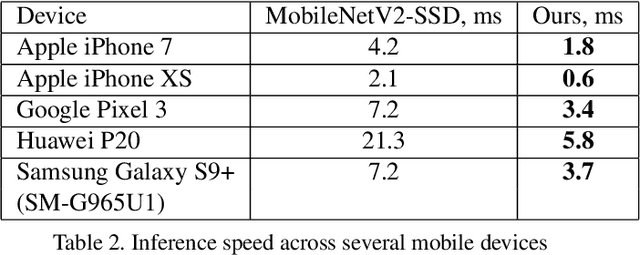
We present BlazeFace, a lightweight and well-performing face detector tailored for mobile GPU inference. It runs at a speed of 200-1000+ FPS on flagship devices. This super-realtime performance enables it to be applied to any augmented reality pipeline that requires an accurate facial region of interest as an input for task-specific models, such as 2D/3D facial keypoint or geometry estimation, facial features or expression classification, and face region segmentation. Our contributions include a lightweight feature extraction network inspired by, but distinct from MobileNetV1/V2, a GPU-friendly anchor scheme modified from Single Shot MultiBox Detector (SSD), and an improved tie resolution strategy alternative to non-maximum suppression.