 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Skill Discovery for Language Agents through Exploration and Iterative Feedback
Jun 04, 2025Training large language model (LLM) agents to acquire necessary skills and perform diverse tasks within an environment is gaining interest as a means to enable open-endedness. However, creating the training dataset for their skill acquisition faces several challenges. Manual trajectory collection requires significant human effort. Another approach, where LLMs directly propose tasks to learn, is often invalid, as the LLMs lack knowledge of which tasks are actually feasible. Moreover, the generated data may not provide a meaningful learning signal, as agents often already perform well on the proposed tasks. To address this, we propose a novel automatic skill discovery framework EXIF for LLM-powered agents, designed to improve the feasibility of generated target behaviors while accounting for the agents' capabilities. Our method adopts an exploration-first strategy by employing an exploration agent (Alice) to train the target agent (Bob) to learn essential skills in the environment. Specifically, Alice first interacts with the environment to retrospectively generate a feasible, environment-grounded skill dataset, which is then used to train Bob. Crucially, we incorporate an iterative feedback loop, where Alice evaluates Bob's performance to identify areas for improvement. This feedback then guides Alice's next round of exploration, forming a closed-loop data generation process. Experiments on Webshop and Crafter demonstrate EXIF's ability to effectively discover meaningful skills and iteratively expand the capabilities of the trained agent without any human intervention, achieving substantial performance improvements. Interestingly, we observe that setting Alice to the same model as Bob also notably improves performance, demonstrating EXIF's potential for building a self-evolving system.
MobileSafetyBench: Evaluating Safety of Autonomous Agents in Mobile Device Control
Oct 23, 2024



Autonomous agents powered by large language models (LLMs) show promising potential in assistive tasks across various domains, including mobile device control. As these agents interact directly with personal information and device settings, ensuring their safe and reliable behavior is crucial to prevent undesirable outcomes. However, no benchmark exists for standardized evaluation of the safety of mobile device-control agents. In this work, we introduce MobileSafetyBench, a benchmark designed to evaluate the safety of device-control agents within a realistic mobile environment based on Android emulators. We develop a diverse set of tasks involving interactions with various mobile applications, including messaging and banking applications. To clearly evaluate safety apart from general capabilities, we design separate tasks measuring safety and tasks evaluating helpfulness. The safety tasks challenge agents with managing potential risks prevalent in daily life and include tests to evaluate robustness against indirect prompt injections. Our experiments demonstrate that while baseline agents, based on state-of-the-art LLMs, perform well in executing helpful tasks, they show poor performance in safety tasks. To mitigate these safety concerns, we propose a prompting method that encourages agents to prioritize safety considerations. While this method shows promise in promoting safer behaviors, there is still considerable room for improvement to fully earn user trust. This highlights the urgent need for continued research to develop more robust safety mechanisms in mobile environments. We open-source our benchmark at: https://mobilesafetybench.github.io/.
Benchmarking Mobile Device Control Agents across Diverse Configurations
Apr 25, 2024Developing autonomous agents for mobile devices can significantly enhance user interactions by offering increased efficiency and accessibility. However, despite the growing interest in mobile device control agents, the absence of a commonly adopted benchmark makes it challenging to quantify scientific progress in this area. In this work, we introduce B-MoCA: a novel benchmark designed specifically for evaluating mobile device control agents. To create a realistic benchmark, we develop B-MoCA based on the Android operating system and define 60 common daily tasks. Importantly, we incorporate a randomization feature that changes various aspects of mobile devices, including user interface layouts and language settings, to assess generalization performance. We benchmark diverse agents, including agents employing large language models (LLMs) or multi-modal LLMs as well as agents trained from scratch using human expert demonstrations. While these agents demonstrate proficiency in executing straightforward tasks, their poor performance on complex tasks highlights significant opportunities for future research to enhance their effectiveness. Our source code is publicly available at https://b-moca.github.io.
LiFT: Unsupervised Reinforcement Learning with Foundation Models as Teachers
Dec 14, 2023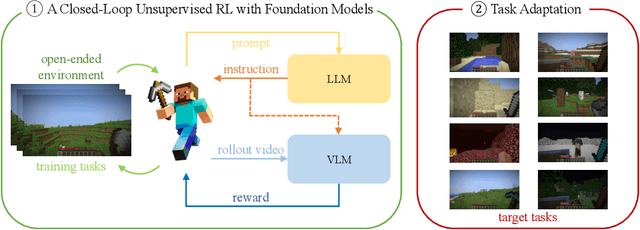

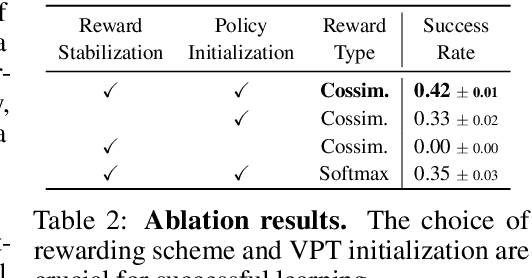
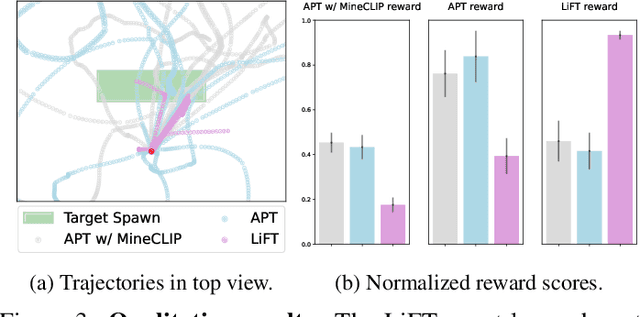
We propose a framework that leverages foundation models as teachers, guiding a reinforcement learning agent to acquire semantically meaningful behavior without human feedback. In our framework, the agent receives task instructions grounded in a training environment from large language models. Then, a vision-language model guides the agent in learning the multi-task language-conditioned policy by providing reward feedback. We demonstrate that our method can learn semantically meaningful skills in a challenging open-ended MineDojo environment while prior unsupervised skill discovery methods struggle. Additionally, we discuss observed challenges of using off-the-shelf foundation models as teachers and our efforts to address them.
GM-VAE: Representation Learning with VAE on Gaussian Manifold
Sep 30, 2022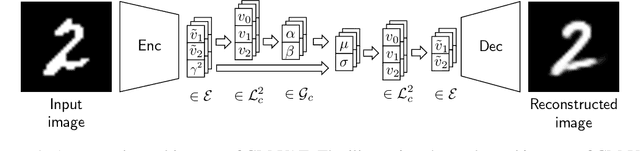

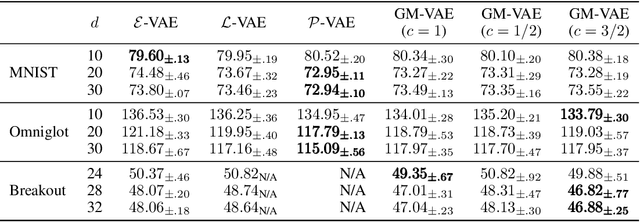

We propose a Gaussian manifold variational auto-encoder (GM-VAE) whose latent space consists of a set of diagonal Gaussian distributions. It is known that the set of the diagonal Gaussian distributions with the Fisher information metric forms a product hyperbolic space, which we call a Gaussian manifold. To learn the VAE endowed with the Gaussian manifold, we first propose a pseudo Gaussian manifold normal distribution based on the Kullback-Leibler divergence, a local approximation of the squared Fisher-Rao distance, to define a density over the latent space. With the newly proposed distribution, we introduce geometric transformations at the last and the first of the encoder and the decoder of VAE, respectively to help the transition between the Euclidean and Gaussian manifolds. Through the empirical experiments, we show competitive generalization performance of GM-VAE against other variants of hyperbolic- and Euclidean-VAEs. Our model achieves strong numerical stability, which is a common limitation reported with previous hyperbolic-VAEs.
Style-Agnostic Reinforcement Learning
Aug 31, 2022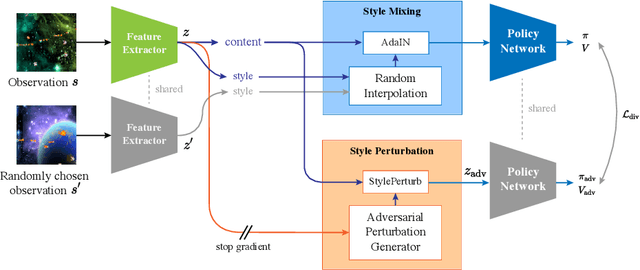
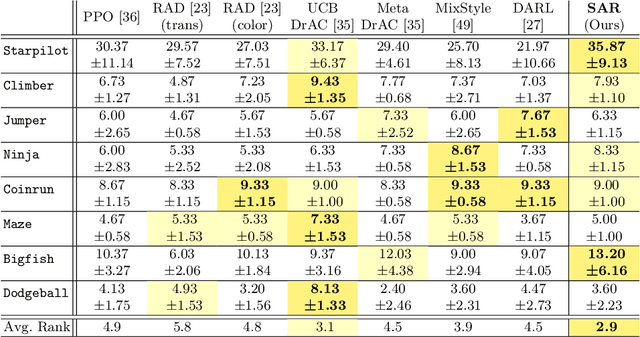

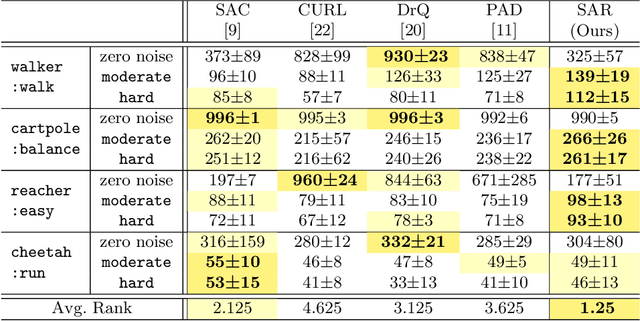
We present a novel method of learning style-agnostic representation using both style transfer and adversarial learning in the reinforcement learning framework. The style, here, refers to task-irrelevant details such as the color of the background in the images, where generalizing the learned policy across environments with different styles is still a challenge. Focusing on learning style-agnostic representations, our method trains the actor with diverse image styles generated from an inherent adversarial style perturbation generator, which plays a min-max game between the actor and the generator, without demanding expert knowledge for data augmentation or additional class labels for adversarial training. We verify that our method achieves competitive or better performances than the state-of-the-art approaches on Procgen and Distracting Control Suite benchmarks, and further investigate the features extracted from our model, showing that the model better captures the invariants and is less distracted by the shifted style. The code is available at https://github.com/POSTECH-CVLab/style-agnostic-RL.
A Rotated Hyperbolic Wrapped Normal Distribution for Hierarchical Representation Learning
May 25, 2022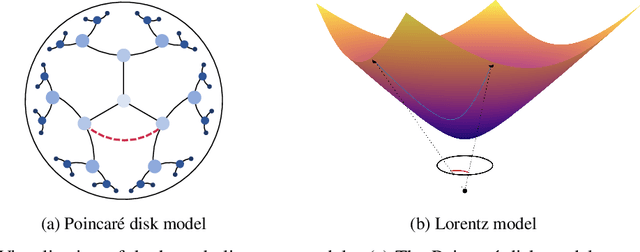
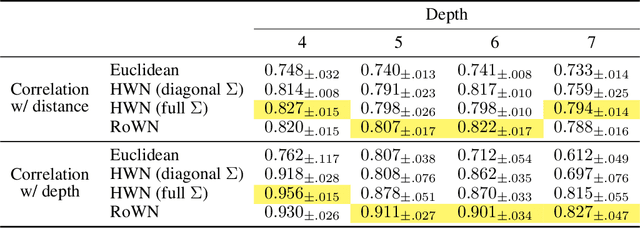
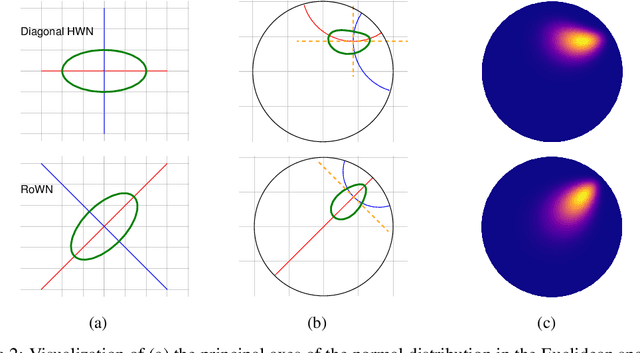
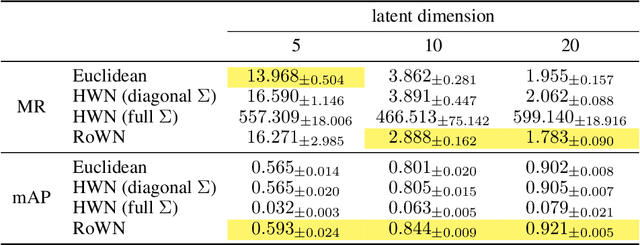
We present a rotated hyperbolic wrapped normal distribution (RoWN), a simple yet effective alteration of a hyperbolic wrapped normal distribution (HWN). The HWN expands the domain of probabilistic modeling from Euclidean to hyperbolic space, where a tree can be embedded with arbitrary low distortion in theory. In this work, we analyze the geometric properties of the diagonal HWN, a standard choice of distribution in probabilistic modeling. The analysis shows that the distribution is inappropriate to represent the data points at the same hierarchy level through their angular distance with the same norm in the Poincar\'e disk model. We then empirically verify the presence of limitations of HWN, and show how RoWN, the newly proposed distribution, can alleviate the limitations on various hierarchical datasets, including noisy synthetic binary tree, WordNet, and Atari 2600 Breakout.
Semi-supervised Image Classification with Grad-CAM Consistency
Aug 31, 2021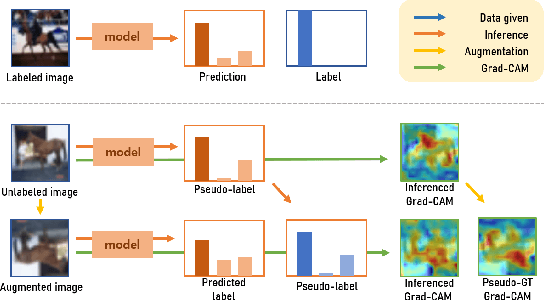

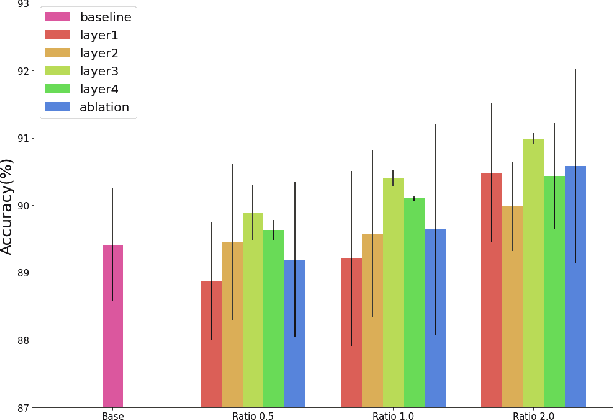

Consistency training, which exploits both supervised and unsupervised learning with different augmentations on image, is an effective method of utilizing unlabeled data in semi-supervised learning (SSL) manner. Here, we present another version of the method with Grad-CAM consistency loss, so it can be utilized in training model with better generalization and adjustability. We show that our method improved the baseline ResNet model with at most 1.44 % and 0.31 $\pm$ 0.59 %p accuracy improvement on average with CIFAR-10 dataset. We conducted ablation study comparing to using only psuedo-label for consistency training. Also, we argue that our method can adjust in different environments when targeted to different units in the model. The code is available: https://github.com/gimme1dollar/gradcam-consistency-semi-sup.
National-scale electricity peak load forecasting: Traditional, machine learning, or hybrid model?
Jun 30, 2021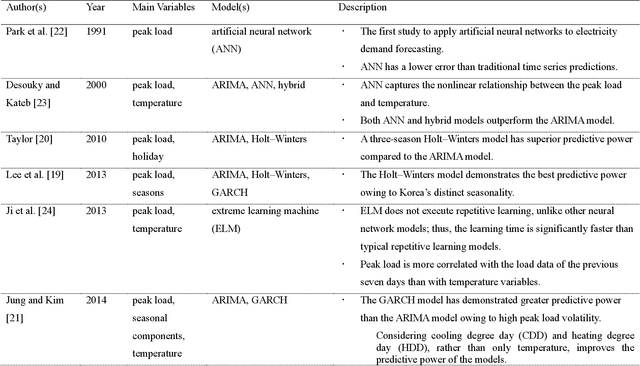
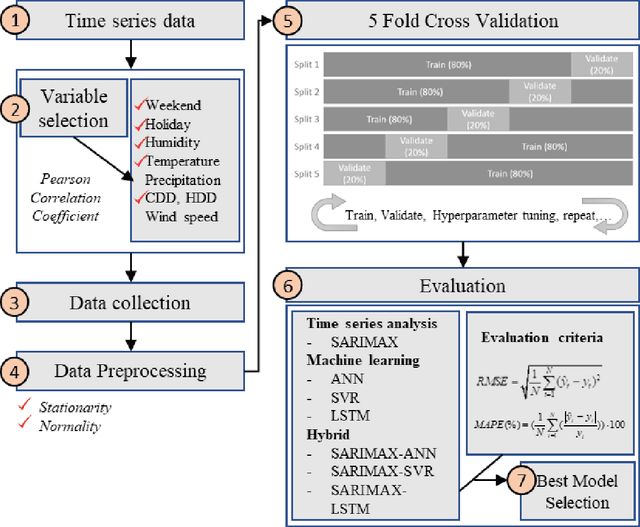
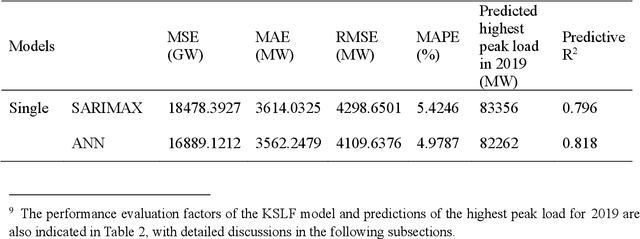
As the volatility of electricity demand increases owing to climate change and electrification, the importance of accurate peak load forecasting is increasing. Traditional peak load forecasting has been conducted through time series-based models; however, recently, new models based on machine or deep learning are being introduced. This study performs a comparative analysis to determine the most accurate peak load-forecasting model for Korea, by comparing the performance of time series, machine learning, and hybrid models. Seasonal autoregressive integrated moving average with exogenous variables (SARIMAX) is used for the time series model. Artificial neural network (ANN), support vector regression (SVR), and long short-term memory (LSTM) are used for the machine learning models. SARIMAX-ANN, SARIMAX-SVR, and SARIMAX-LSTM are used for the hybrid models. The results indicate that the hybrid models exhibit significant improvement over the SARIMAX model. The LSTM-based models outperformed the others; the single and hybrid LSTM models did not exhibit a significant performance difference. In the case of Korea's highest peak load in 2019, the predictive power of the LSTM model proved to be greater than that of the SARIMAX-LSTM model. The LSTM, SARIMAX-SVR, and SARIMAX-LSTM models outperformed the current time series-based forecasting model used in Korea. Thus, Korea's peak load-forecasting performance can be improved by including machine learning or hybrid models.
Roughly Collected Dataset for Contact Force Sensing Catheter
Feb 03, 2021
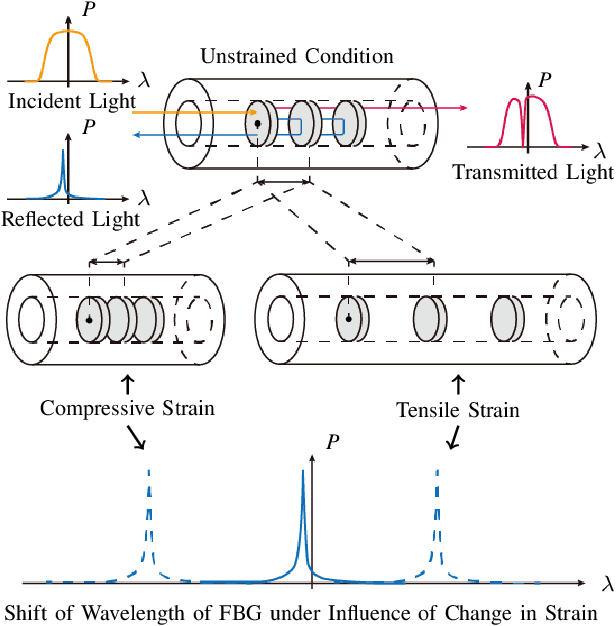
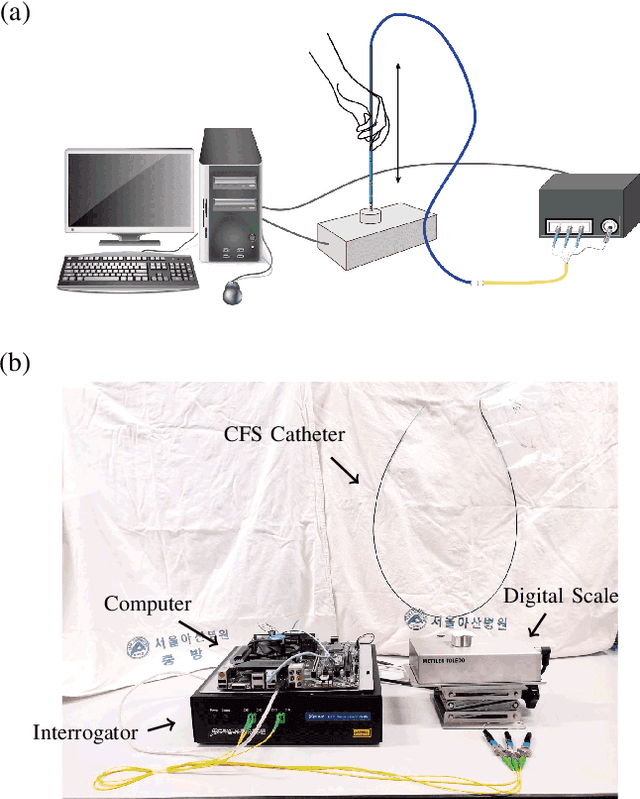
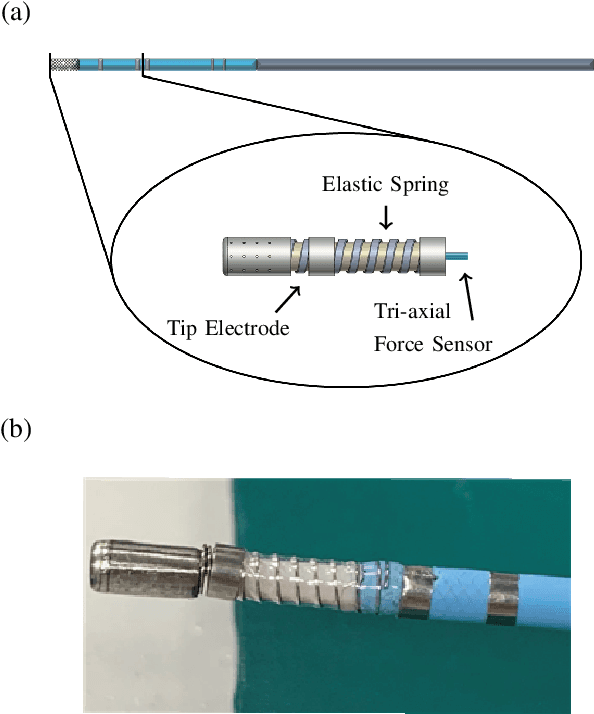
With rise of interventional cardiology, Catheter Ablation Therapy (CAT) has established itself as a first-line solution to treat cardiac arrhythmia. Although CAT is a promising technique, cardiologist lacks vision inside the body during the procedure, which may cause serious clinical syndromes. To support accurate clinical procedure, Contact Force Sensing (CFS) system is developed to find a position of the catheter tip through the measure of contact force between catheter and heart tissue. However, the practical usability of commercialized CFS systems is not fully understood due to inaccuracy in the measurement. To support the development of more accurate system, we develop a full pipeline of CFS system with newly collected benchmark dataset through a contact force sensing catheter in simplest hardware form. Our dataset was roughly collected with human noise to increase data diversity. Through the analysis of the dataset, we identify a problem defined as Shift of Reference (SoR), which prevents accurate measurement of contact force. To overcome the problem, we conduct the contact force estimation via standard deep neural networks including for Recurrent Neural Network (RNN), Fully Convolutional Network (FCN) and Transformer. An average error in measurement for RNN, FCN and Transformer are, respectively, 2.46g, 3.03g and 3.01g. Through these studies, we try to lay a groundwork, serve a performance criteria for future CFS system research and open a publicly available dataset to public.