 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPT-4o System Card
Oct 25, 2024GPT-4o is an autoregressive omni model that accepts as input any combination of text, audio, image, and video, and generates any combination of text, audio, and image outputs. It's trained end-to-end across text, vision, and audio, meaning all inputs and outputs are processed by the same neural network. GPT-4o can respond to audio inputs in as little as 232 milliseconds, with an average of 320 milliseconds, which is similar to human response time in conversation. It matches GPT-4 Turbo performance on text in English and code, with significant improvement on text in non-English languages, while also being much faster and 50\% cheaper in the API. GPT-4o is especially better at vision and audio understanding compared to existing models. In line with our commitment to building AI safely and consistent with our voluntary commitments to the White House, we are sharing the GPT-4o System Card, which includes our Preparedness Framework evaluations. In this System Card, we provide a detailed look at GPT-4o's capabilities, limitations, and safety evaluations across multiple categories, focusing on speech-to-speech while also evaluating text and image capabilities, and measures we've implemented to ensure the model is safe and aligned. We also include third-party assessments on dangerous capabilities, as well as discussion of potential societal impacts of GPT-4o's text and vision capabilities.
The Two-Pass Softmax Algorithm
Jan 13, 2020


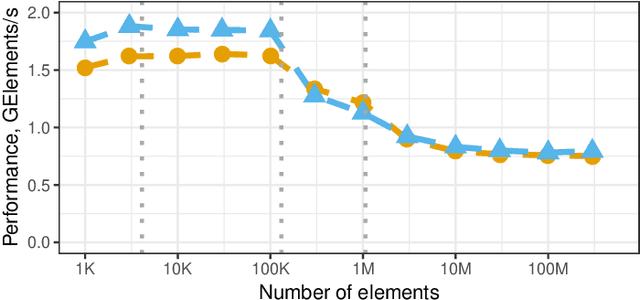
The softmax (also called softargmax) function is widely used in machine learning models to normalize real-valued scores into a probability distribution. To avoid floating-point overflow, the softmax function is conventionally implemented in three passes: the first pass to compute the normalization constant, and two other passes to compute outputs from normalized inputs. We analyze two variants of the Three-Pass algorithm and demonstrate that in a well-optimized implementation on HPC-class processors performance of all three passes is limited by memory bandwidth. We then present a novel algorithm for softmax computation in just two passes. The proposed Two-Pass algorithm avoids both numerical overflow and the extra normalization pass by employing an exotic representation for intermediate values, where each value is represented as a pair of floating-point numbers: one representing the "mantissa" and another representing the "exponent". Performance evaluation demonstrates that on out-of-cache inputs on an Intel Skylake-X processor the new Two-Pass algorithm outperforms the traditional Three-Pass algorithm by up to 28% in AVX512 implementation, and by up to 18% in AVX2 implementation. The proposed Two-Pass algorithm also outperforms the traditional Three-Pass algorithm on Intel Broadwell and AMD Zen 2 processors. To foster reproducibility, we released an open-source implementation of the new Two-Pass Softmax algorithm and other experiments in this paper as a part of XNNPACK library at GitHub.com/google/XNNPACK.
Fast Sparse ConvNets
Nov 21, 2019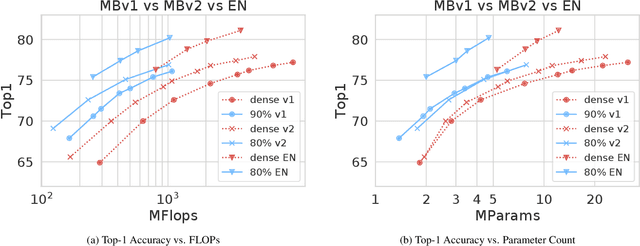
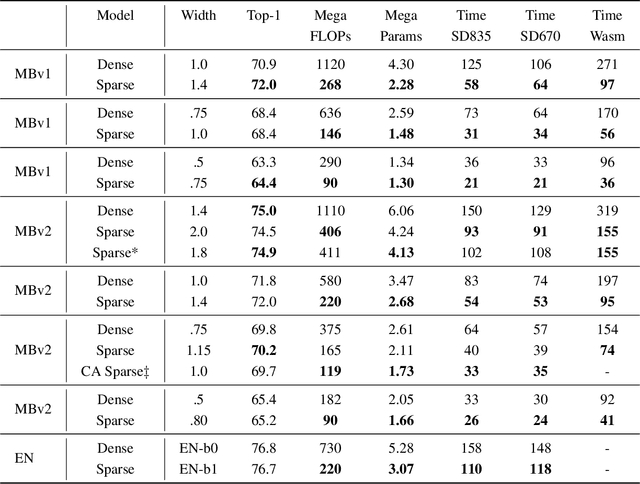
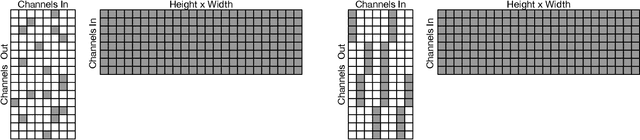

Historically, the pursuit of efficient inference has been one of the driving forces behind research into new deep learning architectures and building blocks. Some recent examples include: the squeeze-and-excitation module, depthwise separable convolutions in Xception, and the inverted bottleneck in MobileNet v2. Notably, in all of these cases, the resulting building blocks enabled not only higher efficiency, but also higher accuracy, and found wide adoption in the field. In this work, we further expand the arsenal of efficient building blocks for neural network architectures; but instead of combining standard primitives (such as convolution), we advocate for the replacement of these dense primitives with their sparse counterparts. While the idea of using sparsity to decrease the parameter count is not new, the conventional wisdom is that this reduction in theoretical FLOPs does not translate into real-world efficiency gains. We aim to correct this misconception by introducing a family of efficient sparse kernels for ARM and WebAssembly, which we open-source for the benefit of the community as part of the XNNPACK library. Equipped with our efficient implementation of sparse primitives, we show that sparse versions of MobileNet v1, MobileNet v2 and EfficientNet architectures substantially outperform strong dense baselines on the efficiency-accuracy curve. On Snapdragon 835 our sparse networks outperform their dense equivalents by $1.3-2.4\times$ -- equivalent to approximately one entire generation of MobileNet-family improvement. We hope that our findings will facilitate wider adoption of sparsity as a tool for creating efficient and accurate deep learning architectures.
The Indirect Convolution Algorithm
Jul 03, 2019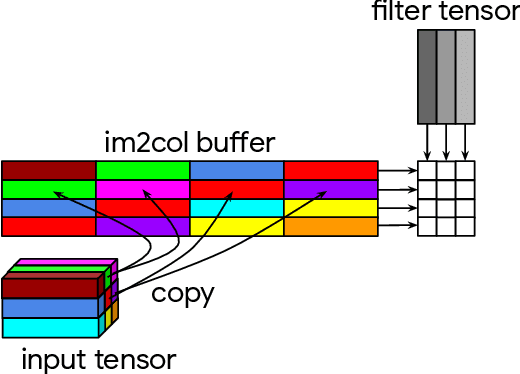
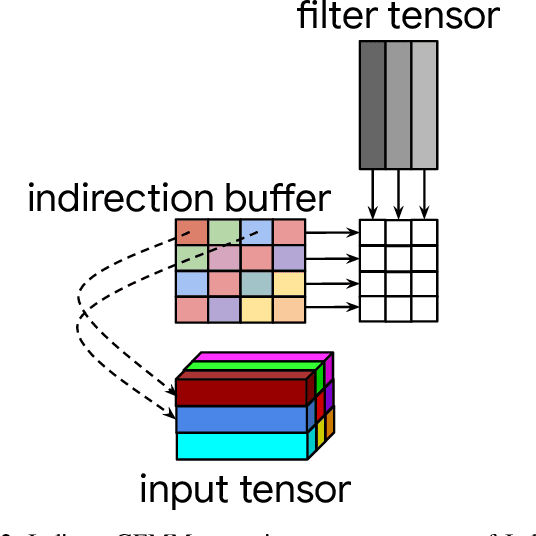

Deep learning frameworks commonly implement convolution operators with GEMM-based algorithms. In these algorithms, convolution is implemented on top of matrix-matrix multiplication (GEMM) functions, provided by highly optimized BLAS libraries. Convolutions with 1x1 kernels can be directly represented as a GEMM call, but convolutions with larger kernels require a special memory layout transformation - im2col or im2row - to fit into GEMM interface. The Indirect Convolution algorithm provides the efficiency of the GEMM primitive without the overhead of im2col transformation. In contrast to GEMM-based algorithms, the Indirect Convolution does not reshuffle the data to fit into the GEMM primitive but introduces an indirection buffer - a buffer of pointers to the start of each row of image pixels. This broadens the application of our modified GEMM function to convolutions with arbitrary kernel size, padding, stride, and dilation. The Indirect Convolution algorithm reduces memory overhead proportionally to the number of input channels and outperforms the GEMM-based algorithm by up to 62% on convolution parameters which involve im2col transformations in GEMM-based algorithms. This, however, comes at cost of minor performance reduction on 1x1 stride-1 convolutions.
ChamNet: Towards Efficient Network Design through Platform-Aware Model Adaptation
Dec 21, 2018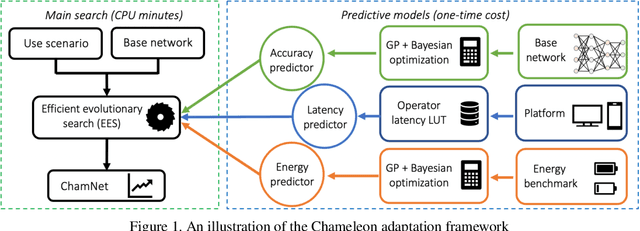
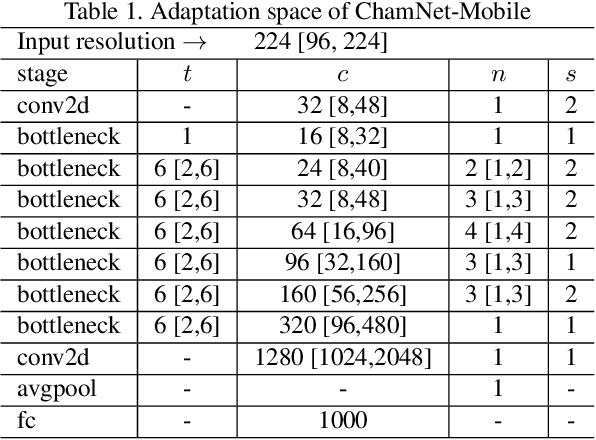
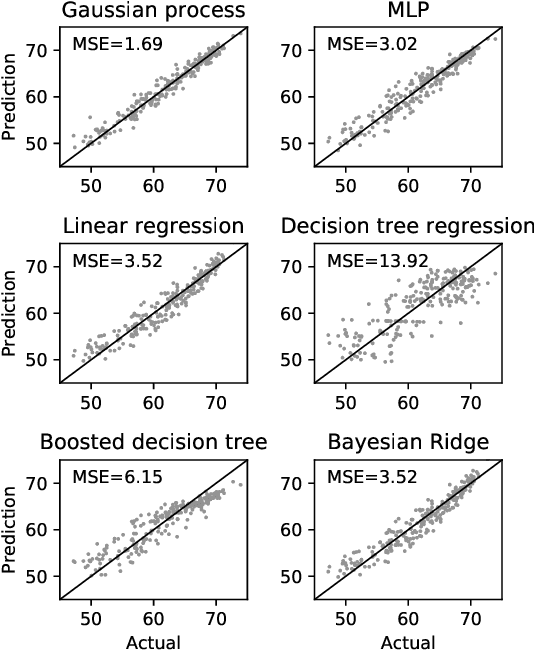
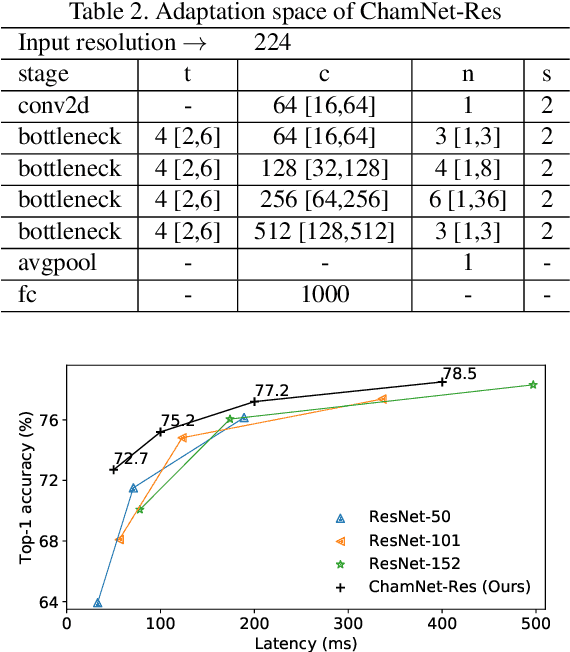
This paper proposes an efficient neural network (NN) architecture design methodology called Chameleon that honors given resource constraints. Instead of developing new building blocks or using computationally-intensive reinforcement learning algorithms, our approach leverages existing efficient network building blocks and focuses on exploiting hardware traits and adapting computation resources to fit target latency and/or energy constraints. We formulate platform-aware NN architecture search in an optimization framework and propose a novel algorithm to search for optimal architectures aided by efficient accuracy and resource (latency and/or energy) predictors. At the core of our algorithm lies an accuracy predictor built atop Gaussian Process with Bayesian optimization for iterative sampling. With a one-time building cost for the predictors, our algorithm produces state-of-the-art model architectures on different platforms under given constraints in just minutes. Our results show that adapting computation resources to building blocks is critical to model performance. Without the addition of any bells and whistles, our models achieve significant accuracy improvements against state-of-the-art hand-crafted and automatically designed architectures. We achieve 73.8% and 75.3% top-1 accuracy on ImageNet at 20ms latency on a mobile CPU and DSP. At reduced latency, our models achieve up to 8.5% (4.8%) and 6.6% (9.3%) absolute top-1 accuracy improvements compared to MobileNetV2 and MnasNet, respectively, on a mobile CPU (DSP), and 2.7% (4.6%) and 5.6% (2.6%) accuracy gains over ResNet-101 and ResNet-152, respectively, on an Nvidia GPU (Intel CPU).