 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenAI for Systems: Recurring Challenges and Design Principles from Software to Silicon
Feb 16, 2026Generative AI is reshaping how computing systems are designed, optimized, and built, yet research remains fragmented across software, architecture, and chip design communities. This paper takes a cross-stack perspective, examining how generative models are being applied from code generation and distributed runtimes through hardware design space exploration to RTL synthesis, physical layout, and verification. Rather than reviewing each layer in isolation, we analyze how the same structural difficulties and effective responses recur across the stack. Our central finding is one of convergence. Despite the diversity of domains and tools, the field keeps encountering five recurring challenges (the feedback loop crisis, the tacit knowledge problem, trust and validation, co-design across boundaries, and the shift from determinism to dynamism) and keeps arriving at five design principles that independently emerge as effective responses (embracing hybrid approaches, designing for continuous feedback, separating concerns by role, matching methods to problem structure, and building on decades of systems knowledge). We organize these into a challenge--principle map that serves as a diagnostic and design aid, showing which principles have proven effective for which challenges across layers. Through concrete cross-stack examples, we show how systems navigate this map as they mature, and argue that the field needs shared engineering methodology, including common vocabularies, cross-layer benchmarks, and systematic design practices, so that progress compounds across communities rather than being rediscovered in each one. Our analysis covers more than 275 papers spanning eleven application areas across three layers of the computing stack, and distills open research questions that become visible only from a cross-layer vantage point.
Inverse Depth Scaling From Most Layers Being Similar
Feb 05, 2026Neural scaling laws relate loss to model size in large language models (LLMs), yet depth and width may contribute to performance differently, requiring more detailed studies. Here, we quantify how depth affects loss via analysis of LLMs and toy residual networks. We find loss scales inversely proportional to depth in LLMs, probably due to functionally similar layers reducing error through ensemble averaging rather than compositional learning or discretizing smooth dynamics. This regime is inefficient yet robust and may arise from the architectural bias of residual networks and target functions incompatible with smooth dynamics. The findings suggest that improving LLM efficiency may require architectural innovations to encourage compositional use of depth.
Analyzing Political Text at Scale with Online Tensor LDA
Nov 11, 2025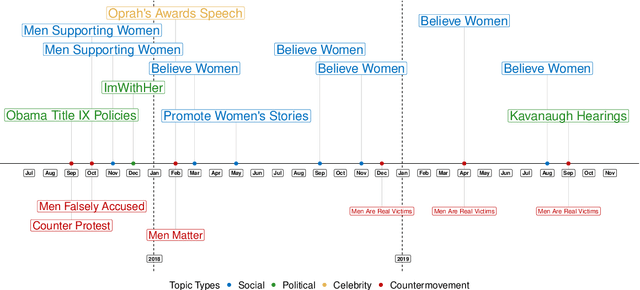

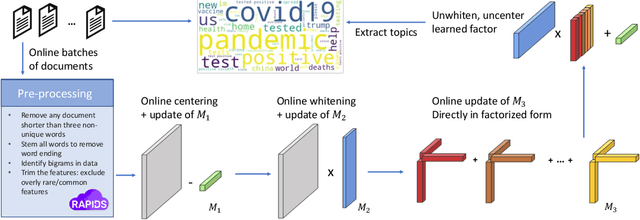
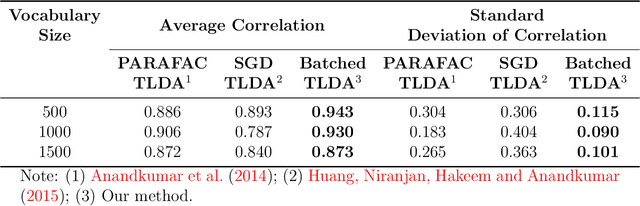
This paper proposes a topic modeling method that scales linearly to billions of documents. We make three core contributions: i) we present a topic modeling method, Tensor Latent Dirichlet Allocation (TLDA), that has identifiable and recoverable parameter guarantees and sample complexity guarantees for large data; ii) we show that this method is computationally and memory efficient (achieving speeds over 3-4x those of prior parallelized Latent Dirichlet Allocation (LDA) methods), and that it scales linearly to text datasets with over a billion documents; iii) we provide an open-source, GPU-based implementation, of this method. This scaling enables previously prohibitive analyses, and we perform two real-world, large-scale new studies of interest to political scientists: we provide the first thorough analysis of the evolution of the #MeToo movement through the lens of over two years of Twitter conversation and a detailed study of social media conversations about election fraud in the 2020 presidential election. Thus this method provides social scientists with the ability to study very large corpora at scale and to answer important theoretically-relevant questions about salient issues in near real-time.
Boomerang Distillation Enables Zero-Shot Model Size Interpolation
Oct 06, 2025Large language models (LLMs) are typically deployed under diverse memory and compute constraints. Existing approaches build model families by training each size independently, which is prohibitively expensive and provides only coarse-grained size options. In this work, we identify a novel phenomenon that we call boomerang distillation: starting from a large base model (the teacher), one first distills down to a small student and then progressively reconstructs intermediate-sized models by re-incorporating blocks of teacher layers into the student without any additional training. This process produces zero-shot interpolated models of many intermediate sizes whose performance scales smoothly between the student and teacher, often matching or surpassing pretrained or distilled models of the same size. We further analyze when this type of interpolation succeeds, showing that alignment between teacher and student through pruning and distillation is essential. Boomerang distillation thus provides a simple and efficient way to generate fine-grained model families, dramatically reducing training cost while enabling flexible adaptation across deployment environments. The code and models are available at https://github.com/dcml-lab/boomerang-distillation.
Fast Forwarding Low-Rank Training
Sep 06, 2024



Parameter efficient finetuning methods like low-rank adaptation (LoRA) aim to reduce the computational costs of finetuning pretrained Language Models (LMs). Enabled by these low-rank settings, we propose an even more efficient optimization strategy: Fast Forward, a simple and effective approach to accelerate large segments of training. In a Fast Forward stage, we repeat the most recent optimizer step until the loss stops improving on a tiny validation set. By alternating between regular optimization steps and Fast Forward stages, Fast Forward provides up to an 87\% reduction in FLOPs and up to an 81\% reduction in train time over standard SGD with Adam. We validate Fast Forward by finetuning various models on different tasks and demonstrate that it speeds up training without compromising model performance. Additionally, we analyze when and how to apply Fast Forward.
Continuous Language Model Interpolation for Dynamic and Controllable Text Generation
Apr 10, 2024As large language models (LLMs) have gained popularity for a variety of use cases, making them adaptable and controllable has become increasingly important, especially for user-facing applications. While the existing literature on LLM adaptation primarily focuses on finding a model (or models) that optimizes a single predefined objective, here we focus on the challenging case where the model must dynamically adapt to diverse -- and often changing -- user preferences. For this, we leverage adaptation methods based on linear weight interpolation, casting them as continuous multi-domain interpolators that produce models with specific prescribed generation characteristics on-the-fly. Specifically, we use low-rank updates to fine-tune a base model to various different domains, yielding a set of anchor models with distinct generation profiles. Then, we use the weight updates of these anchor models to parametrize the entire (infinite) class of models contained within their convex hull. We empirically show that varying the interpolation weights yields predictable and consistent change in the model outputs with respect to all of the controlled attributes. We find that there is little entanglement between most attributes and identify and discuss the pairs of attributes for which this is not the case. Our results suggest that linearly interpolating between the weights of fine-tuned models facilitates predictable, fine-grained control of model outputs with respect to multiple stylistic characteristics simultaneously.
Can You Label Less by Using Out-of-Domain Data? Active & Transfer Learning with Few-shot Instructions
Nov 21, 2022



Labeling social-media data for custom dimensions of toxicity and social bias is challenging and labor-intensive. Existing transfer and active learning approaches meant to reduce annotation effort require fine-tuning, which suffers from over-fitting to noise and can cause domain shift with small sample sizes. In this work, we propose a novel Active Transfer Few-shot Instructions (ATF) approach which requires no fine-tuning. ATF leverages the internal linguistic knowledge of pre-trained language models (PLMs) to facilitate the transfer of information from existing pre-labeled datasets (source-domain task) with minimum labeling effort on unlabeled target data (target-domain task). Our strategy can yield positive transfer achieving a mean AUC gain of 10.5% compared to no transfer with a large 22b parameter PLM. We further show that annotation of just a few target-domain samples via active learning can be beneficial for transfer, but the impact diminishes with more annotation effort (26% drop in gain between 100 and 2000 annotated examples). Finally, we find that not all transfer scenarios yield a positive gain, which seems related to the PLMs initial performance on the target-domain task.
Adaptive Sampling: Algorithmic vs. Human Waypoint Selection
Apr 24, 2021
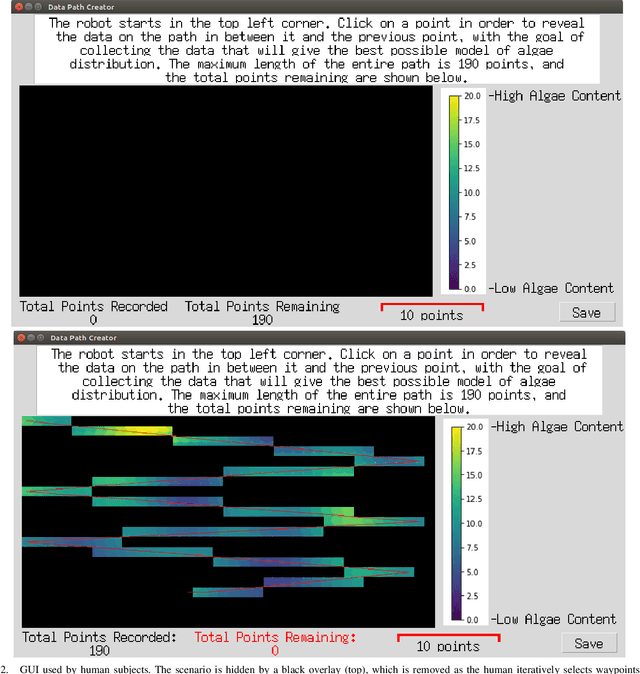
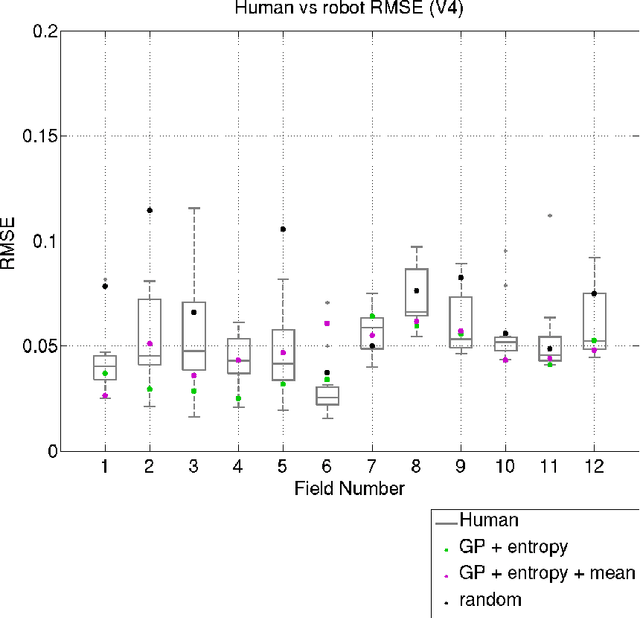
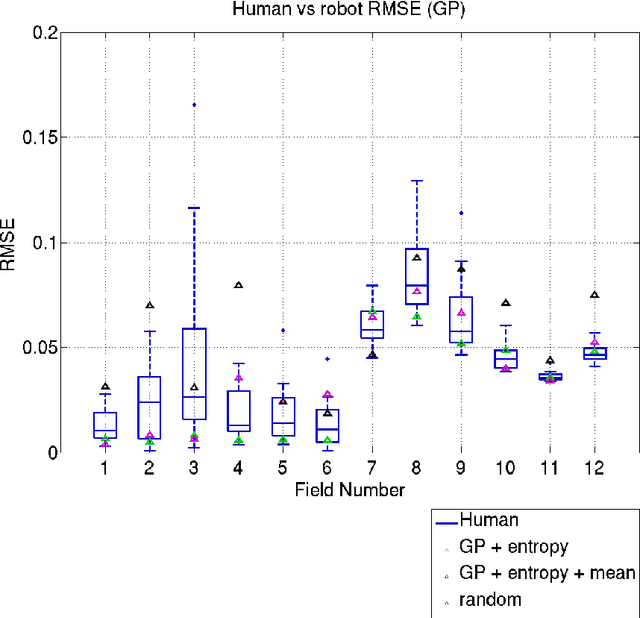
Robots are used for collecting samples from natural environments to create models of, for example, temperature or algae fields in the ocean. Adaptive informative sampling is a proven technique for this kind of spatial field modeling. This paper compares the performance of humans versus adaptive informative sampling algorithms for selecting informative waypoints. The humans and simulated robot are given the same information for selecting waypoints, and both are evaluated on the accuracy of the resulting model. We developed a graphical user interface for selecting waypoints and visualizing samples. Eleven participants iteratively picked waypoints for twelve scenarios. Our simulated robot used Gaussian Process regression with two entropy-based optimization criteria to iteratively choose waypoints. Our results show that the robot can on average perform better than the average human, and approximately as good as the best human, when the model assumptions correspond to the actual field. However, when the model assumptions do not correspond as well to the characteristics of the field, both human and robot performance are no better than random sampling.