 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenVision 3: A Family of Unified Visual Encoder for Both Understanding and Generation
Jan 21, 2026This paper presents a family of advanced vision encoder, named OpenVision 3, that learns a single, unified visual representation that can serve both image understanding and image generation. Our core architecture is simple: we feed VAE-compressed image latents to a ViT encoder and train its output to support two complementary roles. First, the encoder output is passed to the ViT-VAE decoder to reconstruct the original image, encouraging the representation to capture generative structure. Second, the same representation is optimized with contrastive learning and image-captioning objectives, strengthening semantic features. By jointly optimizing reconstruction- and semantics-driven signals in a shared latent space, the encoder learns representations that synergize and generalize well across both regimes. We validate this unified design through extensive downstream evaluations with the encoder frozen. For multimodal understanding, we plug the encoder into the LLaVA-1.5 framework: it performs comparably with a standard CLIP vision encoder (e.g., 62.4 vs 62.2 on SeedBench, and 83.7 vs 82.9 on POPE). For generation, we test it under the RAE framework: ours substantially surpasses the standard CLIP-based encoder (e.g., gFID: 1.89 vs 2.54 on ImageNet). We hope this work can spur future research on unified modeling.
NVIDIA Nemotron Nano V2 VL
Nov 07, 2025We introduce Nemotron Nano V2 VL, the latest model of the Nemotron vision-language series designed for strong real-world document understanding, long video comprehension, and reasoning tasks. Nemotron Nano V2 VL delivers significant improvements over our previous model, Llama-3.1-Nemotron-Nano-VL-8B, across all vision and text domains through major enhancements in model architecture, datasets, and training recipes. Nemotron Nano V2 VL builds on Nemotron Nano V2, a hybrid Mamba-Transformer LLM, and innovative token reduction techniques to achieve higher inference throughput in long document and video scenarios. We are releasing model checkpoints in BF16, FP8, and FP4 formats and sharing large parts of our datasets, recipes and training code.
Argus: Vision-Centric Reasoning with Grounded Chain-of-Thought
May 29, 2025Recent advances in multimodal large language models (MLLMs) have demonstrated remarkable capabilities in vision-language tasks, yet they often struggle with vision-centric scenarios where precise visual focus is needed for accurate reasoning. In this paper, we introduce Argus to address these limitations with a new visual attention grounding mechanism. Our approach employs object-centric grounding as visual chain-of-thought signals, enabling more effective goal-conditioned visual attention during multimodal reasoning tasks. Evaluations on diverse benchmarks demonstrate that Argus excels in both multimodal reasoning tasks and referring object grounding tasks. Extensive analysis further validates various design choices of Argus, and reveals the effectiveness of explicit language-guided visual region-of-interest engagement in MLLMs, highlighting the importance of advancing multimodal intelligence from a visual-centric perspective. Project page: https://yunzeman.github.io/argus/
Nemotron-Research-Tool-N1: Tool-Using Language Models with Reinforced Reasoning
Apr 25, 2025Enabling large language models with external tools has become a pivotal strategy for extending their functionality beyond text generation tasks. Prior work typically enhances tool-use abilities by either applying supervised fine-tuning (SFT) to enforce tool-call correctness or distilling reasoning traces from stronger models for SFT. However, both approaches fall short, either omitting reasoning entirely or producing imitative reasoning that limits generalization. Inspired by the success of DeepSeek-R1 in eliciting reasoning through rule-based reinforcement learning, we develop the Nemotron-Research-Tool-N1 series of tool-using language models using a similar training paradigm. Instead of restrictively supervising intermediate reasoning traces distilled from stronger models, Nemotron-Research-Tool-N1 is optimized with a binary reward that evaluates only the structural validity and functional correctness of tool invocations. This lightweight supervision allows the model to autonomously internalize reasoning strategies, without the need for annotated reasoning trajectories. Experiments on the BFCL and API-Bank benchmarks show that Nemotron-Research-Tool-N1-7B and Nemotron-Research-Tool-N1-14B, built on Qwen-2.5-7B/14B-Instruct, achieve state-of-the-art results, outperforming GPT-4o on both evaluations.
Eagle 2.5: Boosting Long-Context Post-Training for Frontier Vision-Language Models
Apr 21, 2025We introduce Eagle 2.5, a family of frontier vision-language models (VLMs) for long-context multimodal learning. Our work addresses the challenges in long video comprehension and high-resolution image understanding, introducing a generalist framework for both tasks. The proposed training framework incorporates Automatic Degrade Sampling and Image Area Preservation, two techniques that preserve contextual integrity and visual details. The framework also includes numerous efficiency optimizations in the pipeline for long-context data training. Finally, we propose Eagle-Video-110K, a novel dataset that integrates both story-level and clip-level annotations, facilitating long-video understanding. Eagle 2.5 demonstrates substantial improvements on long-context multimodal benchmarks, providing a robust solution to the limitations of existing VLMs. Notably, our best model Eagle 2.5-8B achieves 72.4% on Video-MME with 512 input frames, matching the results of top-tier commercial model such as GPT-4o and large-scale open-source models like Qwen2.5-VL-72B and InternVL2.5-78B.
Nemotron-H: A Family of Accurate and Efficient Hybrid Mamba-Transformer Models
Apr 10, 2025



As inference-time scaling becomes critical for enhanced reasoning capabilities, it is increasingly becoming important to build models that are efficient to infer. We introduce Nemotron-H, a family of 8B and 56B/47B hybrid Mamba-Transformer models designed to reduce inference cost for a given accuracy level. To achieve this goal, we replace the majority of self-attention layers in the common Transformer model architecture with Mamba layers that perform constant computation and require constant memory per generated token. We show that Nemotron-H models offer either better or on-par accuracy compared to other similarly-sized state-of-the-art open-sourced Transformer models (e.g., Qwen-2.5-7B/72B and Llama-3.1-8B/70B), while being up to 3$\times$ faster at inference. To further increase inference speed and reduce the memory required at inference time, we created Nemotron-H-47B-Base from the 56B model using a new compression via pruning and distillation technique called MiniPuzzle. Nemotron-H-47B-Base achieves similar accuracy to the 56B model, but is 20% faster to infer. In addition, we introduce an FP8-based training recipe and show that it can achieve on par results with BF16-based training. This recipe is used to train the 56B model. All Nemotron-H models will be released, with support in Hugging Face, NeMo, and Megatron-LM.
Slow-Fast Architecture for Video Multi-Modal Large Language Models
Apr 02, 2025Balancing temporal resolution and spatial detail under limited compute budget remains a key challenge for video-based multi-modal large language models (MLLMs). Existing methods typically compress video representations using predefined rules before feeding them into the LLM, resulting in irreversible information loss and often ignoring input instructions. To address this, we propose a novel slow-fast architecture that naturally circumvents this trade-off, enabling the use of more input frames while preserving spatial details. Inspired by how humans first skim a video before focusing on relevant parts, our slow-fast design employs a dual-token strategy: 1) "fast" visual tokens -- a compact set of compressed video features -- are fed into the LLM alongside text embeddings to provide a quick overview; 2) "slow" visual tokens -- uncompressed video features -- are cross-attended by text embeddings through specially designed hybrid decoder layers, enabling instruction-aware extraction of relevant visual details with linear complexity. We conduct systematic exploration to optimize both the overall architecture and key components. Experiments show that our model significantly outperforms self-attention-only baselines, extending the input capacity from 16 to 128 frames with just a 3% increase in computation, and achieving a 16% average performance improvement across five video understanding benchmarks. Our 7B model achieves state-of-the-art performance among models of similar size. Furthermore, our slow-fast architecture is a plug-and-play design that can be integrated into other video MLLMs to improve efficiency and scalability.
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
Mar 18, 2025General-purpose robots need a versatile body and an intelligent mind. Recent advancements in humanoid robots have shown great promise as a hardware platform for building generalist autonomy in the human world. A robot foundation model, trained on massive and diverse data sources, is essential for enabling the robots to reason about novel situations, robustly handle real-world variability, and rapidly learn new tasks. To this end, we introduce GR00T N1, an open foundation model for humanoid robots. GR00T N1 is a Vision-Language-Action (VLA) model with a dual-system architecture. The vision-language module (System 2) interprets the environment through vision and language instructions. The subsequent diffusion transformer module (System 1) generates fluid motor actions in real time. Both modules are tightly coupled and jointly trained end-to-end. We train GR00T N1 with a heterogeneous mixture of real-robot trajectories, human videos, and synthetically generated datasets. We show that our generalist robot model GR00T N1 outperforms the state-of-the-art imitation learning baselines on standard simulation benchmarks across multiple robot embodiments. Furthermore, we deploy our model on the Fourier GR-1 humanoid robot for language-conditioned bimanual manipulation tasks, achieving strong performance with high data efficiency.
Token-Efficient Long Video Understanding for Multimodal LLMs
Mar 06, 2025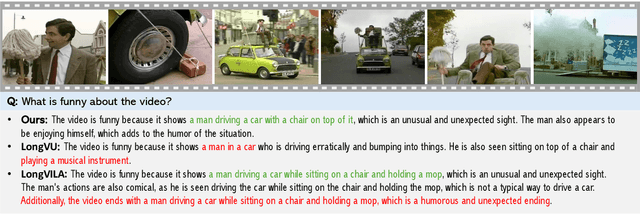
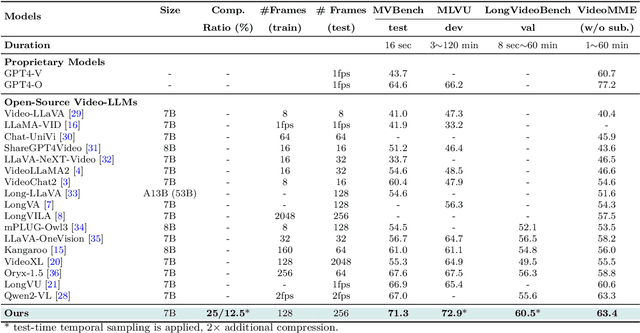
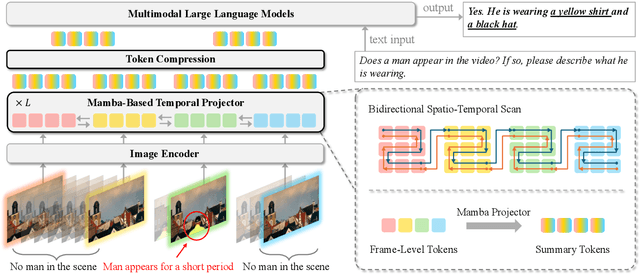
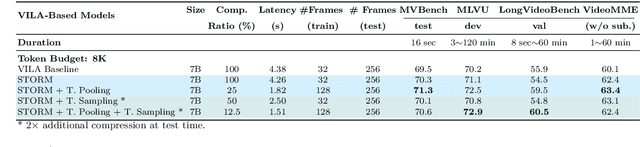
Recent advances in video-based multimodal large language models (Video-LLMs) have significantly improved video understanding by processing videos as sequences of image frames. However, many existing methods treat frames independently in the vision backbone, lacking explicit temporal modeling, which limits their ability to capture dynamic patterns and efficiently handle long videos. To address these limitations, we introduce STORM (\textbf{S}patiotemporal \textbf{TO}ken \textbf{R}eduction for \textbf{M}ultimodal LLMs), a novel architecture incorporating a dedicated temporal encoder between the image encoder and the LLM. Our temporal encoder leverages the Mamba State Space Model to integrate temporal information into image tokens, generating enriched representations that preserve inter-frame dynamics across the entire video sequence. This enriched encoding not only enhances video reasoning capabilities but also enables effective token reduction strategies, including test-time sampling and training-based temporal and spatial pooling, substantially reducing computational demands on the LLM without sacrificing key temporal information. By integrating these techniques, our approach simultaneously reduces training and inference latency while improving performance, enabling efficient and robust video understanding over extended temporal contexts. Extensive evaluations show that STORM achieves state-of-the-art results across various long video understanding benchmarks (more than 5\% improvement on MLVU and LongVideoBench) while reducing the computation costs by up to $8\times$ and the decoding latency by 2.4-2.9$\times$ for the fixed numbers of input frames. Project page is available at https://research.nvidia.com/labs/lpr/storm
AIDE: Agentically Improve Visual Language Model with Domain Experts
Feb 13, 2025



The enhancement of Visual Language Models (VLMs) has traditionally relied on knowledge distillation from larger, more capable models. This dependence creates a fundamental bottleneck for improving state-of-the-art systems, particularly when no superior models exist. We introduce AIDE (Agentic Improvement through Domain Experts), a novel framework that enables VLMs to autonomously enhance their capabilities by leveraging specialized domain expert models. AIDE operates through a four-stage process: (1) identifying instances for refinement, (2) engaging domain experts for targeted analysis, (3) synthesizing expert outputs with existing data, and (4) integrating enhanced instances into the training pipeline. Experiments on multiple benchmarks, including MMMU, MME, MMBench, etc., demonstrate AIDE's ability to achieve notable performance gains without relying on larger VLMs nor human supervision. Our framework provides a scalable, resource-efficient approach to continuous VLM improvement, addressing critical limitations in current methodologies, particularly valuable when larger models are unavailable to access.