Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiFT: Unsupervised Reinforcement Learning with Foundation Models as Teachers
Paper and Code
Dec 14, 2023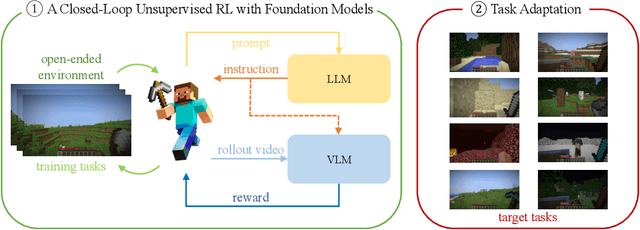

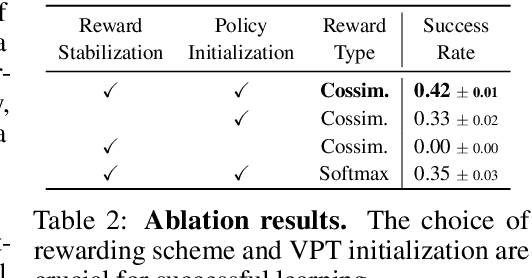
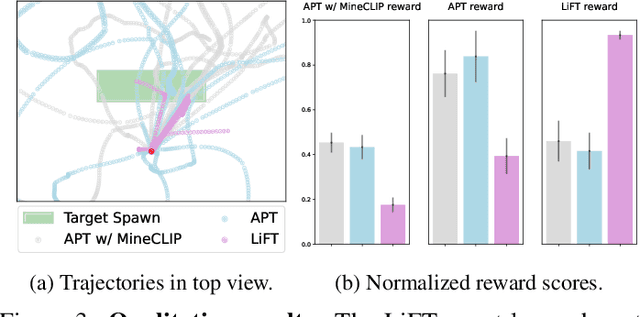
We propose a framework that leverages foundation models as teachers, guiding a reinforcement learning agent to acquire semantically meaningful behavior without human feedback. In our framework, the agent receives task instructions grounded in a training environment from large language models. Then, a vision-language model guides the agent in learning the multi-task language-conditioned policy by providing reward feedback. We demonstrate that our method can learn semantically meaningful skills in a challenging open-ended MineDojo environment while prior unsupervised skill discovery methods struggle. Additionally, we discuss observed challenges of using off-the-shelf foundation models as teachers and our efforts to address them.
* 2nd Workshop on Agent Learning in Open-Endedness (ALOE) at NeurIPS
2023
View paper on