 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the design space of deep-learning-based weather forecasting systems
Oct 09, 2024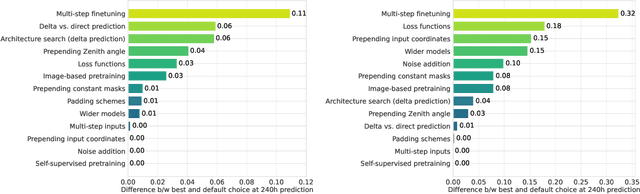

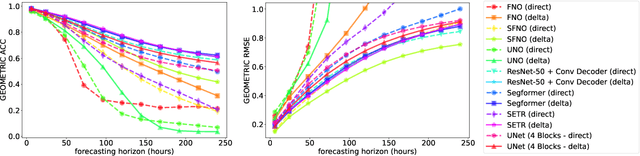
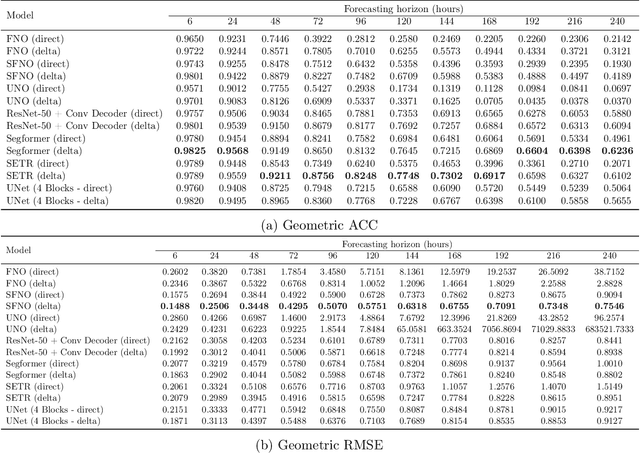
Despite tremendous progress in developing deep-learning-based weather forecasting systems, their design space, including the impact of different design choices, is yet to be well understood. This paper aims to fill this knowledge gap by systematically analyzing these choices including architecture, problem formulation, pretraining scheme, use of image-based pretrained models, loss functions, noise injection, multi-step inputs, additional static masks, multi-step finetuning (including larger stride models), as well as training on a larger dataset. We study fixed-grid architectures such as UNet, fully convolutional architectures, and transformer-based models, along with grid-invariant architectures, including graph-based and operator-based models. Our results show that fixed-grid architectures outperform grid-invariant architectures, indicating a need for further architectural developments in grid-invariant models such as neural operators. We therefore propose a hybrid system that combines the strong performance of fixed-grid models with the flexibility of grid-invariant architectures. We further show that multi-step fine-tuning is essential for most deep-learning models to work well in practice, which has been a common practice in the past. Pretraining objectives degrade performance in comparison to supervised training, while image-based pretrained models provide useful inductive biases in some cases in comparison to training the model from scratch. Interestingly, we see a strong positive effect of using a larger dataset when training a smaller model as compared to training on a smaller dataset for longer. Larger models, on the other hand, primarily benefit from just an increase in the computational budget. We believe that these results will aid in the design of better weather forecasting systems in the future.
VoxFormer: Sparse Voxel Transformer for Camera-based 3D Semantic Scene Completion
Feb 23, 2023



Humans can easily imagine the complete 3D geometry of occluded objects and scenes. This appealing ability is vital for recognition and understanding. To enable such capability in AI systems, we propose VoxFormer, a Transformer-based semantic scene completion framework that can output complete 3D volumetric semantics from only 2D images. Our framework adopts a two-stage design where we start from a sparse set of visible and occupied voxel queries from depth estimation, followed by a densification stage that generates dense 3D voxels from the sparse ones. A key idea of this design is that the visual features on 2D images correspond only to the visible scene structures rather than the occluded or empty spaces. Therefore, starting with the featurization and prediction of the visible structures is more reliable. Once we obtain the set of sparse queries, we apply a masked autoencoder design to propagate the information to all the voxels by self-attention. Experiments on SemanticKITTI show that VoxFormer outperforms the state of the art with a relative improvement of 20.0% in geometry and 18.1% in semantics and reduces GPU memory during training by ~45% to less than 16GB. Our code is available on https://github.com/NVlabs/VoxFormer.
PeRFception: Perception using Radiance Fields
Aug 24, 2022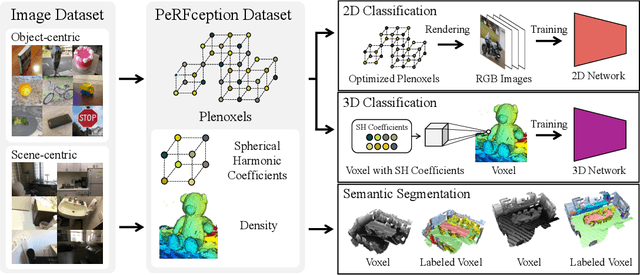
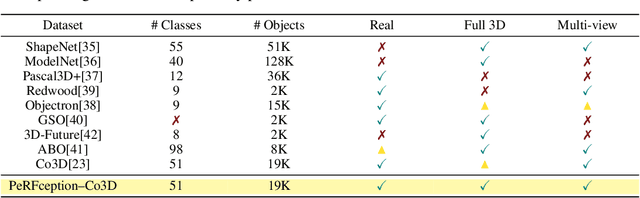
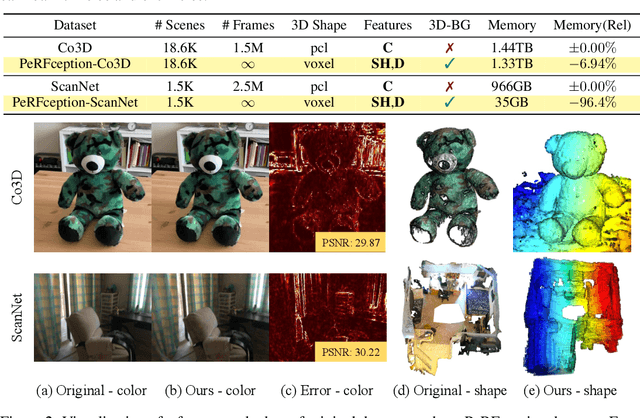

The recent progress in implicit 3D representation, i.e., Neural Radiance Fields (NeRFs), has made accurate and photorealistic 3D reconstruction possible in a differentiable manner. This new representation can effectively convey the information of hundreds of high-resolution images in one compact format and allows photorealistic synthesis of novel views. In this work, using the variant of NeRF called Plenoxels, we create the first large-scale implicit representation datasets for perception tasks, called the PeRFception, which consists of two parts that incorporate both object-centric and scene-centric scans for classification and segmentation. It shows a significant memory compression rate (96.4\%) from the original dataset, while containing both 2D and 3D information in a unified form. We construct the classification and segmentation models that directly take as input this implicit format and also propose a novel augmentation technique to avoid overfitting on backgrounds of images. The code and data are publicly available in https://postech-cvlab.github.io/PeRFception .
Neural Scene Representation for Locomotion on Structured Terrain
Jun 16, 2022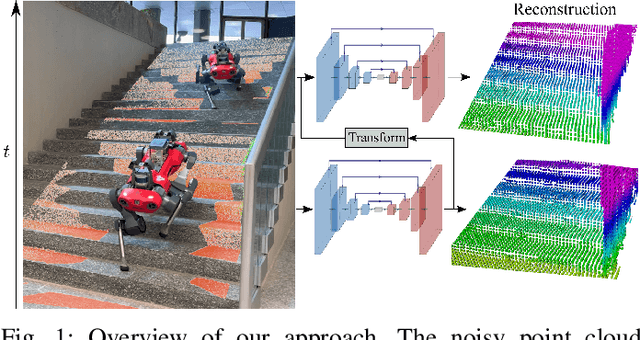
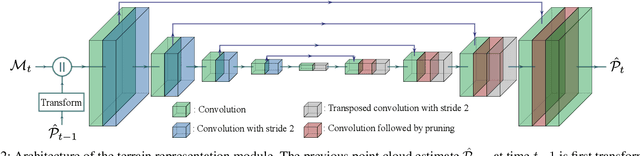

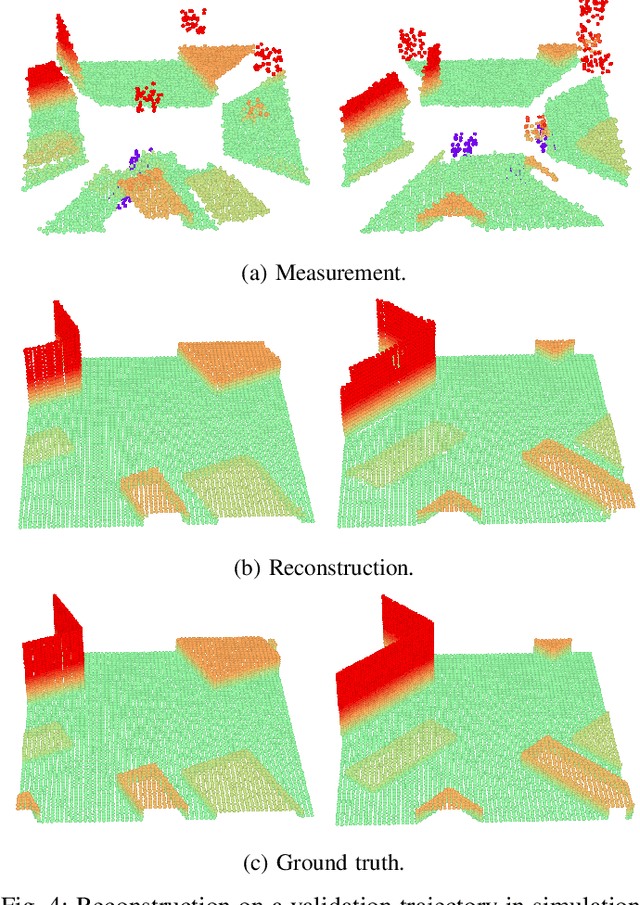
We propose a learning-based method to reconstruct the local terrain for locomotion with a mobile robot traversing urban environments. Using a stream of depth measurements from the onboard cameras and the robot's trajectory, the algorithm estimates the topography in the robot's vicinity. The raw measurements from these cameras are noisy and only provide partial and occluded observations that in many cases do not show the terrain the robot stands on. Therefore, we propose a 3D reconstruction model that faithfully reconstructs the scene, despite the noisy measurements and large amounts of missing data coming from the blind spots of the camera arrangement. The model consists of a 4D fully convolutional network on point clouds that learns the geometric priors to complete the scene from the context and an auto-regressive feedback to leverage spatio-temporal consistency and use evidence from the past. The network can be solely trained with synthetic data, and due to extensive augmentation, it is robust in the real world, as shown in the validation on a quadrupedal robot, ANYmal, traversing challenging settings. We run the pipeline on the robot's onboard low-power computer using an efficient sparse tensor implementation and show that the proposed method outperforms classical map representations.
ACID: Action-Conditional Implicit Visual Dynamics for Deformable Object Manipulation
Mar 14, 2022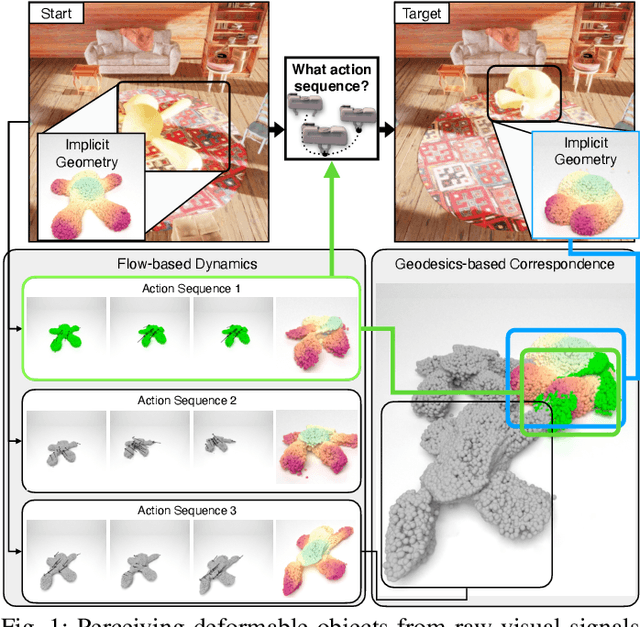
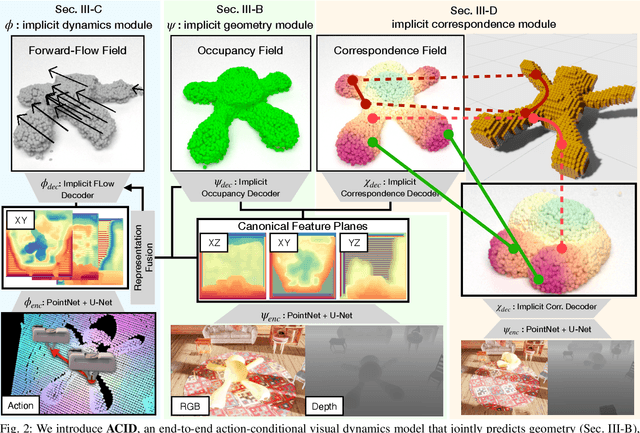


Manipulating volumetric deformable objects in the real world, like plush toys and pizza dough, bring substantial challenges due to infinite shape variations, non-rigid motions, and partial observability. We introduce ACID, an action-conditional visual dynamics model for volumetric deformable objects based on structured implicit neural representations. ACID integrates two new techniques: implicit representations for action-conditional dynamics and geodesics-based contrastive learning. To represent deformable dynamics from partial RGB-D observations, we learn implicit representations of occupancy and flow-based forward dynamics. To accurately identify state change under large non-rigid deformations, we learn a correspondence embedding field through a novel geodesics-based contrastive loss. To evaluate our approach, we develop a simulation framework for manipulating complex deformable shapes in realistic scenes and a benchmark containing over 17,000 action trajectories with six types of plush toys and 78 variants. Our model achieves the best performance in geometry, correspondence, and dynamics predictions over existing approaches. The ACID dynamics models are successfully employed to goal-conditioned deformable manipulation tasks, resulting in a 30% increase in task success rate over the strongest baseline. For more results and information, please visit https://b0ku1.github.io/acid-web/ .
Putting 3D Spatially Sparse Networks on a Diet
Dec 02, 2021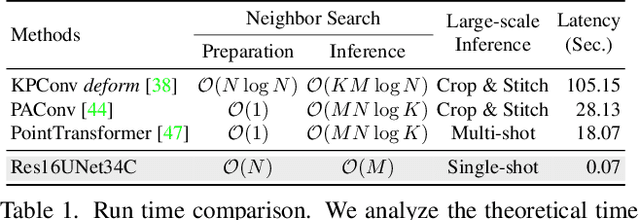
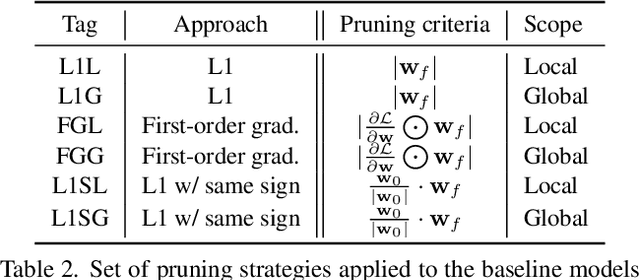
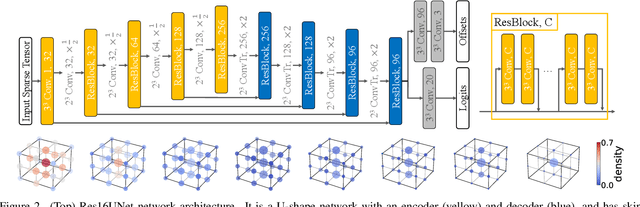
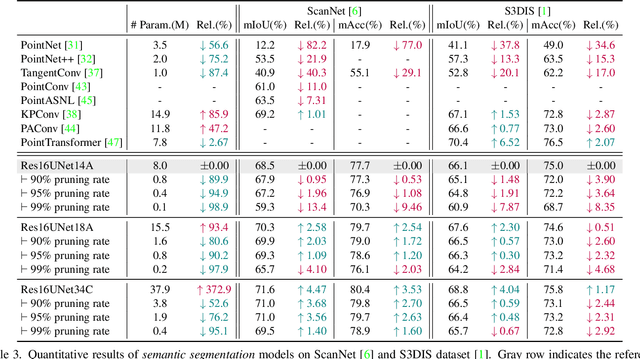
3D neural networks have become prevalent for many 3D vision tasks including object detection, segmentation, registration, and various perception tasks for 3D inputs. However, due to the sparsity and irregularity of 3D data, custom 3D operators or network designs have been the primary focus of 3D research, while the size of networks or efficacy of parameters has been overlooked. In this work, we perform the first comprehensive study on the weight sparsity of spatially sparse 3D convolutional networks and propose a compact weight-sparse and spatially sparse 3D convnet (WS^3-ConvNet) for semantic segmentation and instance segmentation. We employ various network pruning strategies to find compact networks and show our WS^3-ConvNet achieves minimal loss in performance (2.15% drop) with orders-of-magnitude smaller number of parameters (1/100 compression rate). Finally, we systematically analyze the compression patterns of WS^3-ConvNet and show interesting emerging sparsity patterns common in our compressed networks to further speed up inference.
Self-Calibrating Neural Radiance Fields
Sep 02, 2021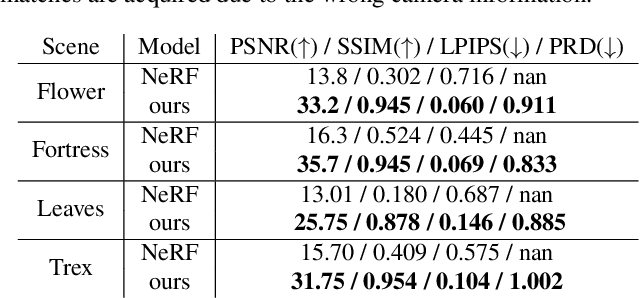
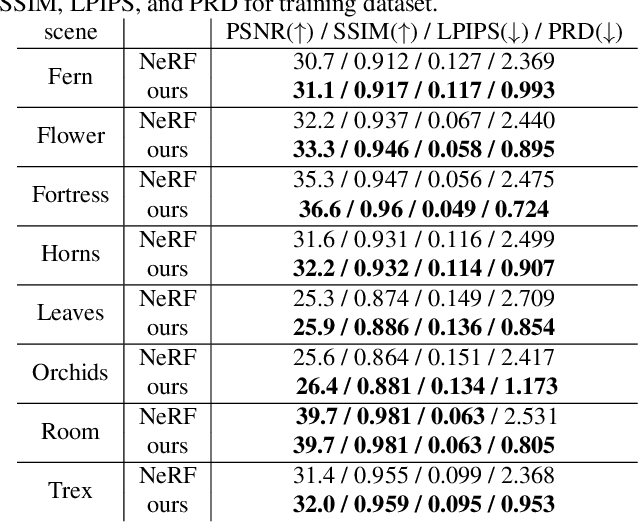

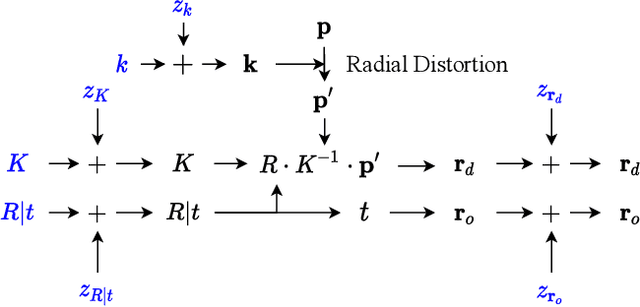
In this work, we propose a camera self-calibration algorithm for generic cameras with arbitrary non-linear distortions. We jointly learn the geometry of the scene and the accurate camera parameters without any calibration objects. Our camera model consists of a pinhole model, a fourth order radial distortion, and a generic noise model that can learn arbitrary non-linear camera distortions. While traditional self-calibration algorithms mostly rely on geometric constraints, we additionally incorporate photometric consistency. This requires learning the geometry of the scene, and we use Neural Radiance Fields (NeRF). We also propose a new geometric loss function, viz., projected ray distance loss, to incorporate geometric consistency for complex non-linear camera models. We validate our approach on standard real image datasets and demonstrate that our model can learn the camera intrinsics and extrinsics (pose) from scratch without COLMAP initialization. Also, we show that learning accurate camera models in a differentiable manner allows us to improve PSNR over baselines. Our module is an easy-to-use plugin that can be applied to NeRF variants to improve performance. The code and data are currently available at https://github.com/POSTECH-CVLab/SCNeRF.
DiscoBox: Weakly Supervised Instance Segmentation and Semantic Correspondence from Box Supervision
Jun 05, 2021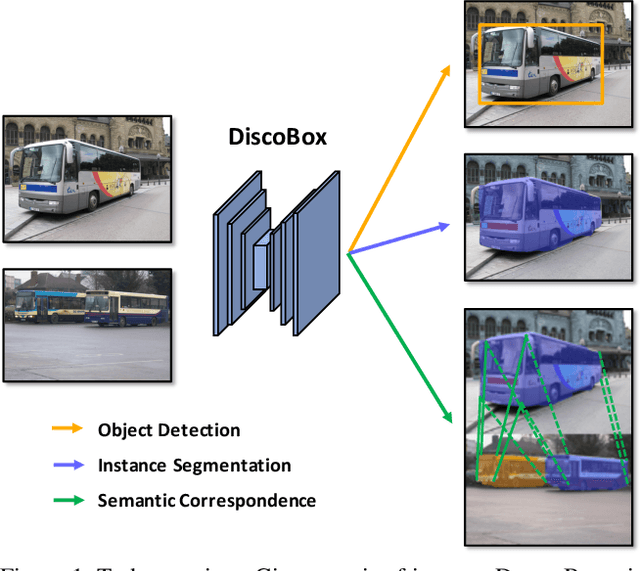
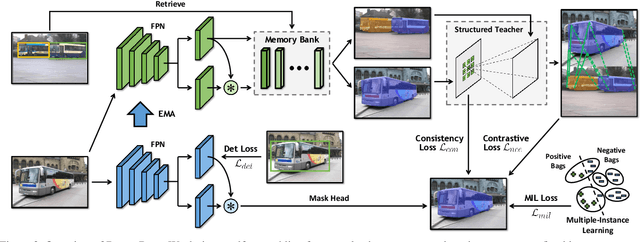
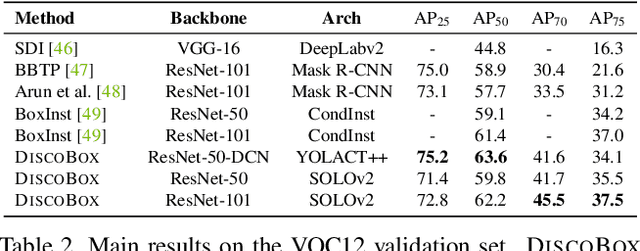
We introduce DiscoBox, a novel framework that jointly learns instance segmentation and semantic correspondence using bounding box supervision. Specifically, we propose a self-ensembling framework where instance segmentation and semantic correspondence are jointly guided by a structured teacher in addition to the bounding box supervision. The teacher is a structured energy model incorporating a pairwise potential and a cross-image potential to model the pairwise pixel relationships both within and across the boxes. Minimizing the teacher energy simultaneously yields refined object masks and dense correspondences between intra-class objects, which are taken as pseudo-labels to supervise the task network and provide positive/negative correspondence pairs for dense constrastive learning. We show a symbiotic relationship where the two tasks mutually benefit from each other. Our best model achieves 37.9% AP on COCO instance segmentation, surpassing prior weakly supervised methods and is competitive to supervised methods. We also obtain state of the art weakly supervised results on PASCAL VOC12 and PF-PASCAL with real-time inference.
Generative Sparse Detection Networks for 3D Single-shot Object Detection
Jun 22, 2020
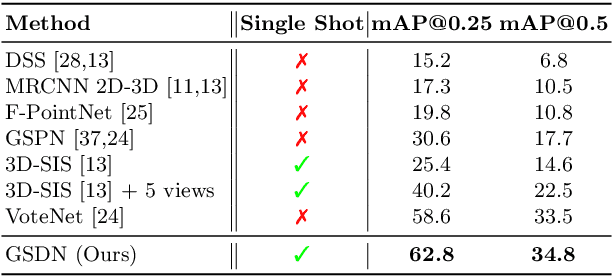
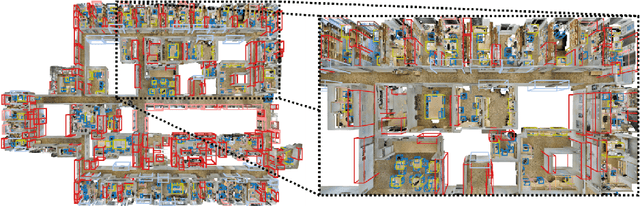

3D object detection has been widely studied due to its potential applicability to many promising areas such as robotics and augmented reality. Yet, the sparse nature of the 3D data poses unique challenges to this task. Most notably, the observable surface of the 3D point clouds is disjoint from the center of the instance to ground the bounding box prediction on. To this end, we propose Generative Sparse Detection Network (GSDN), a fully-convolutional single-shot sparse detection network that efficiently generates the support for object proposals. The key component of our model is a generative sparse tensor decoder, which uses a series of transposed convolutions and pruning layers to expand the support of sparse tensors while discarding unlikely object centers to maintain minimal runtime and memory footprint. GSDN can process unprecedentedly large-scale inputs with a single fully-convolutional feed-forward pass, thus does not require the heuristic post-processing stage that stitches results from sliding windows as other previous methods have. We validate our approach on three 3D indoor datasets including the large-scale 3D indoor reconstruction dataset where our method outperforms the state-of-the-art methods by a relative improvement of 7.14% while being 3.78 times faster than the best prior work.
High-dimensional Convolutional Networks for Geometric Pattern Recognition
May 17, 2020

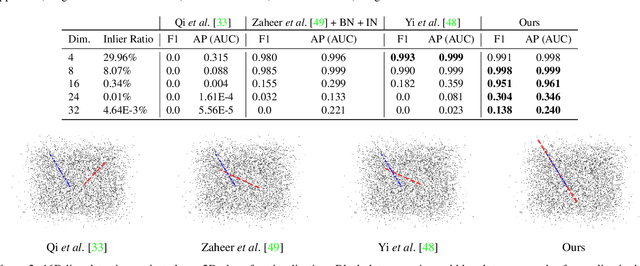
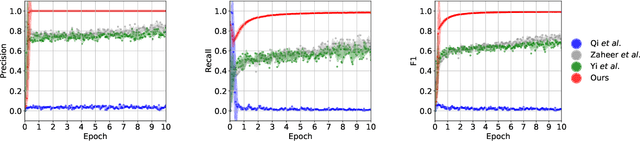
Many problems in science and engineering can be formulated in terms of geometric patterns in high-dimensional spaces. We present high-dimensional convolutional networks (ConvNets) for pattern recognition problems that arise in the context of geometric registration. We first study the effectiveness of convolutional networks in detecting linear subspaces in high-dimensional spaces with up to 32 dimensions: much higher dimensionality than prior applications of ConvNets. We then apply high-dimensional ConvNets to 3D registration under rigid motions and image correspondence estimation. Experiments indicate that our high-dimensional ConvNets outperform prior approaches that relied on deep networks based on global pooling operators.