 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D-Layout-R1: Structured Reasoning for Language-Instructed Spatial Editing
Mar 23, 2026Large Language Models (LLMs) and Vision Language Models (VLMs) have shown impressive reasoning abilities, yet they struggle with spatial understanding and layout consistency when performing fine-grained visual editing. We introduce a Structured Reasoning framework that performs text-conditioned spatial layout editing via scene-graph reasoning. Given an input scene graph and a natural-language instruction, the model reasons over the graph to generate an updated scene graph that satisfies the text condition while maintaining spatial coherence. By explicitly guiding the reasoning process through structured relational representations, our approach improves both interpretability and control over spatial relationships. We evaluate our method on a new text-guided layout editing benchmark encompassing sorting, spatial alignment, and room-editing tasks. Our training paradigm yields an average 15% improvement in IoU and 25% reduction in center-distance error compared to Chain of Thought Fine-tuning (CoT-SFT) and vanilla GRPO baselines. Compared to SOTA zero-shot LLMs, our best models achieve up to 20% higher mIoU, demonstrating markedly improved spatial precision.
4D-RGPT: Toward Region-level 4D Understanding via Perceptual Distillation
Dec 22, 2025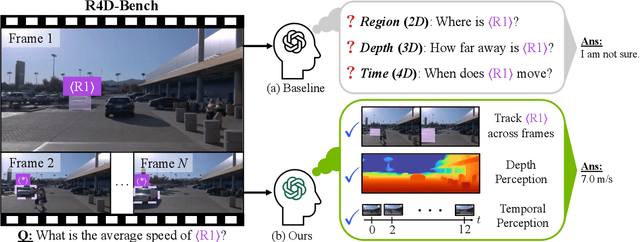

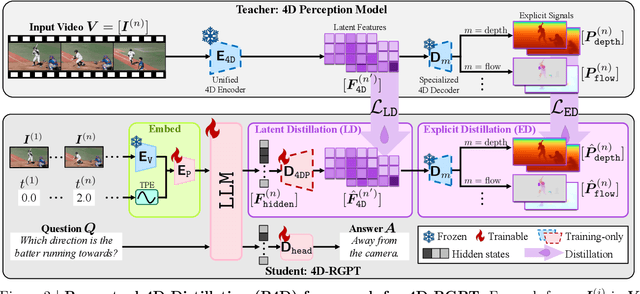
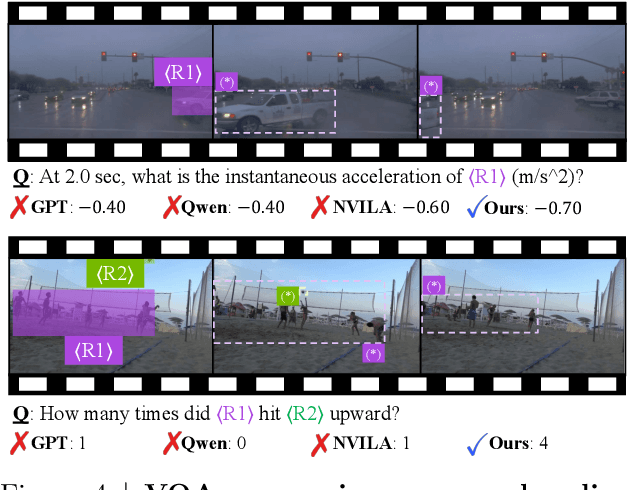
Despite advances in Multimodal LLMs (MLLMs), their ability to reason over 3D structures and temporal dynamics remains limited, constrained by weak 4D perception and temporal understanding. Existing 3D and 4D Video Question Answering (VQA) benchmarks also emphasize static scenes and lack region-level prompting. We tackle these issues by introducing: (a) 4D-RGPT, a specialized MLLM designed to capture 4D representations from video inputs with enhanced temporal perception; (b) Perceptual 4D Distillation (P4D), a training framework that transfers 4D representations from a frozen expert model into 4D-RGPT for comprehensive 4D perception; and (c) R4D-Bench, a benchmark for depth-aware dynamic scenes with region-level prompting, built via a hybrid automated and human-verified pipeline. Our 4D-RGPT achieves notable improvements on both existing 4D VQA benchmarks and the proposed R4D-Bench benchmark.
NVIDIA Nemotron Nano V2 VL
Nov 07, 2025We introduce Nemotron Nano V2 VL, the latest model of the Nemotron vision-language series designed for strong real-world document understanding, long video comprehension, and reasoning tasks. Nemotron Nano V2 VL delivers significant improvements over our previous model, Llama-3.1-Nemotron-Nano-VL-8B, across all vision and text domains through major enhancements in model architecture, datasets, and training recipes. Nemotron Nano V2 VL builds on Nemotron Nano V2, a hybrid Mamba-Transformer LLM, and innovative token reduction techniques to achieve higher inference throughput in long document and video scenarios. We are releasing model checkpoints in BF16, FP8, and FP4 formats and sharing large parts of our datasets, recipes and training code.
3D Aware Region Prompted Vision Language Model
Sep 16, 2025



We present Spatial Region 3D (SR-3D) aware vision-language model that connects single-view 2D images and multi-view 3D data through a shared visual token space. SR-3D supports flexible region prompting, allowing users to annotate regions with bounding boxes, segmentation masks on any frame, or directly in 3D, without the need for exhaustive multi-frame labeling. We achieve this by enriching 2D visual features with 3D positional embeddings, which allows the 3D model to draw upon strong 2D priors for more accurate spatial reasoning across frames, even when objects of interest do not co-occur within the same view. Extensive experiments on both general 2D vision language and specialized 3D spatial benchmarks demonstrate that SR-3D achieves state-of-the-art performance, underscoring its effectiveness for unifying 2D and 3D representation space on scene understanding. Moreover, we observe applicability to in-the-wild videos without sensory 3D inputs or ground-truth 3D annotations, where SR-3D accurately infers spatial relationships and metric measurements.
FRAG: Frame Selection Augmented Generation for Long Video and Long Document Understanding
Apr 24, 2025



There has been impressive progress in Large Multimodal Models (LMMs). Recent works extend these models to long inputs, including multi-page documents and long videos. However, the model size and performance of these long context models are still limited due to the computational cost in both training and inference. In this work, we explore an orthogonal direction and process long inputs without long context LMMs. We propose Frame Selection Augmented Generation (FRAG), where the model first selects relevant frames within the input, and then only generates the final outputs based on the selected frames. The core of the selection process is done by scoring each frame independently, which does not require long context processing. The frames with the highest scores are then selected by a simple Top-K selection. We show that this frustratingly simple framework is applicable to both long videos and multi-page documents using existing LMMs without any fine-tuning. We consider two models, LLaVA-OneVision and InternVL2, in our experiments and show that FRAG consistently improves the performance and achieves state-of-the-art performances for both long video and long document understanding. For videos, FRAG substantially improves InternVL2-76B by 5.8% on MLVU and 3.7% on Video-MME. For documents, FRAG achieves over 20% improvements on MP-DocVQA compared with recent LMMs specialized in long document understanding. Code is available at: https://github.com/NVlabs/FRAG
Omni-RGPT: Unifying Image and Video Region-level Understanding via Token Marks
Jan 14, 2025We present Omni-RGPT, a multimodal large language model designed to facilitate region-level comprehension for both images and videos. To achieve consistent region representation across spatio-temporal dimensions, we introduce Token Mark, a set of tokens highlighting the target regions within the visual feature space. These tokens are directly embedded into spatial regions using region prompts (e.g., boxes or masks) and simultaneously incorporated into the text prompt to specify the target, establishing a direct connection between visual and text tokens. To further support robust video understanding without requiring tracklets, we introduce an auxiliary task that guides Token Mark by leveraging the consistency of the tokens, enabling stable region interpretation across the video. Additionally, we introduce a large-scale region-level video instruction dataset (RegVID-300k). Omni-RGPT achieves state-of-the-art results on image and video-based commonsense reasoning benchmarks while showing strong performance in captioning and referring expression comprehension tasks.
Eagle: Exploring The Design Space for Multimodal LLMs with Mixture of Encoders
Aug 28, 2024



The ability to accurately interpret complex visual information is a crucial topic of multimodal large language models (MLLMs). Recent work indicates that enhanced visual perception significantly reduces hallucinations and improves performance on resolution-sensitive tasks, such as optical character recognition and document analysis. A number of recent MLLMs achieve this goal using a mixture of vision encoders. Despite their success, there is a lack of systematic comparisons and detailed ablation studies addressing critical aspects, such as expert selection and the integration of multiple vision experts. This study provides an extensive exploration of the design space for MLLMs using a mixture of vision encoders and resolutions. Our findings reveal several underlying principles common to various existing strategies, leading to a streamlined yet effective design approach. We discover that simply concatenating visual tokens from a set of complementary vision encoders is as effective as more complex mixing architectures or strategies. We additionally introduce Pre-Alignment to bridge the gap between vision-focused encoders and language tokens, enhancing model coherence. The resulting family of MLLMs, Eagle, surpasses other leading open-source models on major MLLM benchmarks. Models and code: https://github.com/NVlabs/Eagle
What is Point Supervision Worth in Video Instance Segmentation?
Apr 01, 2024



Video instance segmentation (VIS) is a challenging vision task that aims to detect, segment, and track objects in videos. Conventional VIS methods rely on densely-annotated object masks which are expensive. We reduce the human annotations to only one point for each object in a video frame during training, and obtain high-quality mask predictions close to fully supervised models. Our proposed training method consists of a class-agnostic proposal generation module to provide rich negative samples and a spatio-temporal point-based matcher to match the object queries with the provided point annotations. Comprehensive experiments on three VIS benchmarks demonstrate competitive performance of the proposed framework, nearly matching fully supervised methods.
LITA: Language Instructed Temporal-Localization Assistant
Mar 27, 2024
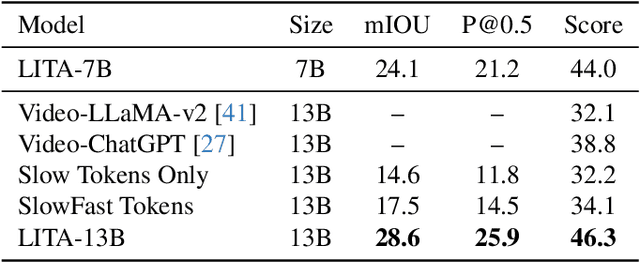
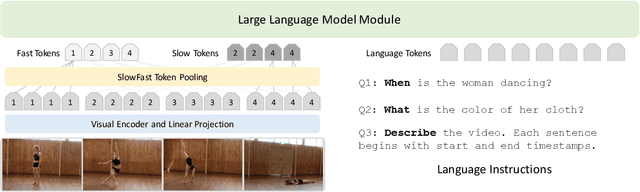
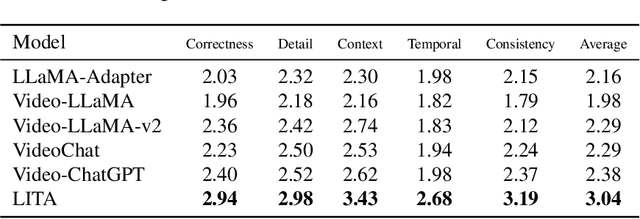
There has been tremendous progress in multimodal Large Language Models (LLMs). Recent works have extended these models to video input with promising instruction following capabilities. However, an important missing piece is temporal localization. These models cannot accurately answer the "When?" questions. We identify three key aspects that limit their temporal localization capabilities: (i) time representation, (ii) architecture, and (iii) data. We address these shortcomings by proposing Language Instructed Temporal-Localization Assistant (LITA) with the following features: (1) We introduce time tokens that encode timestamps relative to the video length to better represent time in videos. (2) We introduce SlowFast tokens in the architecture to capture temporal information at fine temporal resolution. (3) We emphasize temporal localization data for LITA. In addition to leveraging existing video datasets with timestamps, we propose a new task, Reasoning Temporal Localization (RTL), along with the dataset, ActivityNet-RTL, for learning and evaluating this task. Reasoning temporal localization requires both the reasoning and temporal localization of Video LLMs. LITA demonstrates strong performance on this challenging task, nearly doubling the temporal mean intersection-over-union (mIoU) of baselines. In addition, we show that our emphasis on temporal localization also substantially improves video-based text generation compared to existing Video LLMs, including a 36% relative improvement of Temporal Understanding. Code is available at: https://github.com/NVlabs/LITA
DiscoBox: Weakly Supervised Instance Segmentation and Semantic Correspondence from Box Supervision
Jun 05, 2021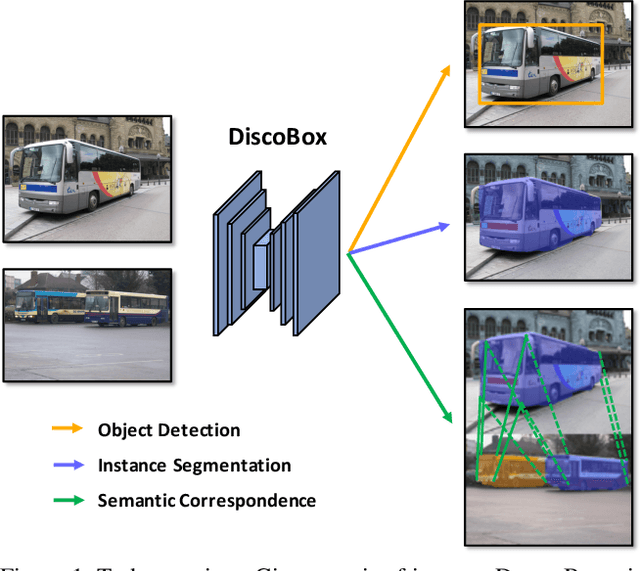
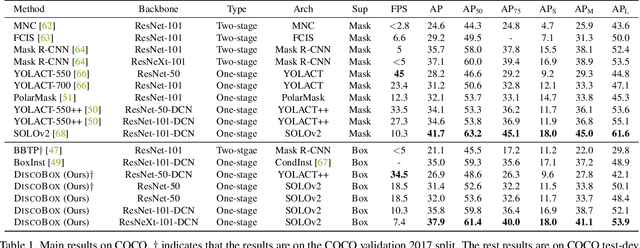
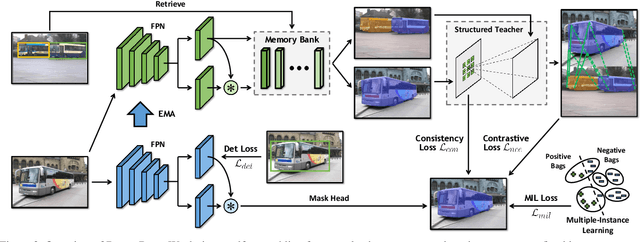
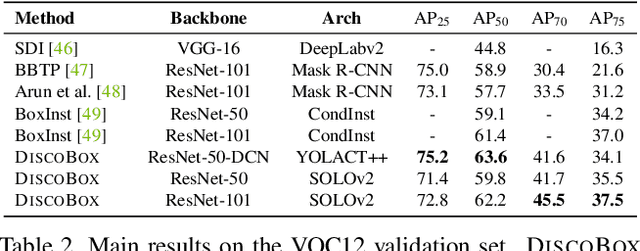
We introduce DiscoBox, a novel framework that jointly learns instance segmentation and semantic correspondence using bounding box supervision. Specifically, we propose a self-ensembling framework where instance segmentation and semantic correspondence are jointly guided by a structured teacher in addition to the bounding box supervision. The teacher is a structured energy model incorporating a pairwise potential and a cross-image potential to model the pairwise pixel relationships both within and across the boxes. Minimizing the teacher energy simultaneously yields refined object masks and dense correspondences between intra-class objects, which are taken as pseudo-labels to supervise the task network and provide positive/negative correspondence pairs for dense constrastive learning. We show a symbiotic relationship where the two tasks mutually benefit from each other. Our best model achieves 37.9% AP on COCO instance segmentation, surpassing prior weakly supervised methods and is competitive to supervised methods. We also obtain state of the art weakly supervised results on PASCAL VOC12 and PF-PASCAL with real-time inference.