 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Psychometric Evaluation of LLMs: When and Why Self-Reports Predict Behavior
Jun 10, 2026Anticipating LLM behavioral tendencies from low-cost psychometric probes is critical for safe deployment, but only if self-reports (SR) reliably predict behavior. Recent work documented substantial SR-behavior dissociation in LLMs, but relied on broad personality traits (Big 5) that predict specific behaviors weakly, even in humans. Furthermore, the isolation of conversational sessions combined with weak context matching left open whether LLMs truly lack coherence or whether the conditions needed to detect such coherence were not met. We contrast Big 5 with the Theory of Planned Behavior (TPB), which measures intention targeted to a specific behavior and predicts human behavior substantially better than broad traits. We run experiments across four behavioral tasks and 11 frontier LLMs, while also varying session context and identity induction. We find that SR-behavior coherence exists but is selective. 1) Within a shared conversation, the Theory of Planned Behavior reaches human-level coherence; Big 5 does not. 2) Across separate conversations, coherence survives only for behaviors anchored outside the immediate prompt, such as implicit bias shaped by training, and collapses when behavior is strongly primed by context, as with sycophancy. 3) Persona prompting makes self-reports more consistent across conversations, but does not bring behavior into alignment. These findings suggest that coarse personality frameworks, such as Big 5 may not be the best tools for testing deployment behavior. More task- and behavior-specific instruments are needed, and even these must be evaluated across tasks and contexts.
On the Limits of LLM Adaptability: Impact of Model-Internalized Priors on Annotation Task Performance
May 30, 2026Large Language Models (LLMs) are increasingly used for zero-shot annotation and LLM-as-a-judge tasks, yet their reliability hinges on how model-internalized priors interact with user-provided instructions. We investigate three dimensions of this interaction: (1) how an LLM's familiarity with data and task definitions affects performance, (2) the extent to which additional information in prompts can correct zero-shot errors ("decision stickiness"), and (3) model susceptibility to misaligned task definitions. Through experiments on toxicity detection across diverse datasets (spanning social media, gaming, news, and forums) using both dense and mixture-of-experts models, we find that nearly two-thirds of zero-shot errors are resistant to correction, with an overall rescue rate (fraction of initial errors corrected by prompting) of only 34.8%. High-confidence errors prove especially resistant to correction. When given misaligned definitions, LLMs follow them while maintaining confidence levels unchanged from the aligned condition. Crucially, we introduce Definition-Specific Familiarity (DSF), which measures alignment between a model's internal concept and the task definition. After controlling for dataset-level confounds, DSF shows a positive association with model performance (partial r = +0.41), while three distinct memorization metrics (ROUGE-L, BERTScore, and embedding cosine similarity) all fail to show a positive association. These findings show the limitations of prompt-based correction in annotation tasks, highlighting the importance of definition alignment over text-level memorization.
Beyond the "Truth": Investigating Election Rumors on Truth Social During the 2024 Election
Jan 08, 2026Large language models (LLMs) offer unprecedented opportunities for analyzing social phenomena at scale. This paper demonstrates the value of LLMs in psychological measurement by (1) compiling the first large-scale dataset of election rumors on a niche alt-tech platform, (2) developing a multistage Rumor Detection Agent that leverages LLMs for high-precision content classification, and (3) quantifying the psychological dynamics of rumor propagation, specifically the "illusory truth effect" in a naturalistic setting. The Rumor Detection Agent combines (i) a synthetic data-augmented, fine-tuned RoBERTa classifier, (ii) precision keyword filtering, and (iii) a two-pass LLM verification pipeline using GPT-4o mini. The findings reveal that sharing probability rises steadily with each additional exposure, providing large-scale empirical evidence for dose-response belief reinforcement in ideologically homogeneous networks. Simulation results further demonstrate rapid contagion effects: nearly one quarter of users become "infected" within just four propagation iterations. Taken together, these results illustrate how LLMs can transform psychological science by enabling the rigorous measurement of belief dynamics and misinformation spread in massive, real-world datasets.
Analyzing Political Text at Scale with Online Tensor LDA
Nov 11, 2025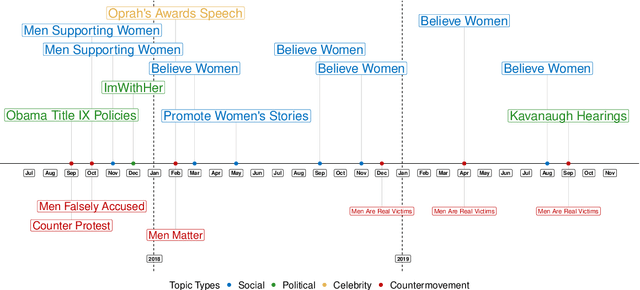

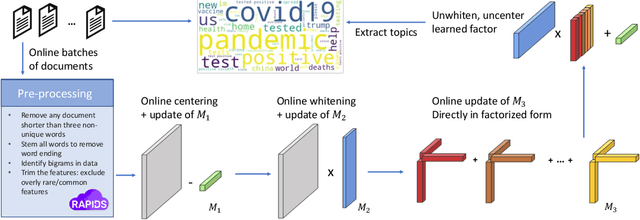
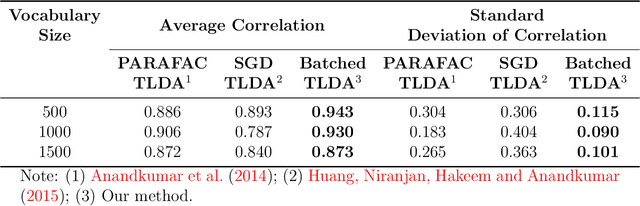
This paper proposes a topic modeling method that scales linearly to billions of documents. We make three core contributions: i) we present a topic modeling method, Tensor Latent Dirichlet Allocation (TLDA), that has identifiable and recoverable parameter guarantees and sample complexity guarantees for large data; ii) we show that this method is computationally and memory efficient (achieving speeds over 3-4x those of prior parallelized Latent Dirichlet Allocation (LDA) methods), and that it scales linearly to text datasets with over a billion documents; iii) we provide an open-source, GPU-based implementation, of this method. This scaling enables previously prohibitive analyses, and we perform two real-world, large-scale new studies of interest to political scientists: we provide the first thorough analysis of the evolution of the #MeToo movement through the lens of over two years of Twitter conversation and a detailed study of social media conversations about election fraud in the 2020 presidential election. Thus this method provides social scientists with the ability to study very large corpora at scale and to answer important theoretically-relevant questions about salient issues in near real-time.
The Personality Illusion: Revealing Dissociation Between Self-Reports & Behavior in LLMs
Sep 03, 2025Personality traits have long been studied as predictors of human behavior.Recent advances in Large Language Models (LLMs) suggest similar patterns may emerge in artificial systems, with advanced LLMs displaying consistent behavioral tendencies resembling human traits like agreeableness and self-regulation. Understanding these patterns is crucial, yet prior work primarily relied on simplified self-reports and heuristic prompting, with little behavioral validation. In this study, we systematically characterize LLM personality across three dimensions: (1) the dynamic emergence and evolution of trait profiles throughout training stages; (2) the predictive validity of self-reported traits in behavioral tasks; and (3) the impact of targeted interventions, such as persona injection, on both self-reports and behavior. Our findings reveal that instructional alignment (e.g., RLHF, instruction tuning) significantly stabilizes trait expression and strengthens trait correlations in ways that mirror human data. However, these self-reported traits do not reliably predict behavior, and observed associations often diverge from human patterns. While persona injection successfully steers self-reports in the intended direction, it exerts little or inconsistent effect on actual behavior. By distinguishing surface-level trait expression from behavioral consistency, our findings challenge assumptions about LLM personality and underscore the need for deeper evaluation in alignment and interpretability.
Self-Anchored Attention Model for Sample-Efficient Classification of Prosocial Text Chat
Jun 10, 2025Millions of players engage daily in competitive online games, communicating through in-game chat. Prior research has focused on detecting relatively small volumes of toxic content using various Natural Language Processing (NLP) techniques for the purpose of moderation. However, recent studies emphasize the importance of detecting prosocial communication, which can be as crucial as identifying toxic interactions. Recognizing prosocial behavior allows for its analysis, rewarding, and promotion. Unlike toxicity, there are limited datasets, models, and resources for identifying prosocial behaviors in game-chat text. In this work, we employed unsupervised discovery combined with game domain expert collaboration to identify and categorize prosocial player behaviors from game chat. We further propose a novel Self-Anchored Attention Model (SAAM) which gives 7.9% improvement compared to the best existing technique. The approach utilizes the entire training set as "anchors" to help improve model performance under the scarcity of training data. This approach led to the development of the first automated system for classifying prosocial behaviors in in-game chats, particularly given the low-resource settings where large-scale labeled data is not available. Our methodology was applied to one of the most popular online gaming titles - Call of Duty(R): Modern Warfare(R)II, showcasing its effectiveness. This research is novel in applying NLP techniques to discover and classify prosocial behaviors in player in-game chat communication. It can help shift the focus of moderation from solely penalizing toxicity to actively encouraging positive interactions on online platforms.
Context-Aware Toxicity Detection in Multiplayer Games: Integrating Domain-Adaptive Pretraining and Match Metadata
Apr 02, 2025The detrimental effects of toxicity in competitive online video games are widely acknowledged, prompting publishers to monitor player chat conversations. This is challenging due to the context-dependent nature of toxicity, often spread across multiple messages or informed by non-textual interactions. Traditional toxicity detectors focus on isolated messages, missing the broader context needed for accurate moderation. This is especially problematic in video games, where interactions involve specialized slang, abbreviations, and typos, making it difficult for standard models to detect toxicity, especially given its rarity. We adapted RoBERTa LLM to support moderation tailored to video games, integrating both textual and non-textual context. By enhancing pretrained embeddings with metadata and addressing the unique slang and language quirks through domain adaptive pretraining, our method better captures the nuances of player interactions. Using two gaming datasets - from Defense of the Ancients 2 (DOTA 2) and Call of Duty$^\circledR$: Modern Warfare$^\circledR$III (MWIII) we demonstrate which sources of context (metadata, prior interactions...) are most useful, how to best leverage them to boost performance, and the conditions conducive to doing so. This work underscores the importance of context-aware and domain-specific approaches for proactive moderation.
Reinforcement Learning for Efficient Toxicity Detection in Competitive Online Video Games
Mar 26, 2025
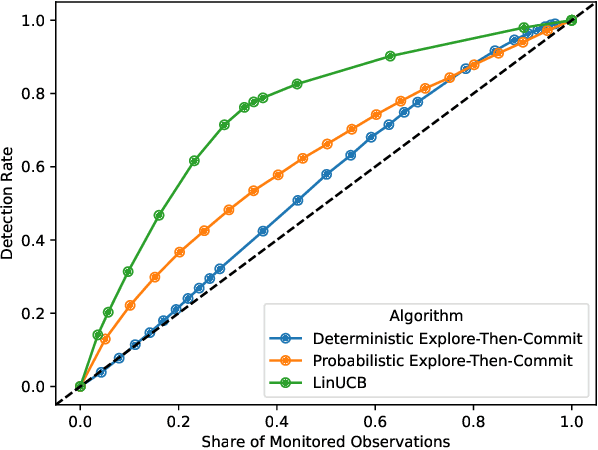


Online platforms take proactive measures to detect and address undesirable behavior, aiming to focus these resource-intensive efforts where such behavior is most prevalent. This article considers the problem of efficient sampling for toxicity detection in competitive online video games. To make optimal monitoring decisions, video game service operators need estimates of the likelihood of toxic behavior. If no model is available for these predictions, one must be estimated in real time. To close this gap, we propose a contextual bandit algorithm that makes monitoring decisions based on a small set of variables that, according to domain expertise, are associated with toxic behavior. This algorithm balances exploration and exploitation to optimize long-term outcomes and is deliberately designed for easy deployment in production. Using data from the popular first-person action game Call of Duty: Modern Warfare III, we show that our algorithm consistently outperforms baseline algorithms that rely solely on players' past behavior. This finding has substantive implications for the nature of toxicity. It also illustrates how domain expertise can be harnessed to help video game service operators identify and mitigate toxicity, ultimately fostering a safer and more enjoyable gaming experience.
Deciphering public attention to geoengineering and climate issues using machine learning and dynamic analysis
May 11, 2024



As the conversation around using geoengineering to combat climate change intensifies, it is imperative to engage the public and deeply understand their perspectives on geoengineering research, development, and potential deployment. Through a comprehensive data-driven investigation, this paper explores the types of news that captivate public interest in geoengineering. We delved into 30,773 English-language news articles from the BBC and the New York Times, combined with Google Trends data spanning 2018 to 2022, to explore how public interest in geoengineering fluctuates in response to news coverage of broader climate issues. Using BERT-based topic modeling, sentiment analysis, and time-series regression models, we found that positive sentiment in energy-related news serves as a good predictor of heightened public interest in geoengineering, a trend that persists over time. Our findings suggest that public engagement with geoengineering and climate action is not uniform, with some topics being more potent in shaping interest over time, such as climate news related to energy, disasters, and politics. Understanding these patterns is crucial for scientists, policymakers, and educators aiming to craft effective strategies for engaging with the public and fostering dialogue around emerging climate technologies.
Physics-based deep learning reveals rising heating demand heightens air pollution in Norwegian cities
May 07, 2024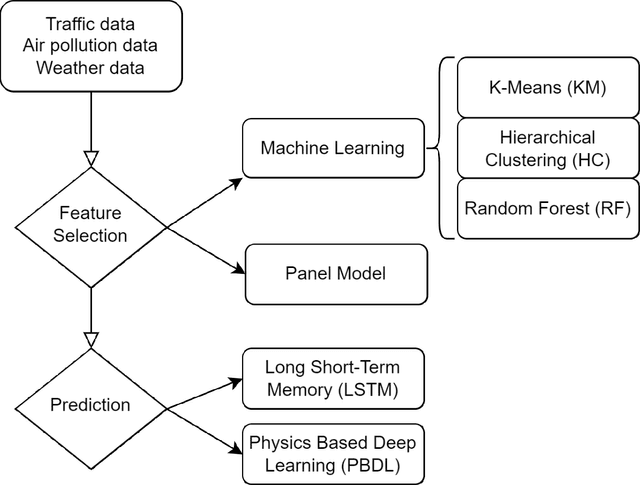
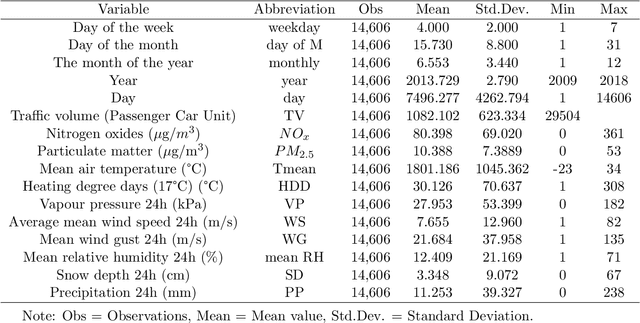
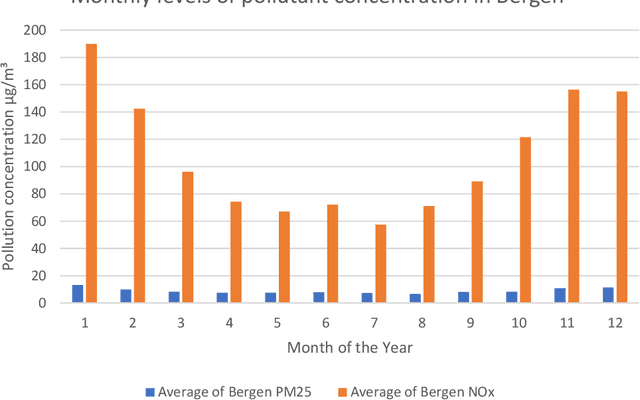
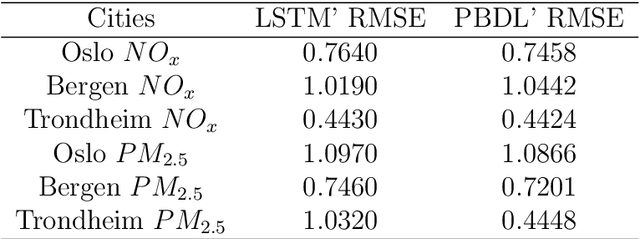
Policymakers frequently analyze air quality and climate change in isolation, disregarding their interactions. This study explores the influence of specific climate factors on air quality by contrasting a regression model with K-Means Clustering, Hierarchical Clustering, and Random Forest techniques. We employ Physics-based Deep Learning (PBDL) and Long Short-Term Memory (LSTM) to examine the air pollution predictions. Our analysis utilizes ten years (2009-2018) of daily traffic, weather, and air pollution data from three major cities in Norway. Findings from feature selection reveal a correlation between rising heating degree days and heightened air pollution levels, suggesting increased heating activities in Norway are a contributing factor to worsening air quality. PBDL demonstrates superior accuracy in air pollution predictions compared to LSTM. This paper contributes to the growing literature on PBDL methods for more accurate air pollution predictions using environmental variables, aiding policymakers in formulating effective data-driven climate policies.