 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multi-Agent LLM Framework for Rating the Quality of Surgical Feedback
May 25, 2026Verbal feedback delivered by attending surgeons in the operating room plays a critical formative role in resident trainee skill acquisition. Yet, assessing the quality of trainer feedback and its effectiveness in influencing trainee behavior during live surgery remains a challenge. Prior studies assessed feedback content relying on extensive manual annotation by expert human raters and focused on developing broad taxonomies that overlook the qualitative aspects of feedback delivery such as clarity or urgency. Limited existing automated methods, including keyword analysis and topic modeling, also fail to capture these nuanced aspects. We introduce a two-stage LLM-based framework that discovers interpretable feedback quality criteria grounded in the context of surgical training. Our method uses multi-agent prompting and surgical domain knowledge injection to discover a small set of human interpretable scoring criteria (e.g., Encouraging, Urgent, Clear). These criteria are then used to automatically score live surgical feedback via an LLM-as-a-judge approach. Evaluation on 4.2k trainer feedback instances demonstrates that our AI-discovered criteria outperform prior content-based frameworks in predicting feedback effectiveness, including observed trainee behavioral adjustments and trainer approval. This work advances scalable, human-aligned assessment of communication quality in the operating room and provides a foundation for improving surgical teaching practices.
Generating Natural-Language Surgical Feedback: From Structured Representation to Domain-Grounded Evaluation
Nov 19, 2025High-quality intraoperative feedback from a surgical trainer is pivotal for improving trainee performance and long-term skill acquisition. Automating natural, trainer-style feedback promises timely, accessible, and consistent guidance at scale but requires models that understand clinically relevant representations. We present a structure-aware pipeline that learns a surgical action ontology from real trainer-to-trainee transcripts (33 surgeries) and uses it to condition feedback generation. We contribute by (1) mining Instrument-Action-Target (IAT) triplets from real-world feedback text and clustering surface forms into normalized categories, (2) fine-tuning a video-to-IAT model that leverages the surgical procedure and task contexts as well as fine-grained temporal instrument motion, and (3) demonstrating how to effectively use IAT triplet representations to guide GPT-4o in generating clinically grounded, trainer-style feedback. We show that, on Task 1: Video-to-IAT recognition, our context injection and temporal tracking deliver consistent AUC gains (Instrument: 0.67 to 0.74; Action: 0.60 to 0.63; Tissue: 0.74 to 0.79). For Task 2: feedback text generation (rated on a 1-5 fidelity rubric where 1 = opposite/unsafe, 3 = admissible, and 5 = perfect match to a human trainer), GPT-4o from video alone scores 2.17, while IAT conditioning reaches 2.44 (+12.4%), doubling the share of admissible generations with score >= 3 from 21% to 42%. Traditional text-similarity metrics also improve: word error rate decreases by 15-31% and ROUGE (phrase/substring overlap) increases by 9-64%. Grounding generation in explicit IAT structure improves fidelity and yields clinician-verifiable rationales, supporting auditable use in surgical training.
End to End AI System for Surgical Gesture Sequence Recognition and Clinical Outcome Prediction
Nov 14, 2025Fine-grained analysis of intraoperative behavior and its impact on patient outcomes remain a longstanding challenge. We present Frame-to-Outcome (F2O), an end-to-end system that translates tissue dissection videos into gesture sequences and uncovers patterns associated with postoperative outcomes. Leveraging transformer-based spatial and temporal modeling and frame-wise classification, F2O robustly detects consecutive short (~2 seconds) gestures in the nerve-sparing step of robot-assisted radical prostatectomy (AUC: 0.80 frame-level; 0.81 video-level). F2O-derived features (gesture frequency, duration, and transitions) predicted postoperative outcomes with accuracy comparable to human annotations (0.79 vs. 0.75; overlapping 95% CI). Across 25 shared features, effect size directions were concordant with small differences (~ 0.07), and strong correlation (r = 0.96, p < 1e-14). F2O also captured key patterns linked to erectile function recovery, including prolonged tissue peeling and reduced energy use. By enabling automatic interpretable assessment, F2O establishes a foundation for data-driven surgical feedback and prospective clinical decision support.
Deep Multimodal Fusion for Surgical Feedback Classification
Dec 06, 2023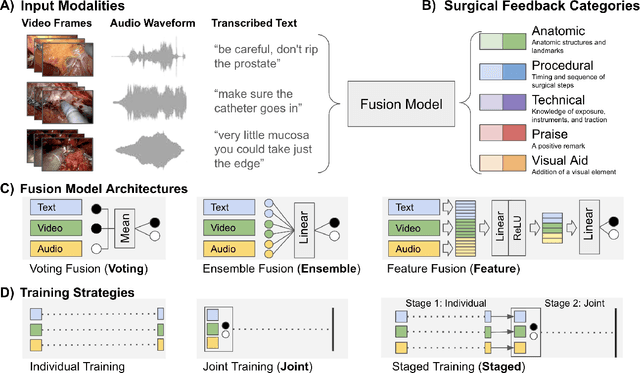

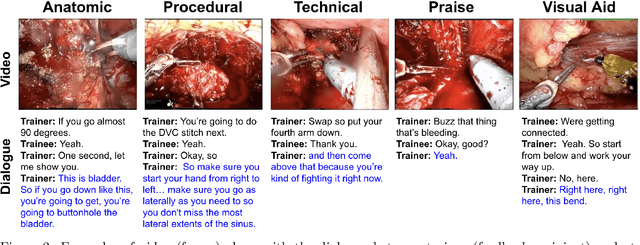
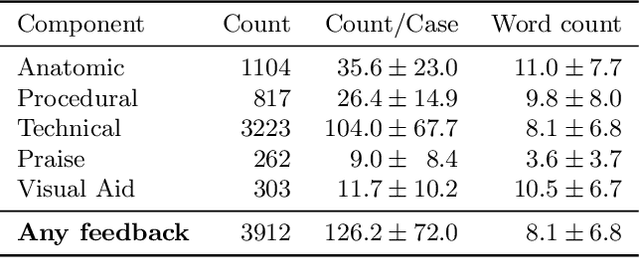
Quantification of real-time informal feedback delivered by an experienced surgeon to a trainee during surgery is important for skill improvements in surgical training. Such feedback in the live operating room is inherently multimodal, consisting of verbal conversations (e.g., questions and answers) as well as non-verbal elements (e.g., through visual cues like pointing to anatomic elements). In this work, we leverage a clinically-validated five-category classification of surgical feedback: "Anatomic", "Technical", "Procedural", "Praise" and "Visual Aid". We then develop a multi-label machine learning model to classify these five categories of surgical feedback from inputs of text, audio, and video modalities. The ultimate goal of our work is to help automate the annotation of real-time contextual surgical feedback at scale. Our automated classification of surgical feedback achieves AUCs ranging from 71.5 to 77.6 with the fusion improving performance by 3.1%. We also show that high-quality manual transcriptions of feedback audio from experts improve AUCs to between 76.5 and 96.2, which demonstrates a clear path toward future improvements. Empirically, we find that the Staged training strategy, with first pre-training each modality separately and then training them jointly, is more effective than training different modalities altogether. We also present intuitive findings on the importance of modalities for different feedback categories. This work offers an important first look at the feasibility of automated classification of real-world live surgical feedback based on text, audio, and video modalities.
Quantification of Robotic Surgeries with Vision-Based Deep Learning
May 06, 2022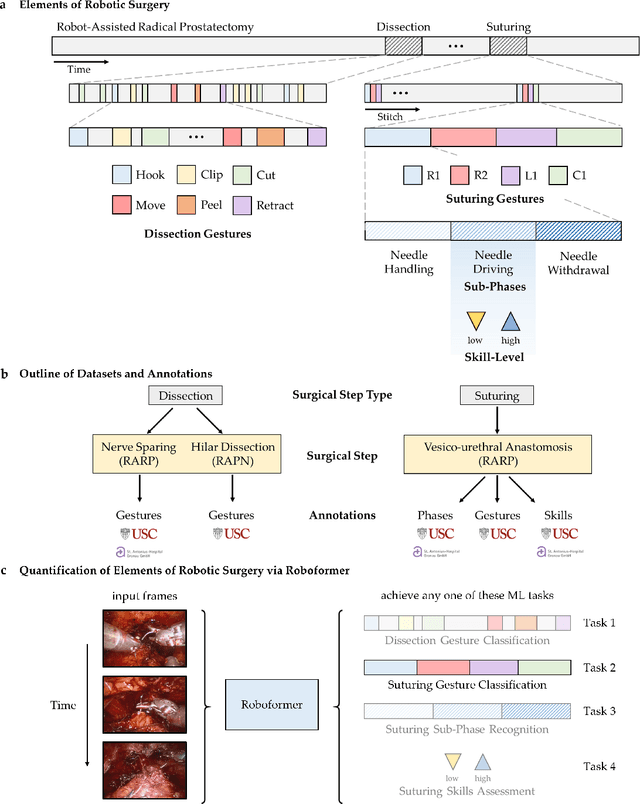
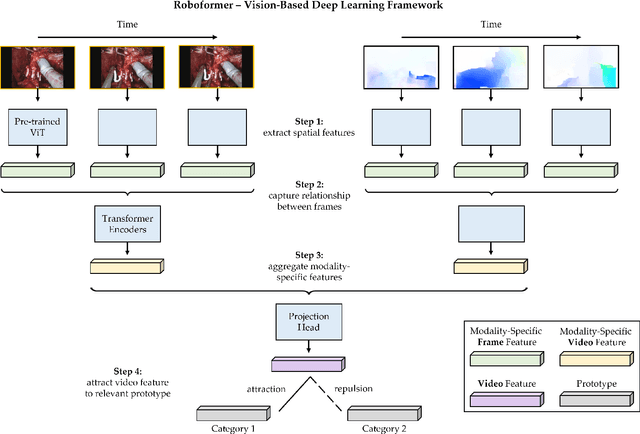
Surgery is a high-stakes domain where surgeons must navigate critical anatomical structures and actively avoid potential complications while achieving the main task at hand. Such surgical activity has been shown to affect long-term patient outcomes. To better understand this relationship, whose mechanics remain unknown for the majority of surgical procedures, we hypothesize that the core elements of surgery must first be quantified in a reliable, objective, and scalable manner. We believe this is a prerequisite for the provision of surgical feedback and modulation of surgeon performance in pursuit of improved patient outcomes. To holistically quantify surgeries, we propose a unified deep learning framework, entitled Roboformer, which operates exclusively on videos recorded during surgery to independently achieve multiple tasks: surgical phase recognition (the what of surgery), gesture classification and skills assessment (the how of surgery). We validated our framework on four video-based datasets of two commonly-encountered types of steps (dissection and suturing) within minimally-invasive robotic surgeries. We demonstrated that our framework can generalize well to unseen videos, surgeons, medical centres, and surgical procedures. We also found that our framework, which naturally lends itself to explainable findings, identified relevant information when achieving a particular task. These findings are likely to instill surgeons with more confidence in our framework's behaviour, increasing the likelihood of clinical adoption, and thus paving the way for more targeted surgical feedback.