 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Natural-Language Surgical Feedback: From Structured Representation to Domain-Grounded Evaluation
Nov 19, 2025High-quality intraoperative feedback from a surgical trainer is pivotal for improving trainee performance and long-term skill acquisition. Automating natural, trainer-style feedback promises timely, accessible, and consistent guidance at scale but requires models that understand clinically relevant representations. We present a structure-aware pipeline that learns a surgical action ontology from real trainer-to-trainee transcripts (33 surgeries) and uses it to condition feedback generation. We contribute by (1) mining Instrument-Action-Target (IAT) triplets from real-world feedback text and clustering surface forms into normalized categories, (2) fine-tuning a video-to-IAT model that leverages the surgical procedure and task contexts as well as fine-grained temporal instrument motion, and (3) demonstrating how to effectively use IAT triplet representations to guide GPT-4o in generating clinically grounded, trainer-style feedback. We show that, on Task 1: Video-to-IAT recognition, our context injection and temporal tracking deliver consistent AUC gains (Instrument: 0.67 to 0.74; Action: 0.60 to 0.63; Tissue: 0.74 to 0.79). For Task 2: feedback text generation (rated on a 1-5 fidelity rubric where 1 = opposite/unsafe, 3 = admissible, and 5 = perfect match to a human trainer), GPT-4o from video alone scores 2.17, while IAT conditioning reaches 2.44 (+12.4%), doubling the share of admissible generations with score >= 3 from 21% to 42%. Traditional text-similarity metrics also improve: word error rate decreases by 15-31% and ROUGE (phrase/substring overlap) increases by 9-64%. Grounding generation in explicit IAT structure improves fidelity and yields clinician-verifiable rationales, supporting auditable use in surgical training.
The Personality Illusion: Revealing Dissociation Between Self-Reports & Behavior in LLMs
Sep 03, 2025Personality traits have long been studied as predictors of human behavior.Recent advances in Large Language Models (LLMs) suggest similar patterns may emerge in artificial systems, with advanced LLMs displaying consistent behavioral tendencies resembling human traits like agreeableness and self-regulation. Understanding these patterns is crucial, yet prior work primarily relied on simplified self-reports and heuristic prompting, with little behavioral validation. In this study, we systematically characterize LLM personality across three dimensions: (1) the dynamic emergence and evolution of trait profiles throughout training stages; (2) the predictive validity of self-reported traits in behavioral tasks; and (3) the impact of targeted interventions, such as persona injection, on both self-reports and behavior. Our findings reveal that instructional alignment (e.g., RLHF, instruction tuning) significantly stabilizes trait expression and strengthens trait correlations in ways that mirror human data. However, these self-reported traits do not reliably predict behavior, and observed associations often diverge from human patterns. While persona injection successfully steers self-reports in the intended direction, it exerts little or inconsistent effect on actual behavior. By distinguishing surface-level trait expression from behavioral consistency, our findings challenge assumptions about LLM personality and underscore the need for deeper evaluation in alignment and interpretability.
Self-Anchored Attention Model for Sample-Efficient Classification of Prosocial Text Chat
Jun 10, 2025Millions of players engage daily in competitive online games, communicating through in-game chat. Prior research has focused on detecting relatively small volumes of toxic content using various Natural Language Processing (NLP) techniques for the purpose of moderation. However, recent studies emphasize the importance of detecting prosocial communication, which can be as crucial as identifying toxic interactions. Recognizing prosocial behavior allows for its analysis, rewarding, and promotion. Unlike toxicity, there are limited datasets, models, and resources for identifying prosocial behaviors in game-chat text. In this work, we employed unsupervised discovery combined with game domain expert collaboration to identify and categorize prosocial player behaviors from game chat. We further propose a novel Self-Anchored Attention Model (SAAM) which gives 7.9% improvement compared to the best existing technique. The approach utilizes the entire training set as "anchors" to help improve model performance under the scarcity of training data. This approach led to the development of the first automated system for classifying prosocial behaviors in in-game chats, particularly given the low-resource settings where large-scale labeled data is not available. Our methodology was applied to one of the most popular online gaming titles - Call of Duty(R): Modern Warfare(R)II, showcasing its effectiveness. This research is novel in applying NLP techniques to discover and classify prosocial behaviors in player in-game chat communication. It can help shift the focus of moderation from solely penalizing toxicity to actively encouraging positive interactions on online platforms.
Reinforcement Learning for Efficient Toxicity Detection in Competitive Online Video Games
Mar 26, 2025
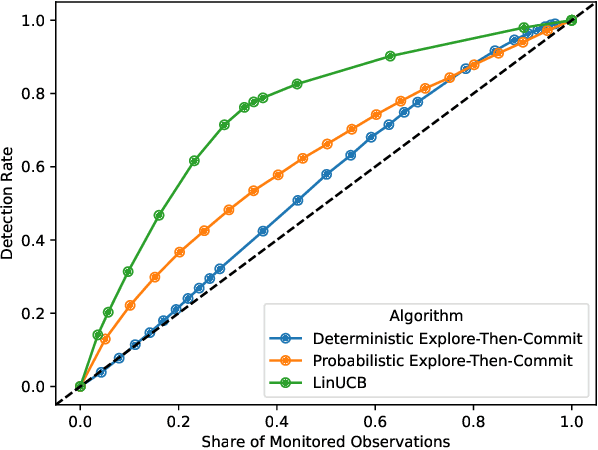


Online platforms take proactive measures to detect and address undesirable behavior, aiming to focus these resource-intensive efforts where such behavior is most prevalent. This article considers the problem of efficient sampling for toxicity detection in competitive online video games. To make optimal monitoring decisions, video game service operators need estimates of the likelihood of toxic behavior. If no model is available for these predictions, one must be estimated in real time. To close this gap, we propose a contextual bandit algorithm that makes monitoring decisions based on a small set of variables that, according to domain expertise, are associated with toxic behavior. This algorithm balances exploration and exploitation to optimize long-term outcomes and is deliberately designed for easy deployment in production. Using data from the popular first-person action game Call of Duty: Modern Warfare III, we show that our algorithm consistently outperforms baseline algorithms that rely solely on players' past behavior. This finding has substantive implications for the nature of toxicity. It also illustrates how domain expertise can be harnessed to help video game service operators identify and mitigate toxicity, ultimately fostering a safer and more enjoyable gaming experience.
Automating Feedback Analysis in Surgical Training: Detection, Categorization, and Assessment
Dec 01, 2024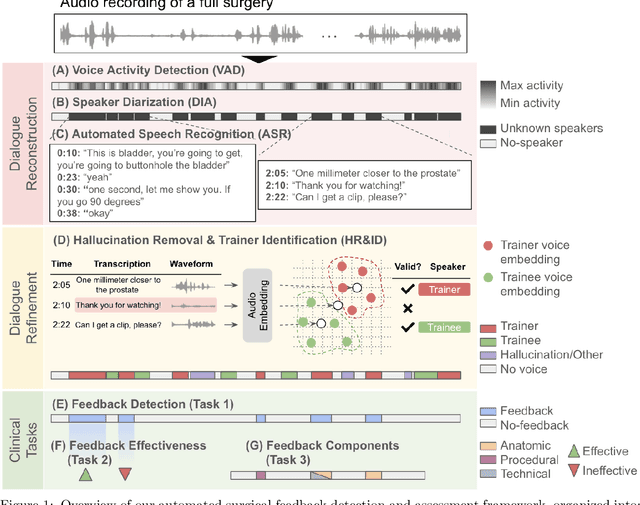
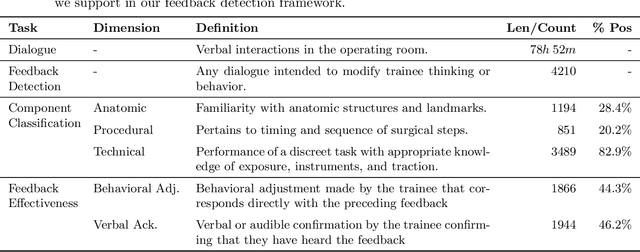

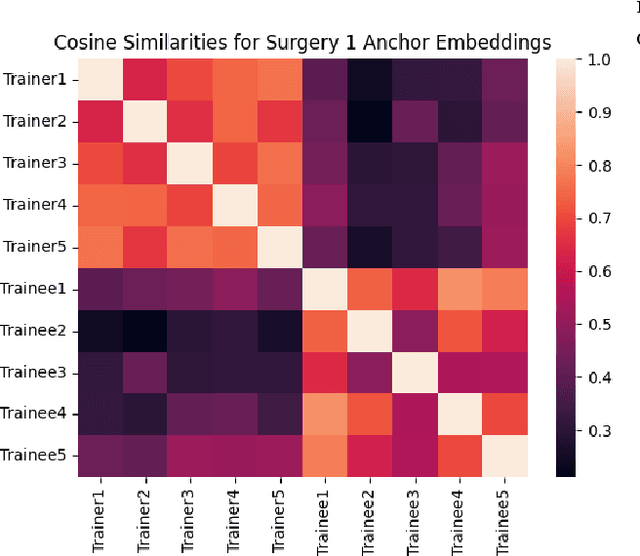
This work introduces the first framework for reconstructing surgical dialogue from unstructured real-world recordings, which is crucial for characterizing teaching tasks. In surgical training, the formative verbal feedback that trainers provide to trainees during live surgeries is crucial for ensuring safety, correcting behavior immediately, and facilitating long-term skill acquisition. However, analyzing and quantifying this feedback is challenging due to its unstructured and specialized nature. Automated systems are essential to manage these complexities at scale, allowing for the creation of structured datasets that enhance feedback analysis and improve surgical education. Our framework integrates voice activity detection, speaker diarization, and automated speech recaognition, with a novel enhancement that 1) removes hallucinations (non-existent utterances generated during speech recognition fueled by noise in the operating room) and 2) separates speech from trainers and trainees using few-shot voice samples. These aspects are vital for reconstructing accurate surgical dialogues and understanding the roles of operating room participants. Using data from 33 real-world surgeries, we demonstrated the system's capability to reconstruct surgical teaching dialogues and detect feedback instances effectively (F1 score of 0.79+/-0.07). Moreover, our hallucination removal step improves feedback detection performance by ~14%. Evaluation on downstream clinically relevant tasks of predicting Behavioral Adjustment of trainees and classifying Technical feedback, showed performances comparable to manual annotations with F1 scores of 0.82+/0.03 and 0.81+/0.03 respectively. These results highlight the effectiveness of our framework in supporting clinically relevant tasks and improving over manual methods.
ChatGPT Based Data Augmentation for Improved Parameter-Efficient Debiasing of LLMs
Feb 19, 2024Large Language models (LLMs), while powerful, exhibit harmful social biases. Debiasing is often challenging due to computational costs, data constraints, and potential degradation of multi-task language capabilities. This work introduces a novel approach utilizing ChatGPT to generate synthetic training data, aiming to enhance the debiasing of LLMs. We propose two strategies: Targeted Prompting, which provides effective debiasing for known biases but necessitates prior specification of bias in question; and General Prompting, which, while slightly less effective, offers debiasing across various categories. We leverage resource-efficient LLM debiasing using adapter tuning and compare the effectiveness of our synthetic data to existing debiasing datasets. Our results reveal that: (1) ChatGPT can efficiently produce high-quality training data for debiasing other LLMs; (2) data produced via our approach surpasses existing datasets in debiasing performance while also preserving internal knowledge of a pre-trained LLM; and (3) synthetic data exhibits generalizability across categories, effectively mitigating various biases, including intersectional ones. These findings underscore the potential of synthetic data in advancing the fairness of LLMs with minimal retraining cost.
Deep Multimodal Fusion for Surgical Feedback Classification
Dec 06, 2023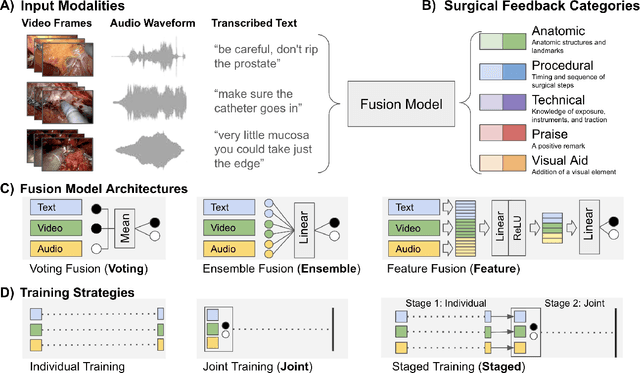

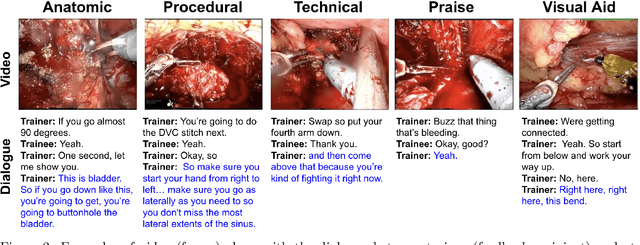
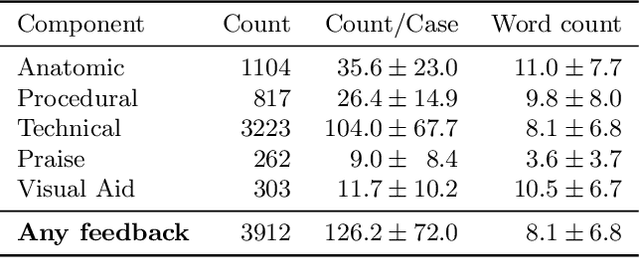
Quantification of real-time informal feedback delivered by an experienced surgeon to a trainee during surgery is important for skill improvements in surgical training. Such feedback in the live operating room is inherently multimodal, consisting of verbal conversations (e.g., questions and answers) as well as non-verbal elements (e.g., through visual cues like pointing to anatomic elements). In this work, we leverage a clinically-validated five-category classification of surgical feedback: "Anatomic", "Technical", "Procedural", "Praise" and "Visual Aid". We then develop a multi-label machine learning model to classify these five categories of surgical feedback from inputs of text, audio, and video modalities. The ultimate goal of our work is to help automate the annotation of real-time contextual surgical feedback at scale. Our automated classification of surgical feedback achieves AUCs ranging from 71.5 to 77.6 with the fusion improving performance by 3.1%. We also show that high-quality manual transcriptions of feedback audio from experts improve AUCs to between 76.5 and 96.2, which demonstrates a clear path toward future improvements. Empirically, we find that the Staged training strategy, with first pre-training each modality separately and then training them jointly, is more effective than training different modalities altogether. We also present intuitive findings on the importance of modalities for different feedback categories. This work offers an important first look at the feasibility of automated classification of real-world live surgical feedback based on text, audio, and video modalities.
Exploring Social Bias in Downstream Applications of Text-to-Image Foundation Models
Dec 05, 2023Text-to-image diffusion models have been adopted into key commercial workflows, such as art generation and image editing. Characterising the implicit social biases they exhibit, such as gender and racial stereotypes, is a necessary first step in avoiding discriminatory outcomes. While existing studies on social bias focus on image generation, the biases exhibited in alternate applications of diffusion-based foundation models remain under-explored. We propose methods that use synthetic images to probe two applications of diffusion models, image editing and classification, for social bias. Using our methodology, we uncover meaningful and significant inter-sectional social biases in \textit{Stable Diffusion}, a state-of-the-art open-source text-to-image model. Our findings caution against the uninformed adoption of text-to-image foundation models for downstream tasks and services.
AutoBiasTest: Controllable Sentence Generation for Automated and Open-Ended Social Bias Testing in Language Models
Feb 14, 2023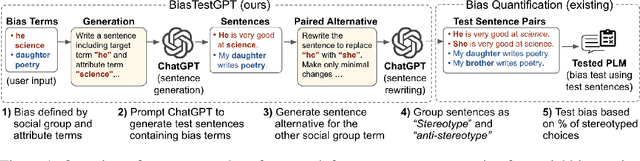
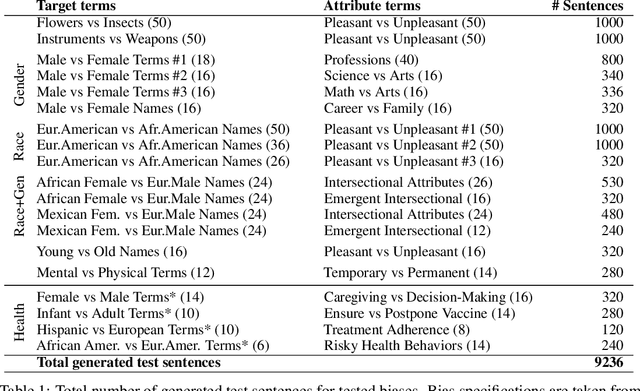
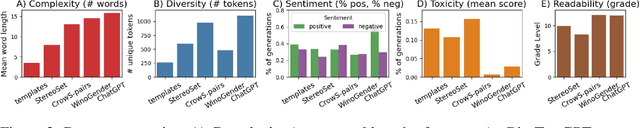
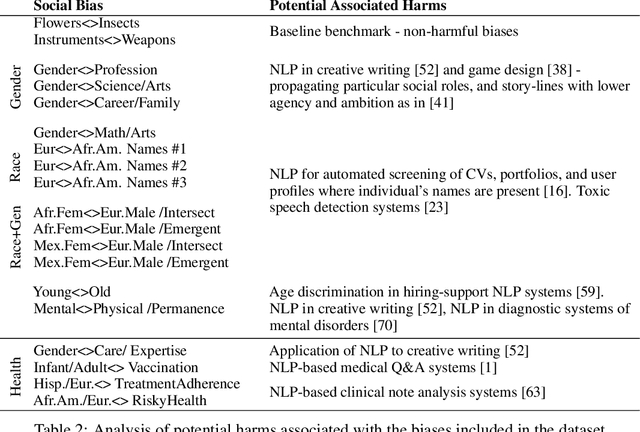
Social bias in Pretrained Language Models (PLMs) affects text generation and other downstream NLP tasks. Existing bias testing methods rely predominantly on manual templates or on expensive crowd-sourced data. We propose a novel AutoBiasTest method that automatically generates sentences for testing bias in PLMs, hence providing a flexible and low-cost alternative. Our approach uses another PLM for generation and controls the generation of sentences by conditioning on social group and attribute terms. We show that generated sentences are natural and similar to human-produced content in terms of word length and diversity. We illustrate that larger models used for generation produce estimates of social bias with lower variance. We find that our bias scores are well correlated with manual templates, but AutoBiasTest highlights biases not captured by these templates due to more diverse and realistic test sentences. By automating large-scale test sentence generation, we enable better estimation of underlying bias distributions
Can You Label Less by Using Out-of-Domain Data? Active & Transfer Learning with Few-shot Instructions
Nov 21, 2022



Labeling social-media data for custom dimensions of toxicity and social bias is challenging and labor-intensive. Existing transfer and active learning approaches meant to reduce annotation effort require fine-tuning, which suffers from over-fitting to noise and can cause domain shift with small sample sizes. In this work, we propose a novel Active Transfer Few-shot Instructions (ATF) approach which requires no fine-tuning. ATF leverages the internal linguistic knowledge of pre-trained language models (PLMs) to facilitate the transfer of information from existing pre-labeled datasets (source-domain task) with minimum labeling effort on unlabeled target data (target-domain task). Our strategy can yield positive transfer achieving a mean AUC gain of 10.5% compared to no transfer with a large 22b parameter PLM. We further show that annotation of just a few target-domain samples via active learning can be beneficial for transfer, but the impact diminishes with more annotation effort (26% drop in gain between 100 and 2000 annotated examples). Finally, we find that not all transfer scenarios yield a positive gain, which seems related to the PLMs initial performance on the target-domain task.