 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUAV-DETR: DETR for Anti-Drone Target Detection
Mar 24, 2026Drone detection is pivotal in numerous security and counter-UAV applications. However, existing deep learning-based methods typically struggle to balance robust feature representation with computational efficiency. This challenge is particularly acute when detecting miniature drones against complex backgrounds under severe environmental interference. To address these issues, we introduce UAV-DETR, a novel framework that integrates a small-target-friendly architecture with real-time detection capabilities. Specifically, UAV-DETR features a WTConv-enhanced backbone and a Sliding Window Self-Attention (SWSA-IFI) encoder, capturing the high-frequency structural details of tiny targets while drastically reducing parameter overhead. Furthermore, we propose an Efficient Cross-Scale Feature Recalibration and Fusion Network (ECFRFN) to suppress background noise and aggregate multi-scale semantics. To further enhance accuracy, UAV-DETR incorporates a hybrid Inner-CIoU and NWD loss strategy, mitigating the extreme sensitivity of standard IoU metrics to minor positional deviations in small objects. Extensive experiments demonstrate that UAV-DETR significantly outperforms the baseline RT-DETR on our custom UAV dataset (+6.61% in mAP50:95, with a 39.8% reduction in parameters) and the public DUT-ANTI-UAV benchmark (+1.4% in Precision, +1.0% in F1-Score). These results establish UAV-DETR as a superior trade-off between efficiency and precision in counter-UAV object detection. The code is available at https://github.com/wd-sir/UAVDETR.
Attend Before Attention: Efficient and Scalable Video Understanding via Autoregressive Gazing
Mar 12, 2026Multi-modal large language models (MLLMs) have advanced general-purpose video understanding but struggle with long, high-resolution videos -- they process every pixel equally in their vision transformers (ViTs) or LLMs despite significant spatiotemporal redundancy. We introduce AutoGaze, a lightweight module that removes redundant patches before processed by a ViT or an MLLM. Trained with next-token prediction and reinforcement learning, AutoGaze autoregressively selects a minimal set of multi-scale patches that can reconstruct the video within a user-specified error threshold, eliminating redundancy while preserving information. Empirically, AutoGaze reduces visual tokens by 4x-100x and accelerates ViTs and MLLMs by up to 19x, enabling scaling MLLMs to 1K-frame 4K-resolution videos and achieving superior results on video benchmarks (e.g., 67.0% on VideoMME). Furthermore, we introduce HLVid: the first high-resolution, long-form video QA benchmark with 5-minute 4K-resolution videos, where an MLLM scaled with AutoGaze improves over the baseline by 10.1% and outperforms the previous best MLLM by 4.5%. Project page: https://autogaze.github.io/.
FoundationMotion: Auto-Labeling and Reasoning about Spatial Movement in Videos
Dec 11, 2025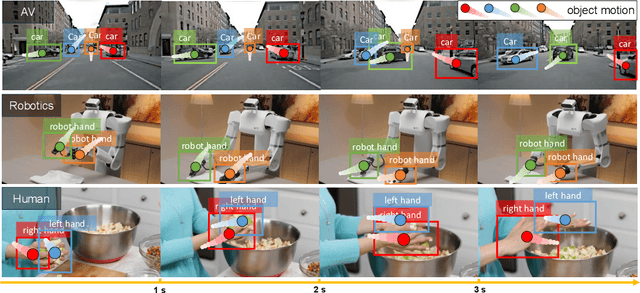
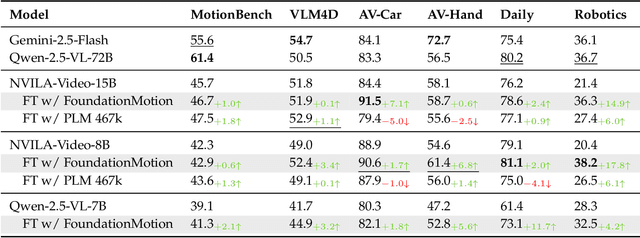
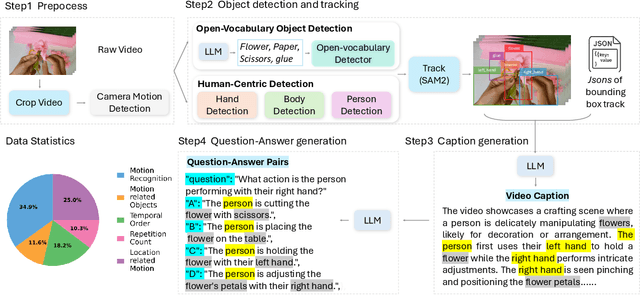

Motion understanding is fundamental to physical reasoning, enabling models to infer dynamics and predict future states. However, state-of-the-art models still struggle on recent motion benchmarks, primarily due to the scarcity of large-scale, fine-grained motion datasets. Existing motion datasets are often constructed from costly manual annotation, severely limiting scalability. To address this challenge, we introduce FoundationMotion, a fully automated data curation pipeline that constructs large-scale motion datasets. Our approach first detects and tracks objects in videos to extract their trajectories, then leverages these trajectories and video frames with Large Language Models (LLMs) to generate fine-grained captions and diverse question-answer pairs about motion and spatial reasoning. Using datasets produced by this pipeline, we fine-tune open-source models including NVILA-Video-15B and Qwen2.5-7B, achieving substantial improvements in motion understanding without compromising performance on other tasks. Notably, our models outperform strong closed-source baselines like Gemini-2.5 Flash and large open-source models such as Qwen2.5-VL-72B across diverse motion understanding datasets and benchmarks. FoundationMotion thus provides a scalable solution for curating fine-grained motion datasets that enable effective fine-tuning of diverse models to enhance motion understanding and spatial reasoning capabilities.
NVIDIA Nemotron Nano V2 VL
Nov 07, 2025We introduce Nemotron Nano V2 VL, the latest model of the Nemotron vision-language series designed for strong real-world document understanding, long video comprehension, and reasoning tasks. Nemotron Nano V2 VL delivers significant improvements over our previous model, Llama-3.1-Nemotron-Nano-VL-8B, across all vision and text domains through major enhancements in model architecture, datasets, and training recipes. Nemotron Nano V2 VL builds on Nemotron Nano V2, a hybrid Mamba-Transformer LLM, and innovative token reduction techniques to achieve higher inference throughput in long document and video scenarios. We are releasing model checkpoints in BF16, FP8, and FP4 formats and sharing large parts of our datasets, recipes and training code.
3D Aware Region Prompted Vision Language Model
Sep 16, 2025



We present Spatial Region 3D (SR-3D) aware vision-language model that connects single-view 2D images and multi-view 3D data through a shared visual token space. SR-3D supports flexible region prompting, allowing users to annotate regions with bounding boxes, segmentation masks on any frame, or directly in 3D, without the need for exhaustive multi-frame labeling. We achieve this by enriching 2D visual features with 3D positional embeddings, which allows the 3D model to draw upon strong 2D priors for more accurate spatial reasoning across frames, even when objects of interest do not co-occur within the same view. Extensive experiments on both general 2D vision language and specialized 3D spatial benchmarks demonstrate that SR-3D achieves state-of-the-art performance, underscoring its effectiveness for unifying 2D and 3D representation space on scene understanding. Moreover, we observe applicability to in-the-wild videos without sensory 3D inputs or ground-truth 3D annotations, where SR-3D accurately infers spatial relationships and metric measurements.
Test-Time Scaling Strategies for Generative Retrieval in Multimodal Conversational Recommendations
Aug 25, 2025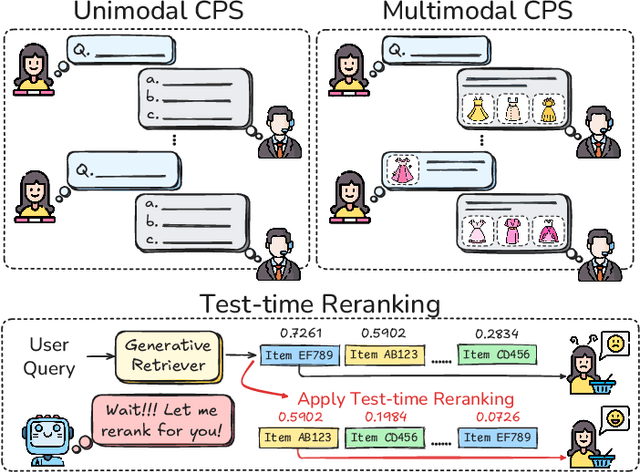
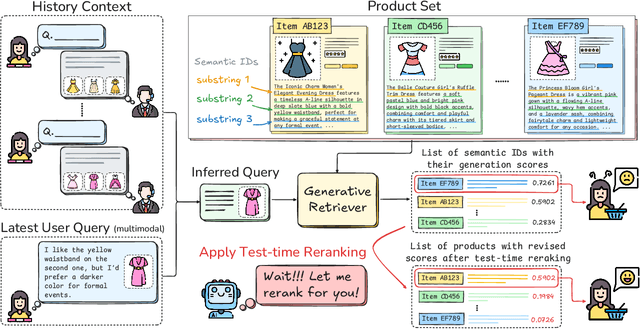
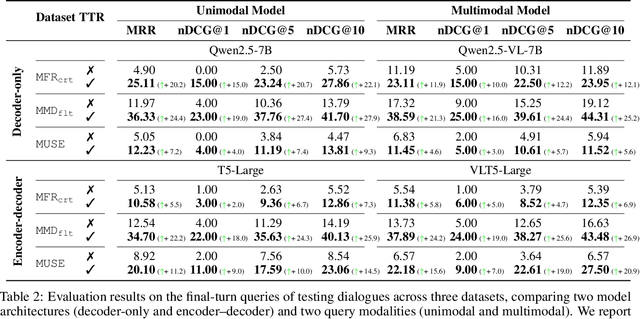
The rapid evolution of e-commerce has exposed the limitations of traditional product retrieval systems in managing complex, multi-turn user interactions. Recent advances in multimodal generative retrieval -- particularly those leveraging multimodal large language models (MLLMs) as retrievers -- have shown promise. However, most existing methods are tailored to single-turn scenarios and struggle to model the evolving intent and iterative nature of multi-turn dialogues when applied naively. Concurrently, test-time scaling has emerged as a powerful paradigm for improving large language model (LLM) performance through iterative inference-time refinement. Yet, its effectiveness typically relies on two conditions: (1) a well-defined problem space (e.g., mathematical reasoning), and (2) the model's ability to self-correct -- conditions that are rarely met in conversational product search. In this setting, user queries are often ambiguous and evolving, and MLLMs alone have difficulty grounding responses in a fixed product corpus. Motivated by these challenges, we propose a novel framework that introduces test-time scaling into conversational multimodal product retrieval. Our approach builds on a generative retriever, further augmented with a test-time reranking (TTR) mechanism that improves retrieval accuracy and better aligns results with evolving user intent throughout the dialogue. Experiments across multiple benchmarks show consistent improvements, with average gains of 14.5 points in MRR and 10.6 points in nDCG@1.
EgoVLA: Learning Vision-Language-Action Models from Egocentric Human Videos
Jul 16, 2025Real robot data collection for imitation learning has led to significant advancements in robotic manipulation. However, the requirement for robot hardware in the process fundamentally constrains the scale of the data. In this paper, we explore training Vision-Language-Action (VLA) models using egocentric human videos. The benefit of using human videos is not only for their scale but more importantly for the richness of scenes and tasks. With a VLA trained on human video that predicts human wrist and hand actions, we can perform Inverse Kinematics and retargeting to convert the human actions to robot actions. We fine-tune the model using a few robot manipulation demonstrations to obtain the robot policy, namely EgoVLA. We propose a simulation benchmark called Isaac Humanoid Manipulation Benchmark, where we design diverse bimanual manipulation tasks with demonstrations. We fine-tune and evaluate EgoVLA with Isaac Humanoid Manipulation Benchmark and show significant improvements over baselines and ablate the importance of human data. Videos can be found on our website: https://rchalyang.github.io/EgoVLA
Scaling RL to Long Videos
Jul 10, 2025We introduce a full-stack framework that scales up reasoning in vision-language models (VLMs) to long videos, leveraging reinforcement learning. We address the unique challenges of long video reasoning by integrating three critical components: (1) a large-scale dataset, LongVideo-Reason, comprising 52K long video QA pairs with high-quality reasoning annotations across diverse domains such as sports, games, and vlogs; (2) a two-stage training pipeline that extends VLMs with chain-of-thought supervised fine-tuning (CoT-SFT) and reinforcement learning (RL); and (3) a training infrastructure for long video RL, named Multi-modal Reinforcement Sequence Parallelism (MR-SP), which incorporates sequence parallelism and a vLLM-based engine tailored for long video, using cached video embeddings for efficient rollout and prefilling. In experiments, LongVILA-R1-7B achieves strong performance on long video QA benchmarks such as VideoMME. It also outperforms Video-R1-7B and even matches Gemini-1.5-Pro across temporal reasoning, goal and purpose reasoning, spatial reasoning, and plot reasoning on our LongVideo-Reason-eval benchmark. Notably, our MR-SP system achieves up to 2.1x speedup on long video RL training. LongVILA-R1 demonstrates consistent performance gains as the number of input video frames scales. LongVILA-R1 marks a firm step towards long video reasoning in VLMs. In addition, we release our training system for public availability that supports RL training on various modalities (video, text, and audio), various models (VILA and Qwen series), and even image and video generation models. On a single A100 node (8 GPUs), it supports RL training on hour-long videos (e.g., 3,600 frames / around 256k tokens).
CLIMB: CLustering-based Iterative Data Mixture Bootstrapping for Language Model Pre-training
Apr 17, 2025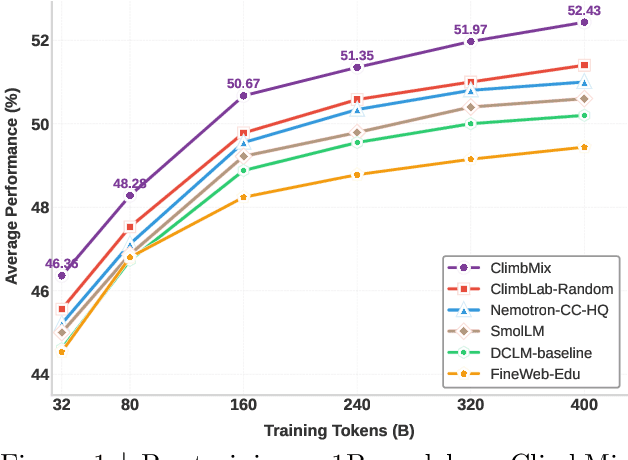
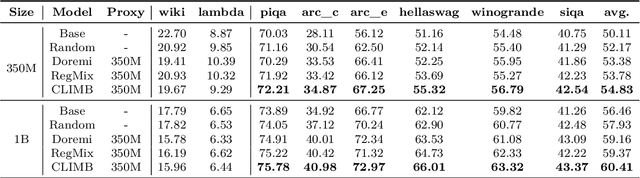
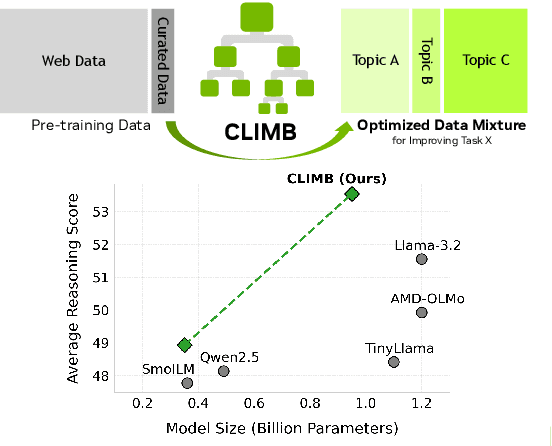
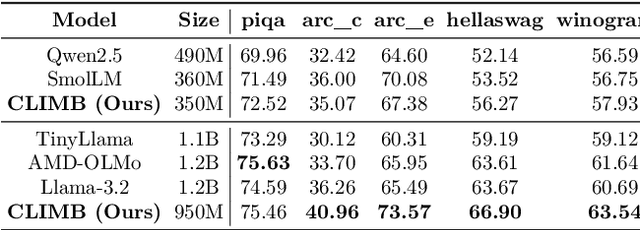
Pre-training datasets are typically collected from web content and lack inherent domain divisions. For instance, widely used datasets like Common Crawl do not include explicit domain labels, while manually curating labeled datasets such as The Pile is labor-intensive. Consequently, identifying an optimal pre-training data mixture remains a challenging problem, despite its significant benefits for pre-training performance. To address these challenges, we propose CLustering-based Iterative Data Mixture Bootstrapping (CLIMB), an automated framework that discovers, evaluates, and refines data mixtures in a pre-training setting. Specifically, CLIMB embeds and clusters large-scale datasets in a semantic space and then iteratively searches for optimal mixtures using a smaller proxy model and a predictor. When continuously trained on 400B tokens with this mixture, our 1B model exceeds the state-of-the-art Llama-3.2-1B by 2.0%. Moreover, we observe that optimizing for a specific domain (e.g., Social Sciences) yields a 5% improvement over random sampling. Finally, we introduce ClimbLab, a filtered 1.2-trillion-token corpus with 20 clusters as a research playground, and ClimbMix, a compact yet powerful 400-billion-token dataset designed for efficient pre-training that delivers superior performance under an equal token budget. We analyze the final data mixture, elucidating the characteristics of an optimal data mixture. Our data is available at: https://research.nvidia.com/labs/lpr/climb/
Scaling Vision Pre-Training to 4K Resolution
Mar 25, 2025High-resolution perception of visual details is crucial for daily tasks. Current vision pre-training, however, is still limited to low resolutions (e.g., 378 x 378 pixels) due to the quadratic cost of processing larger images. We introduce PS3 that scales CLIP-style vision pre-training to 4K resolution with a near-constant cost. Instead of contrastive learning on global image representation, PS3 is pre-trained by selectively processing local regions and contrasting them with local detailed captions, enabling high-resolution representation learning with greatly reduced computational overhead. The pre-trained PS3 is able to both encode the global image at low resolution and selectively process local high-resolution regions based on their saliency or relevance to a text prompt. When applying PS3 to multi-modal LLM (MLLM), the resulting model, named VILA-HD, significantly improves high-resolution visual perception compared to baselines without high-resolution vision pre-training such as AnyRes and S^2 while using up to 4.3x fewer tokens. PS3 also unlocks appealing scaling properties of VILA-HD, including scaling up resolution for free and scaling up test-time compute for better performance. Compared to state of the arts, VILA-HD outperforms previous MLLMs such as NVILA and Qwen2-VL across multiple benchmarks and achieves better efficiency than latest token pruning approaches. Finally, we find current benchmarks do not require 4K-resolution perception, which motivates us to propose 4KPro, a new benchmark of image QA at 4K resolution, on which VILA-HD outperforms all previous MLLMs, including a 14.5% improvement over GPT-4o, and a 3.2% improvement and 2.96x speedup over Qwen2-VL.