 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLive Music Models
Aug 06, 2025We introduce a new class of generative models for music called live music models that produce a continuous stream of music in real-time with synchronized user control. We release Magenta RealTime, an open-weights live music model that can be steered using text or audio prompts to control acoustic style. On automatic metrics of music quality, Magenta RealTime outperforms other open-weights music generation models, despite using fewer parameters and offering first-of-its-kind live generation capabilities. We also release Lyria RealTime, an API-based model with extended controls, offering access to our most powerful model with wide prompt coverage. These models demonstrate a new paradigm for AI-assisted music creation that emphasizes human-in-the-loop interaction for live music performance.
Gemma: Open Models Based on Gemini Research and Technology
Mar 13, 2024



This work introduces Gemma, a family of lightweight, state-of-the art open models built from the research and technology used to create Gemini models. Gemma models demonstrate strong performance across academic benchmarks for language understanding, reasoning, and safety. We release two sizes of models (2 billion and 7 billion parameters), and provide both pretrained and fine-tuned checkpoints. Gemma outperforms similarly sized open models on 11 out of 18 text-based tasks, and we present comprehensive evaluations of safety and responsibility aspects of the models, alongside a detailed description of model development. We believe the responsible release of LLMs is critical for improving the safety of frontier models, and for enabling the next wave of LLM innovations.
Blendshapes GHUM: Real-time Monocular Facial Blendshape Prediction
Sep 11, 2023We present Blendshapes GHUM, an on-device ML pipeline that predicts 52 facial blendshape coefficients at 30+ FPS on modern mobile phones, from a single monocular RGB image and enables facial motion capture applications like virtual avatars. Our main contributions are: i) an annotation-free offline method for obtaining blendshape coefficients from real-world human scans, ii) a lightweight real-time model that predicts blendshape coefficients based on facial landmarks.
BlazePose GHUM Holistic: Real-time 3D Human Landmarks and Pose Estimation
Jun 23, 2022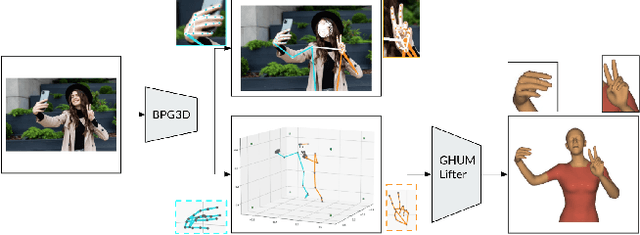
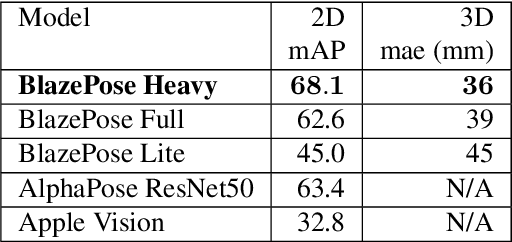
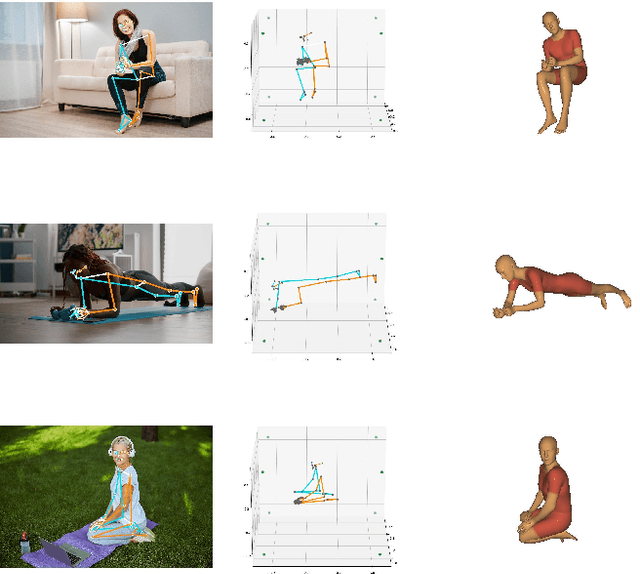
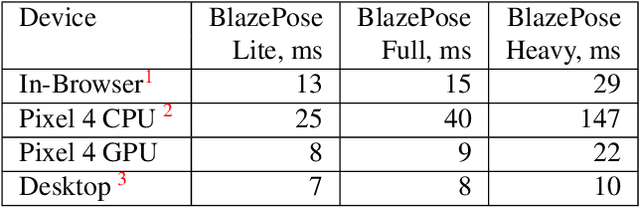
We present BlazePose GHUM Holistic, a lightweight neural network pipeline for 3D human body landmarks and pose estimation, specifically tailored to real-time on-device inference. BlazePose GHUM Holistic enables motion capture from a single RGB image including avatar control, fitness tracking and AR/VR effects. Our main contributions include i) a novel method for 3D ground truth data acquisition, ii) updated 3D body tracking with additional hand landmarks and iii) full body pose estimation from a monocular image.
Real-time Pupil Tracking from Monocular Video for Digital Puppetry
Jun 19, 2020
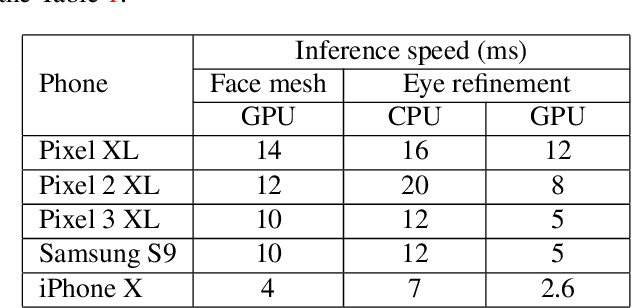
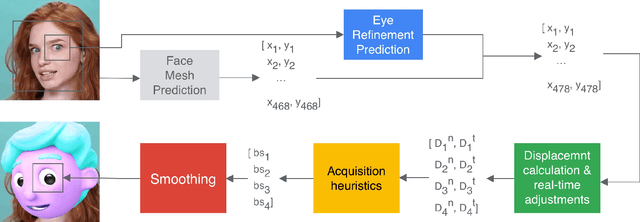
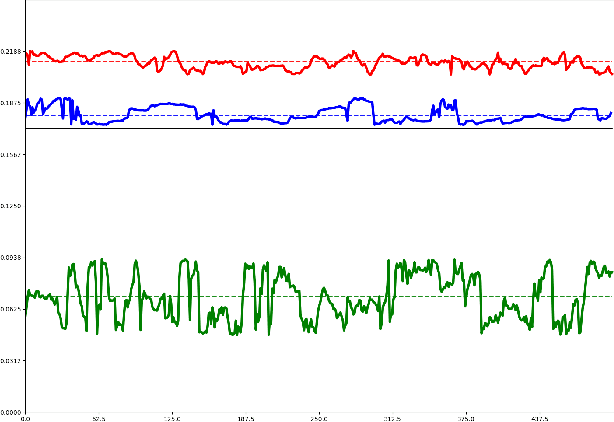
We present a simple, real-time approach for pupil tracking from live video on mobile devices. Our method extends a state-of-the-art face mesh detector with two new components: a tiny neural network that predicts positions of the pupils in 2D, and a displacement-based estimation of the pupil blend shape coefficients. Our technique can be used to accurately control the pupil movements of a virtual puppet, and lends liveliness and energy to it. The proposed approach runs at over 50 FPS on modern phones, and enables its usage in any real-time puppeteering pipeline.
Attention Mesh: High-fidelity Face Mesh Prediction in Real-time
Jun 19, 2020
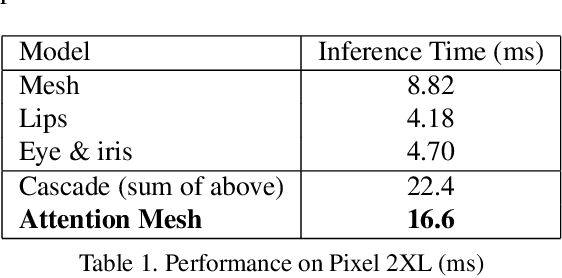
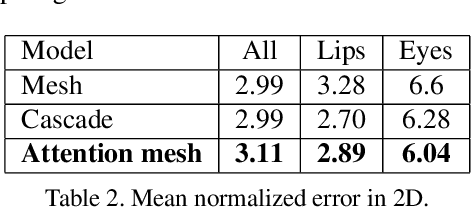
We present Attention Mesh, a lightweight architecture for 3D face mesh prediction that uses attention to semantically meaningful regions. Our neural network is designed for real-time on-device inference and runs at over 50 FPS on a Pixel 2 phone. Our solution enables applications like AR makeup, eye tracking and AR puppeteering that rely on highly accurate landmarks for eye and lips regions. Our main contribution is a unified network architecture that achieves the same accuracy on facial landmarks as a multi-stage cascaded approach, while being 30 percent faster.
BlazePose: On-device Real-time Body Pose tracking
Jun 17, 2020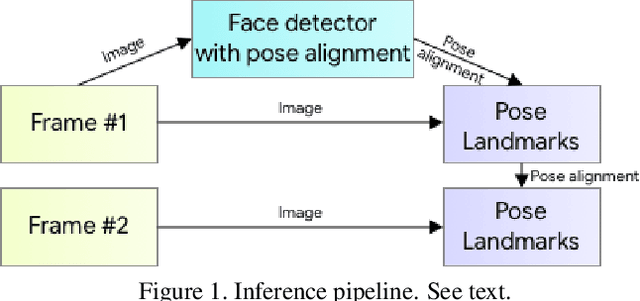
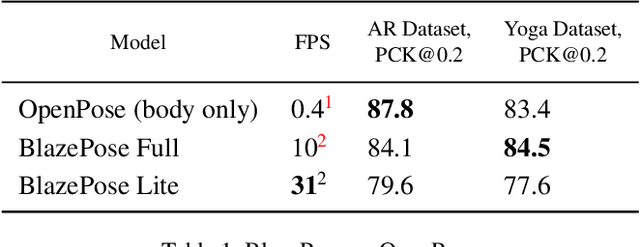
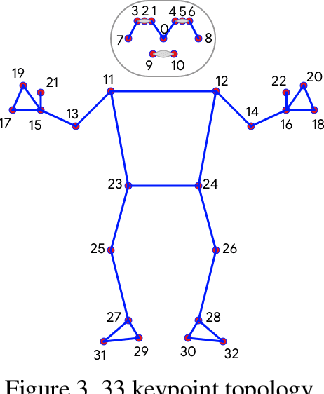
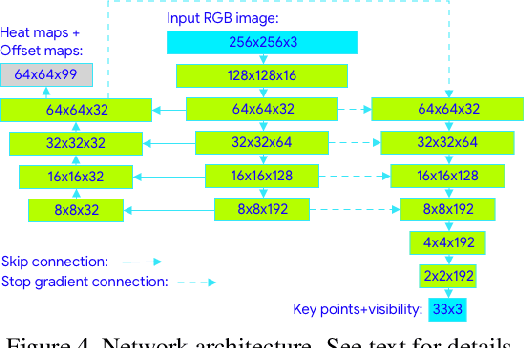
We present BlazePose, a lightweight convolutional neural network architecture for human pose estimation that is tailored for real-time inference on mobile devices. During inference, the network produces 33 body keypoints for a single person and runs at over 30 frames per second on a Pixel 2 phone. This makes it particularly suited to real-time use cases like fitness tracking and sign language recognition. Our main contributions include a novel body pose tracking solution and a lightweight body pose estimation neural network that uses both heatmaps and regression to keypoint coordinates.
Real-time Facial Surface Geometry from Monocular Video on Mobile GPUs
Jul 15, 2019
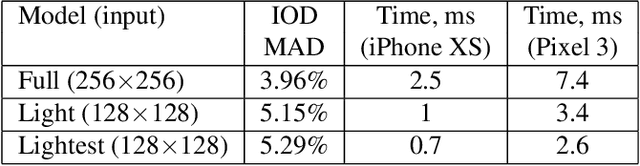

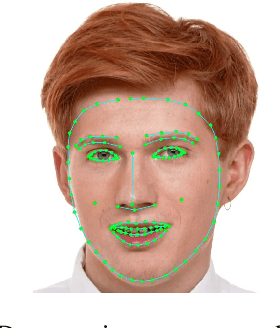
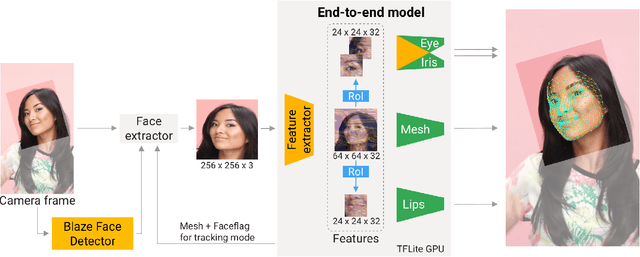
We present an end-to-end neural network-based model for inferring an approximate 3D mesh representation of a human face from single camera input for AR applications. The relatively dense mesh model of 468 vertices is well-suited for face-based AR effects. The proposed model demonstrates super-realtime inference speed on mobile GPUs (100-1000+ FPS, depending on the device and model variant) and a high prediction quality that is comparable to the variance in manual annotations of the same image.