 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequential Brick Assembly with Efficient Constraint Satisfaction
Oct 03, 2022
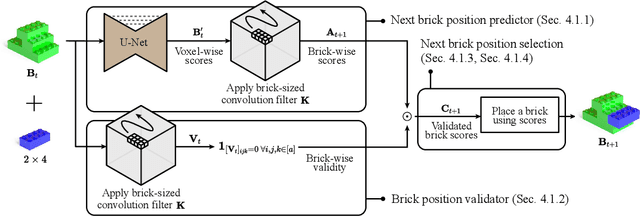
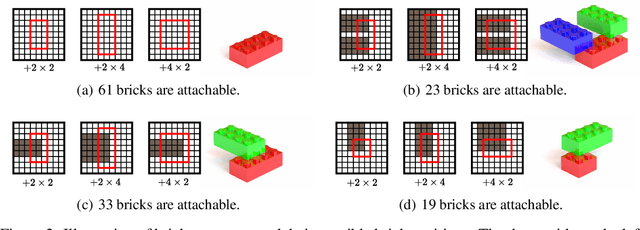
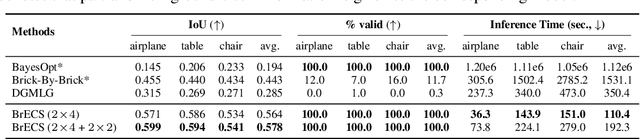
We address the problem of generating a sequence of LEGO brick assembly with high-fidelity structures, satisfying physical constraints between bricks. The assembly problem is challenging since the number of possible structures increases exponentially with the number of available bricks, complicating the physical constraints to satisfy across bricks. To tackle this problem, our method performs a brick structure assessment to predict the next brick position and its confidence by employing a U-shaped sparse 3D convolutional network. The convolution filter efficiently validates physical constraints in a parallelizable and scalable manner, allowing to process of different brick types. To generate a novel structure, we devise a sampling strategy to determine the next brick position by considering attachable positions under physical constraints. Instead of using handcrafted brick assembly datasets, our model is trained with a large number of 3D objects that allow to create a new high-fidelity structure. We demonstrate that our method successfully generates diverse brick structures while handling two different brick types and outperforms existing methods based on Bayesian optimization, graph generative model, and reinforcement learning, all of which are limited to a single brick type.
Style-Agnostic Reinforcement Learning
Aug 31, 2022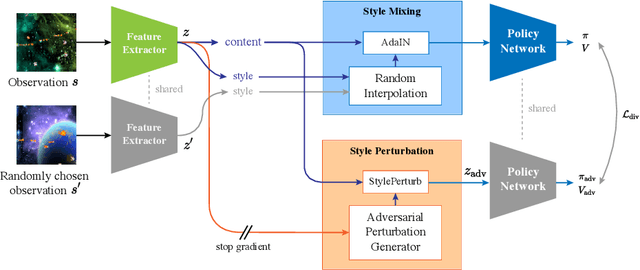
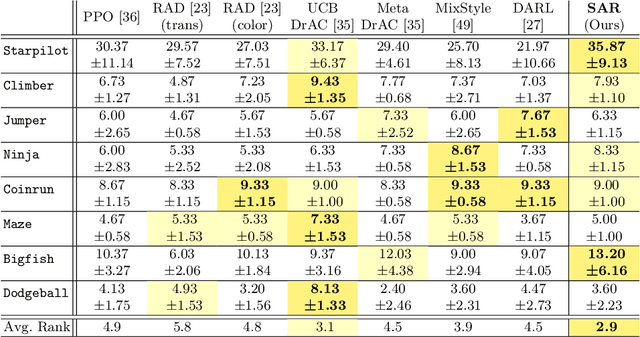

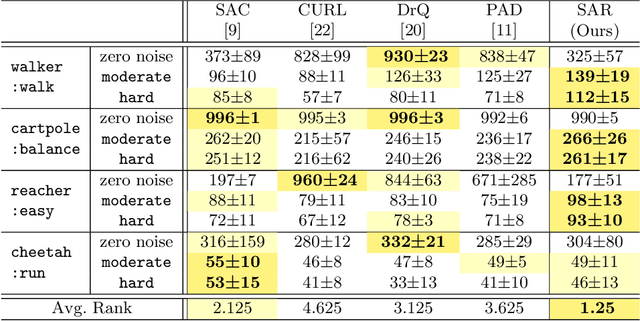
We present a novel method of learning style-agnostic representation using both style transfer and adversarial learning in the reinforcement learning framework. The style, here, refers to task-irrelevant details such as the color of the background in the images, where generalizing the learned policy across environments with different styles is still a challenge. Focusing on learning style-agnostic representations, our method trains the actor with diverse image styles generated from an inherent adversarial style perturbation generator, which plays a min-max game between the actor and the generator, without demanding expert knowledge for data augmentation or additional class labels for adversarial training. We verify that our method achieves competitive or better performances than the state-of-the-art approaches on Procgen and Distracting Control Suite benchmarks, and further investigate the features extracted from our model, showing that the model better captures the invariants and is less distracted by the shifted style. The code is available at https://github.com/POSTECH-CVLab/style-agnostic-RL.
Self-Calibrating Neural Radiance Fields
Sep 02, 2021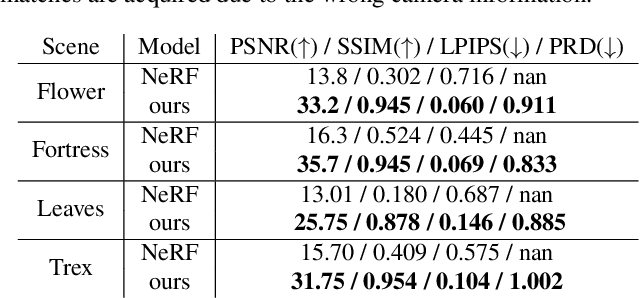
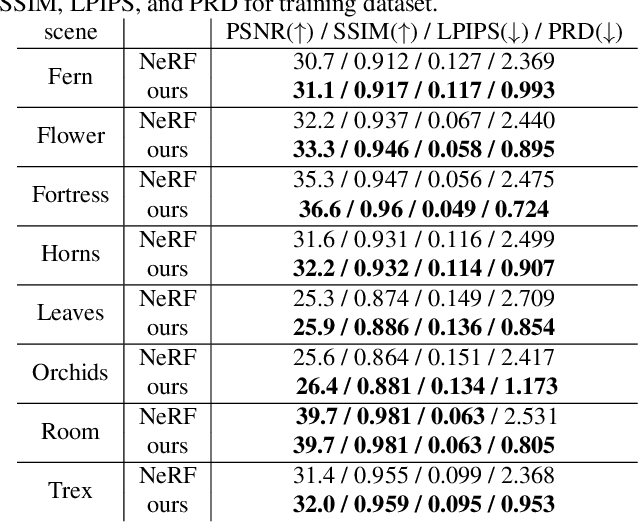

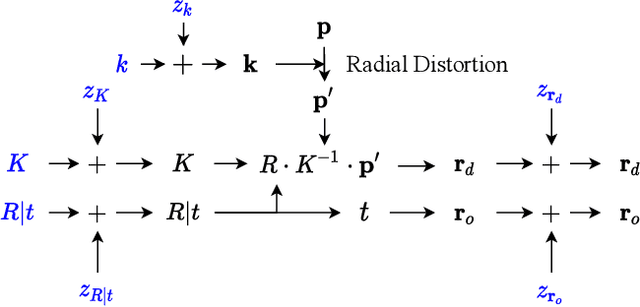
In this work, we propose a camera self-calibration algorithm for generic cameras with arbitrary non-linear distortions. We jointly learn the geometry of the scene and the accurate camera parameters without any calibration objects. Our camera model consists of a pinhole model, a fourth order radial distortion, and a generic noise model that can learn arbitrary non-linear camera distortions. While traditional self-calibration algorithms mostly rely on geometric constraints, we additionally incorporate photometric consistency. This requires learning the geometry of the scene, and we use Neural Radiance Fields (NeRF). We also propose a new geometric loss function, viz., projected ray distance loss, to incorporate geometric consistency for complex non-linear camera models. We validate our approach on standard real image datasets and demonstrate that our model can learn the camera intrinsics and extrinsics (pose) from scratch without COLMAP initialization. Also, we show that learning accurate camera models in a differentiable manner allows us to improve PSNR over baselines. Our module is an easy-to-use plugin that can be applied to NeRF variants to improve performance. The code and data are currently available at https://github.com/POSTECH-CVLab/SCNeRF.