 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Learning via Flow-Guided Neural Operator on Time-Series Data
Feb 12, 2026Self-supervised learning (SSL) is a powerful paradigm for learning from unlabeled time-series data. However, popular methods such as masked autoencoders (MAEs) rely on reconstructing inputs from a fixed, predetermined masking ratio. Instead of this static design, we propose treating the corruption level as a new degree of freedom for representation learning, enhancing flexibility and performance. To achieve this, we introduce the Flow-Guided Neural Operator (FGNO), a novel framework combining operator learning with flow matching for SSL training. FGNO learns mappings in functional spaces by using Short-Time Fourier Transform to unify different time resolutions. We extract a rich hierarchy of features by tapping into different network layers and flow times that apply varying strengths of noise to the input data. This enables the extraction of versatile representations, from low-level patterns to high-level global features, using a single model adaptable to specific tasks. Unlike prior generative SSL methods that use noisy inputs during inference, we propose using clean inputs for representation extraction while learning representations with noise; this eliminates randomness and boosts accuracy. We evaluate FGNO across three biomedical domains, where it consistently outperforms established baselines. Our method yields up to 35% AUROC gains in neural signal decoding (BrainTreeBank), 16% RMSE reductions in skin temperature prediction (DREAMT), and over 20% improvement in accuracy and macro-F1 on SleepEDF under low-data regimes. These results highlight FGNO's robustness to data scarcity and its superior capacity to learn expressive representations for diverse time series.
Analyzing Political Text at Scale with Online Tensor LDA
Nov 11, 2025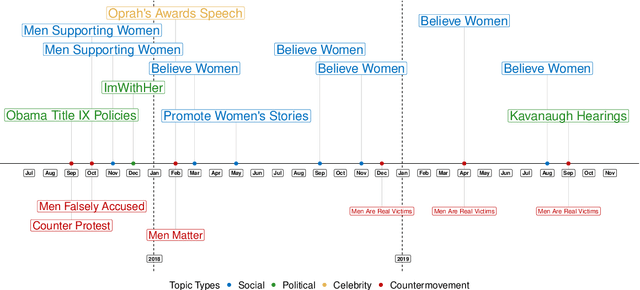

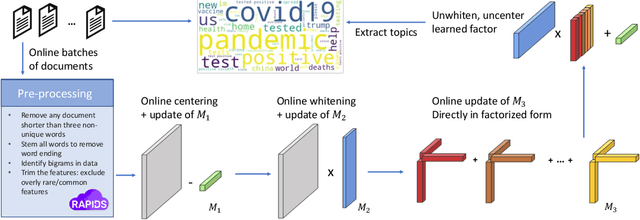
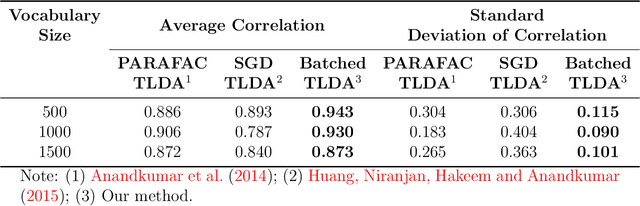
This paper proposes a topic modeling method that scales linearly to billions of documents. We make three core contributions: i) we present a topic modeling method, Tensor Latent Dirichlet Allocation (TLDA), that has identifiable and recoverable parameter guarantees and sample complexity guarantees for large data; ii) we show that this method is computationally and memory efficient (achieving speeds over 3-4x those of prior parallelized Latent Dirichlet Allocation (LDA) methods), and that it scales linearly to text datasets with over a billion documents; iii) we provide an open-source, GPU-based implementation, of this method. This scaling enables previously prohibitive analyses, and we perform two real-world, large-scale new studies of interest to political scientists: we provide the first thorough analysis of the evolution of the #MeToo movement through the lens of over two years of Twitter conversation and a detailed study of social media conversations about election fraud in the 2020 presidential election. Thus this method provides social scientists with the ability to study very large corpora at scale and to answer important theoretically-relevant questions about salient issues in near real-time.
Self-Anchored Attention Model for Sample-Efficient Classification of Prosocial Text Chat
Jun 10, 2025Millions of players engage daily in competitive online games, communicating through in-game chat. Prior research has focused on detecting relatively small volumes of toxic content using various Natural Language Processing (NLP) techniques for the purpose of moderation. However, recent studies emphasize the importance of detecting prosocial communication, which can be as crucial as identifying toxic interactions. Recognizing prosocial behavior allows for its analysis, rewarding, and promotion. Unlike toxicity, there are limited datasets, models, and resources for identifying prosocial behaviors in game-chat text. In this work, we employed unsupervised discovery combined with game domain expert collaboration to identify and categorize prosocial player behaviors from game chat. We further propose a novel Self-Anchored Attention Model (SAAM) which gives 7.9% improvement compared to the best existing technique. The approach utilizes the entire training set as "anchors" to help improve model performance under the scarcity of training data. This approach led to the development of the first automated system for classifying prosocial behaviors in in-game chats, particularly given the low-resource settings where large-scale labeled data is not available. Our methodology was applied to one of the most popular online gaming titles - Call of Duty(R): Modern Warfare(R)II, showcasing its effectiveness. This research is novel in applying NLP techniques to discover and classify prosocial behaviors in player in-game chat communication. It can help shift the focus of moderation from solely penalizing toxicity to actively encouraging positive interactions on online platforms.
FocalFormer3D : Focusing on Hard Instance for 3D Object Detection
Aug 08, 2023



False negatives (FN) in 3D object detection, {\em e.g.}, missing predictions of pedestrians, vehicles, or other obstacles, can lead to potentially dangerous situations in autonomous driving. While being fatal, this issue is understudied in many current 3D detection methods. In this work, we propose Hard Instance Probing (HIP), a general pipeline that identifies \textit{FN} in a multi-stage manner and guides the models to focus on excavating difficult instances. For 3D object detection, we instantiate this method as FocalFormer3D, a simple yet effective detector that excels at excavating difficult objects and improving prediction recall. FocalFormer3D features a multi-stage query generation to discover hard objects and a box-level transformer decoder to efficiently distinguish objects from massive object candidates. Experimental results on the nuScenes and Waymo datasets validate the superior performance of FocalFormer3D. The advantage leads to strong performance on both detection and tracking, in both LiDAR and multi-modal settings. Notably, FocalFormer3D achieves a 70.5 mAP and 73.9 NDS on nuScenes detection benchmark, while the nuScenes tracking benchmark shows 72.1 AMOTA, both ranking 1st place on the nuScenes LiDAR leaderboard. Our code is available at \url{https://github.com/NVlabs/FocalFormer3D}.
Differentially Private Video Activity Recognition
Jun 27, 2023



In recent years, differential privacy has seen significant advancements in image classification; however, its application to video activity recognition remains under-explored. This paper addresses the challenges of applying differential privacy to video activity recognition, which primarily stem from: (1) a discrepancy between the desired privacy level for entire videos and the nature of input data processed by contemporary video architectures, which are typically short, segmented clips; and (2) the complexity and sheer size of video datasets relative to those in image classification, which render traditional differential privacy methods inadequate. To tackle these issues, we propose Multi-Clip DP-SGD, a novel framework for enforcing video-level differential privacy through clip-based classification models. This method samples multiple clips from each video, averages their gradients, and applies gradient clipping in DP-SGD without incurring additional privacy loss. Moreover, we incorporate a parameter-efficient transfer learning strategy to make the model scalable for large-scale video datasets. Through extensive evaluations on the UCF-101 and HMDB-51 datasets, our approach exhibits impressive performance, achieving 81% accuracy with a privacy budget of epsilon=5 on UCF-101, marking a 76% improvement compared to a direct application of DP-SGD. Furthermore, we demonstrate that our transfer learning strategy is versatile and can enhance differentially private image classification across an array of datasets including CheXpert, ImageNet, CIFAR-10, and CIFAR-100.
PeRFception: Perception using Radiance Fields
Aug 24, 2022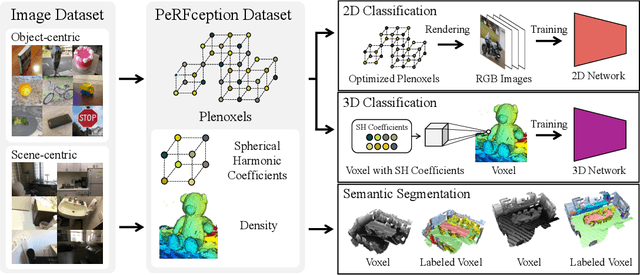
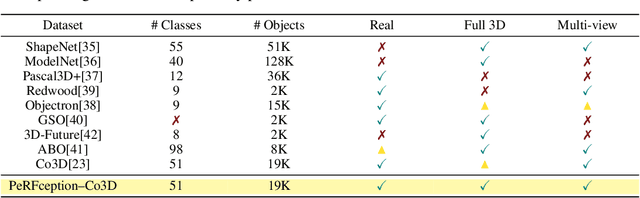
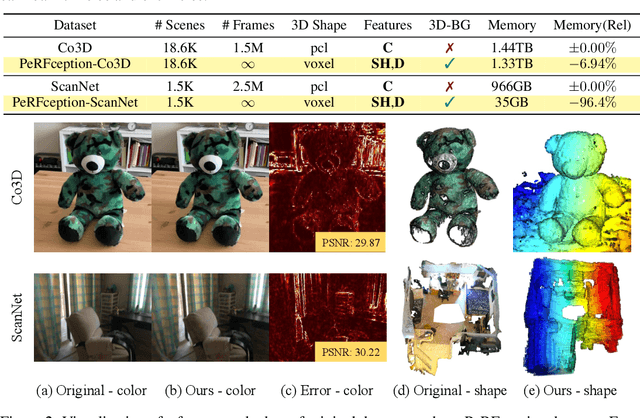

The recent progress in implicit 3D representation, i.e., Neural Radiance Fields (NeRFs), has made accurate and photorealistic 3D reconstruction possible in a differentiable manner. This new representation can effectively convey the information of hundreds of high-resolution images in one compact format and allows photorealistic synthesis of novel views. In this work, using the variant of NeRF called Plenoxels, we create the first large-scale implicit representation datasets for perception tasks, called the PeRFception, which consists of two parts that incorporate both object-centric and scene-centric scans for classification and segmentation. It shows a significant memory compression rate (96.4\%) from the original dataset, while containing both 2D and 3D information in a unified form. We construct the classification and segmentation models that directly take as input this implicit format and also propose a novel augmentation technique to avoid overfitting on backgrounds of images. The code and data are publicly available in https://postech-cvlab.github.io/PeRFception .
FourCastNet: Accelerating Global High-Resolution Weather Forecasting using Adaptive Fourier Neural Operators
Aug 08, 2022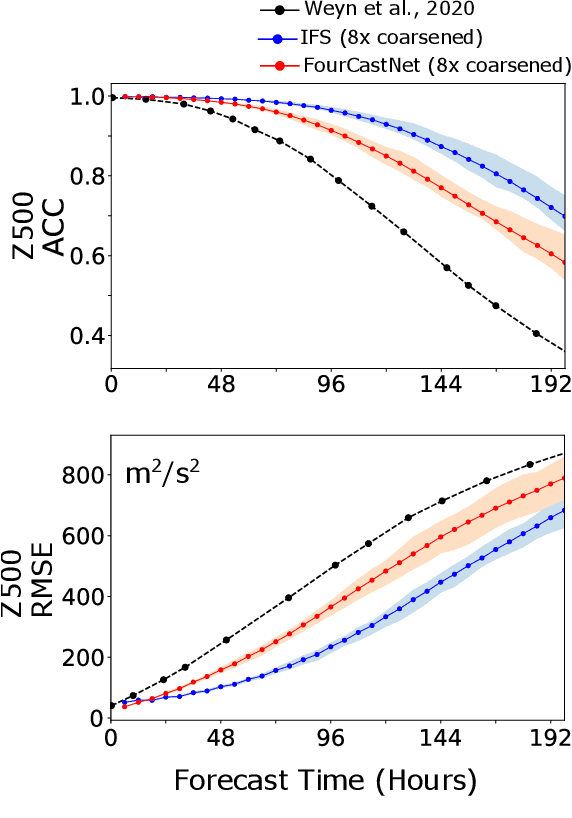
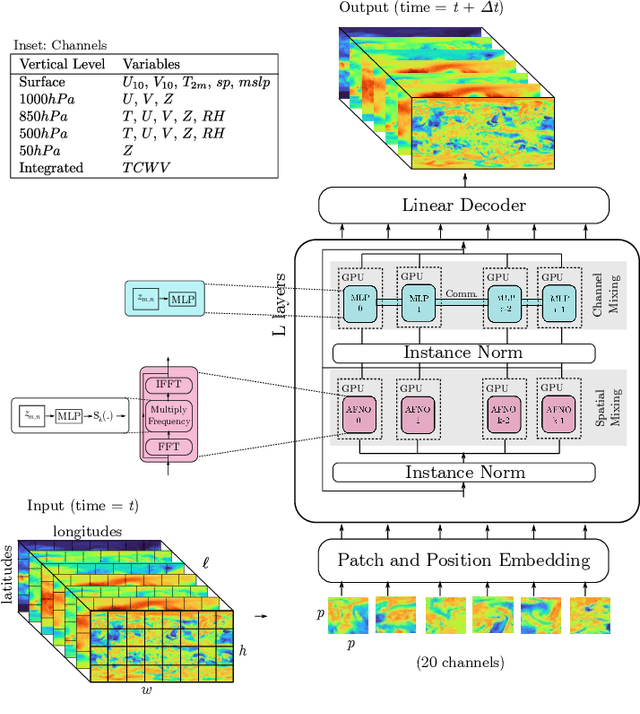
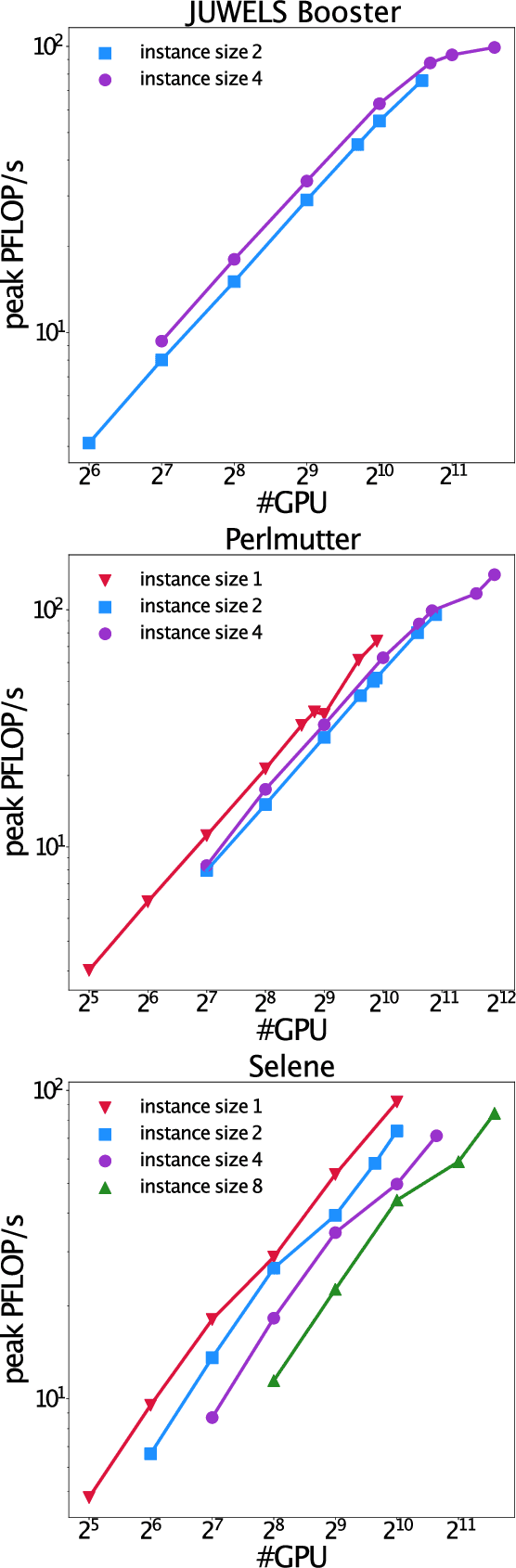
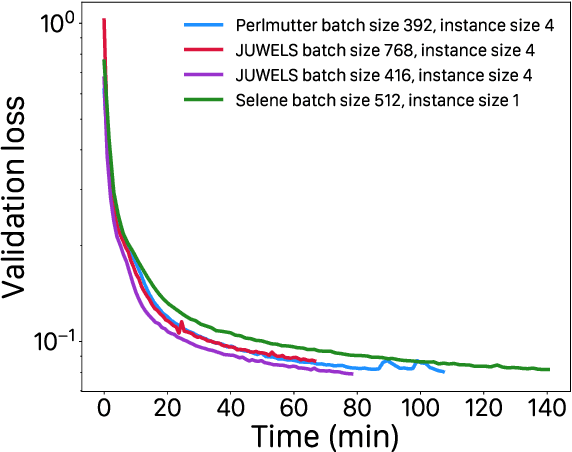
Extreme weather amplified by climate change is causing increasingly devastating impacts across the globe. The current use of physics-based numerical weather prediction (NWP) limits accuracy due to high computational cost and strict time-to-solution limits. We report that a data-driven deep learning Earth system emulator, FourCastNet, can predict global weather and generate medium-range forecasts five orders-of-magnitude faster than NWP while approaching state-of-the-art accuracy. FourCast-Net is optimized and scales efficiently on three supercomputing systems: Selene, Perlmutter, and JUWELS Booster up to 3,808 NVIDIA A100 GPUs, attaining 140.8 petaFLOPS in mixed precision (11.9%of peak at that scale). The time-to-solution for training FourCastNet measured on JUWELS Booster on 3,072GPUs is 67.4minutes, resulting in an 80,000times faster time-to-solution relative to state-of-the-art NWP, in inference. FourCastNet produces accurate instantaneous weather predictions for a week in advance, enables enormous ensembles that better capture weather extremes, and supports higher global forecast resolutions.
Neural Scene Representation for Locomotion on Structured Terrain
Jun 16, 2022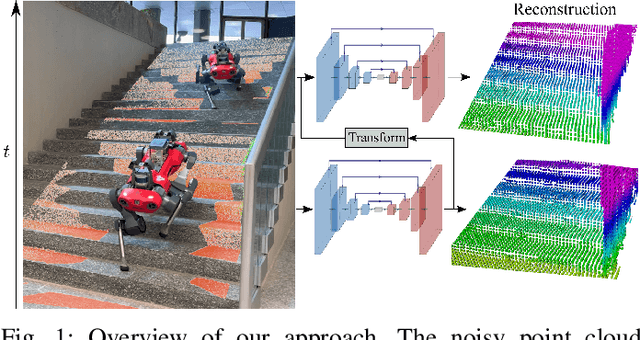
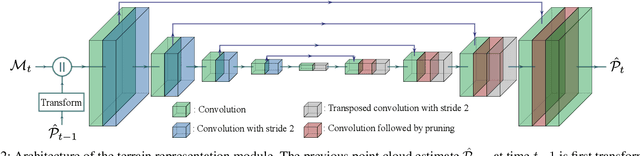

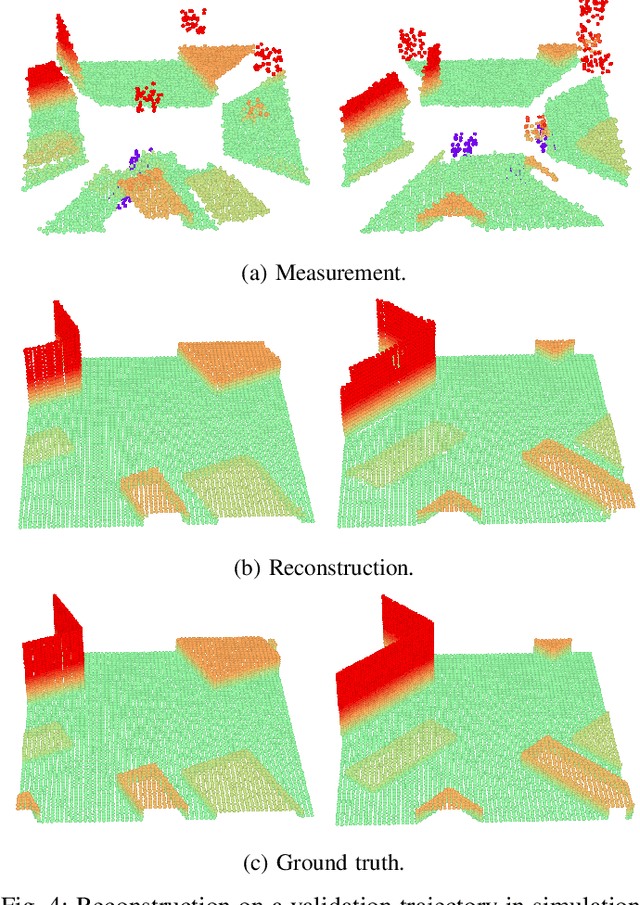
We propose a learning-based method to reconstruct the local terrain for locomotion with a mobile robot traversing urban environments. Using a stream of depth measurements from the onboard cameras and the robot's trajectory, the algorithm estimates the topography in the robot's vicinity. The raw measurements from these cameras are noisy and only provide partial and occluded observations that in many cases do not show the terrain the robot stands on. Therefore, we propose a 3D reconstruction model that faithfully reconstructs the scene, despite the noisy measurements and large amounts of missing data coming from the blind spots of the camera arrangement. The model consists of a 4D fully convolutional network on point clouds that learns the geometric priors to complete the scene from the context and an auto-regressive feedback to leverage spatio-temporal consistency and use evidence from the past. The network can be solely trained with synthetic data, and due to extensive augmentation, it is robust in the real world, as shown in the validation on a quadrupedal robot, ANYmal, traversing challenging settings. We run the pipeline on the robot's onboard low-power computer using an efficient sparse tensor implementation and show that the proposed method outperforms classical map representations.
Quantification of Robotic Surgeries with Vision-Based Deep Learning
May 06, 2022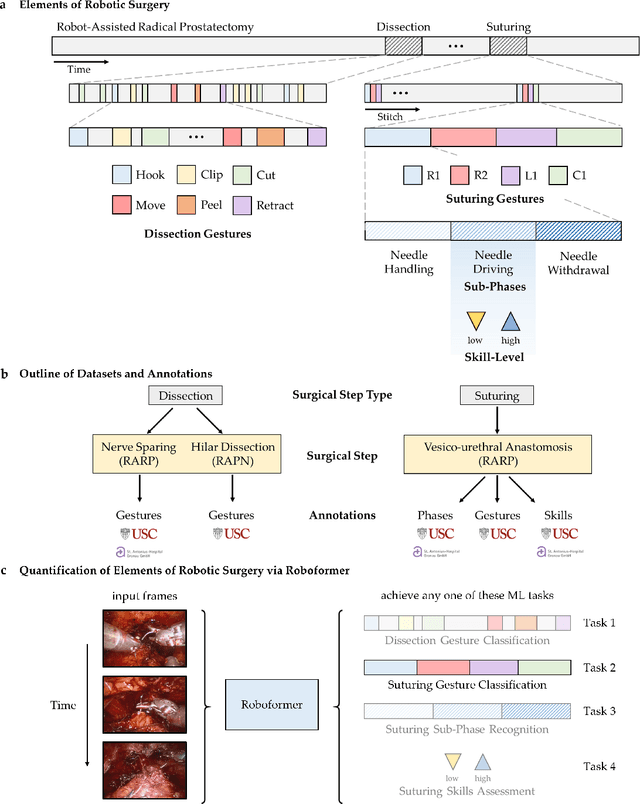
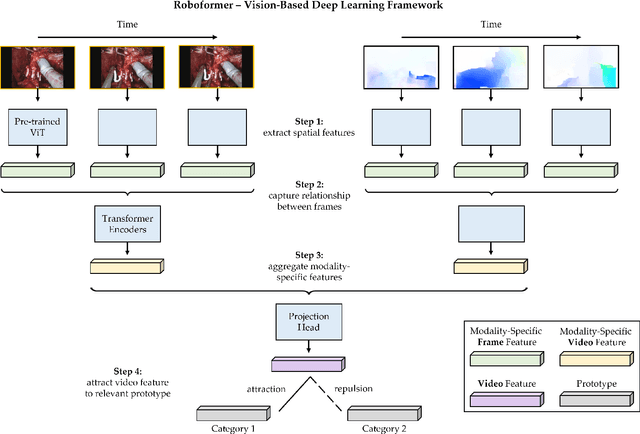
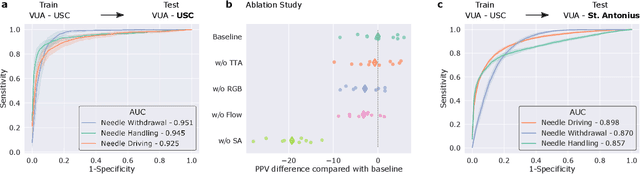
Surgery is a high-stakes domain where surgeons must navigate critical anatomical structures and actively avoid potential complications while achieving the main task at hand. Such surgical activity has been shown to affect long-term patient outcomes. To better understand this relationship, whose mechanics remain unknown for the majority of surgical procedures, we hypothesize that the core elements of surgery must first be quantified in a reliable, objective, and scalable manner. We believe this is a prerequisite for the provision of surgical feedback and modulation of surgeon performance in pursuit of improved patient outcomes. To holistically quantify surgeries, we propose a unified deep learning framework, entitled Roboformer, which operates exclusively on videos recorded during surgery to independently achieve multiple tasks: surgical phase recognition (the what of surgery), gesture classification and skills assessment (the how of surgery). We validated our framework on four video-based datasets of two commonly-encountered types of steps (dissection and suturing) within minimally-invasive robotic surgeries. We demonstrated that our framework can generalize well to unseen videos, surgeons, medical centres, and surgical procedures. We also found that our framework, which naturally lends itself to explainable findings, identified relevant information when achieving a particular task. These findings are likely to instill surgeons with more confidence in our framework's behaviour, increasing the likelihood of clinical adoption, and thus paving the way for more targeted surgical feedback.
FourCastNet: A Global Data-driven High-resolution Weather Model using Adaptive Fourier Neural Operators
Feb 22, 2022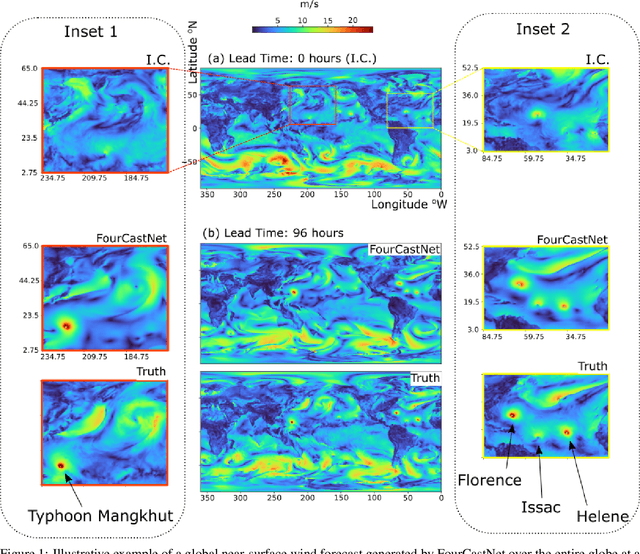

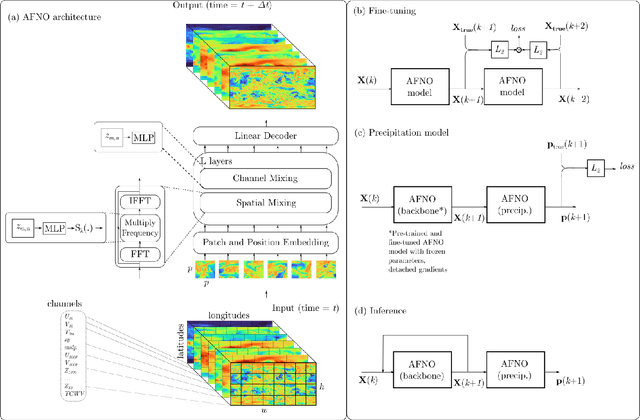
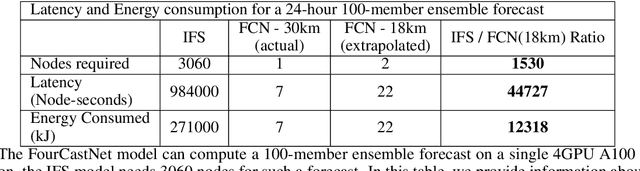
FourCastNet, short for Fourier Forecasting Neural Network, is a global data-driven weather forecasting model that provides accurate short to medium-range global predictions at $0.25^{\circ}$ resolution. FourCastNet accurately forecasts high-resolution, fast-timescale variables such as the surface wind speed, precipitation, and atmospheric water vapor. It has important implications for planning wind energy resources, predicting extreme weather events such as tropical cyclones, extra-tropical cyclones, and atmospheric rivers. FourCastNet matches the forecasting accuracy of the ECMWF Integrated Forecasting System (IFS), a state-of-the-art Numerical Weather Prediction (NWP) model, at short lead times for large-scale variables, while outperforming IFS for variables with complex fine-scale structure, including precipitation. FourCastNet generates a week-long forecast in less than 2 seconds, orders of magnitude faster than IFS. The speed of FourCastNet enables the creation of rapid and inexpensive large-ensemble forecasts with thousands of ensemble-members for improving probabilistic forecasting. We discuss how data-driven deep learning models such as FourCastNet are a valuable addition to the meteorology toolkit to aid and augment NWP models.