 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiFT: Unsupervised Reinforcement Learning with Foundation Models as Teachers
Dec 14, 2023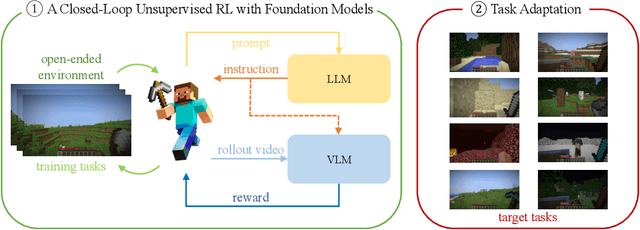

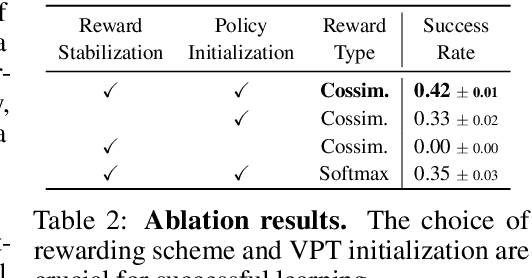
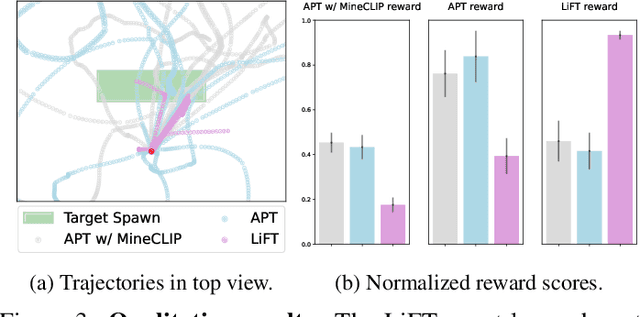
We propose a framework that leverages foundation models as teachers, guiding a reinforcement learning agent to acquire semantically meaningful behavior without human feedback. In our framework, the agent receives task instructions grounded in a training environment from large language models. Then, a vision-language model guides the agent in learning the multi-task language-conditioned policy by providing reward feedback. We demonstrate that our method can learn semantically meaningful skills in a challenging open-ended MineDojo environment while prior unsupervised skill discovery methods struggle. Additionally, we discuss observed challenges of using off-the-shelf foundation models as teachers and our efforts to address them.
Skill-based Meta-Reinforcement Learning
Apr 25, 2022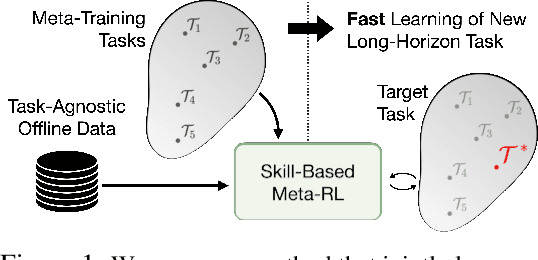
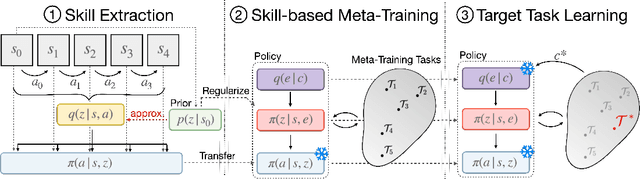
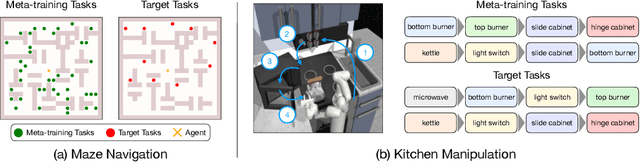
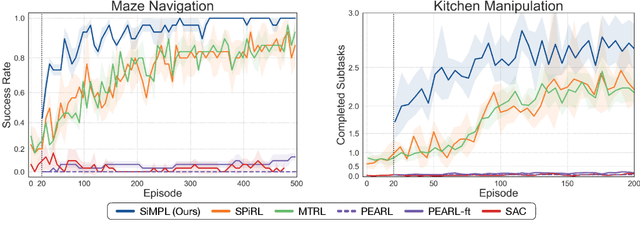
While deep reinforcement learning methods have shown impressive results in robot learning, their sample inefficiency makes the learning of complex, long-horizon behaviors with real robot systems infeasible. To mitigate this issue, meta-reinforcement learning methods aim to enable fast learning on novel tasks by learning how to learn. Yet, the application has been limited to short-horizon tasks with dense rewards. To enable learning long-horizon behaviors, recent works have explored leveraging prior experience in the form of offline datasets without reward or task annotations. While these approaches yield improved sample efficiency, millions of interactions with environments are still required to solve complex tasks. In this work, we devise a method that enables meta-learning on long-horizon, sparse-reward tasks, allowing us to solve unseen target tasks with orders of magnitude fewer environment interactions. Our core idea is to leverage prior experience extracted from offline datasets during meta-learning. Specifically, we propose to (1) extract reusable skills and a skill prior from offline datasets, (2) meta-train a high-level policy that learns to efficiently compose learned skills into long-horizon behaviors, and (3) rapidly adapt the meta-trained policy to solve an unseen target task. Experimental results on continuous control tasks in navigation and manipulation demonstrate that the proposed method can efficiently solve long-horizon novel target tasks by combining the strengths of meta-learning and the usage of offline datasets, while prior approaches in RL, meta-RL, and multi-task RL require substantially more environment interactions to solve the tasks.
Meta Dropout: Learning to Perturb Features for Generalization
May 30, 2019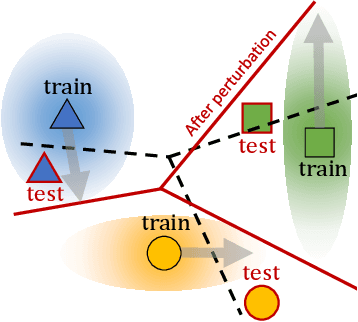
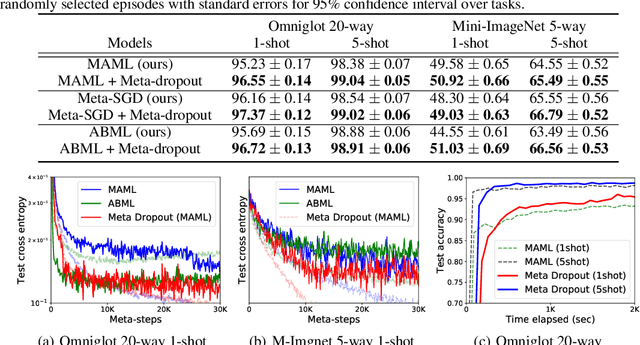
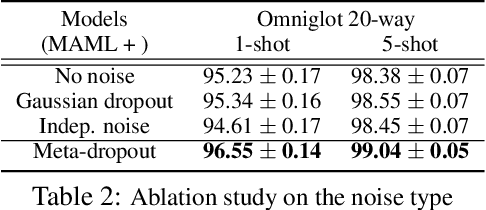

A machine learning model that generalizes well should obtain low errors on the unseen test examples. Test examples could be understood as perturbations of training examples, which means that if we know how to optimally perturb training examples to simulate test examples, we could achieve better generalization at test time. However, obtaining such perturbation is not possible in standard machine learning frameworks as the distribution of the test data is unknown. To tackle this challenge, we propose a meta-learning framework that learns to perturb the latent features of training examples for generalization. Specifically, we meta-learn a noise generator that will output the optimal noise distribution for latent features across all network layers to obtain low error on the test instances, in an input-dependent manner. Then, the learned noise generator will perturb the training examples of unseen tasks at the meta-test time. We show that our method, Meta-dropout, could be also understood as meta-learning of the variational inference framework for a specific graphical model, and describe its connection to existing regularizers. Finally, we validate Meta-dropout on multiple benchmark datasets for few-shot classification, whose results show that it not only significantly improves the generalization performance of meta-learners but also allows them to obtain fast converegence.