 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow and Why LLMs Generalize: A Fine-Grained Analysis of LLM Reasoning from Cognitive Behaviors to Low-Level Patterns
Dec 30, 2025Large Language Models (LLMs) display strikingly different generalization behaviors: supervised fine-tuning (SFT) often narrows capability, whereas reinforcement-learning (RL) tuning tends to preserve it. The reasons behind this divergence remain unclear, as prior studies have largely relied on coarse accuracy metrics. We address this gap by introducing a novel benchmark that decomposes reasoning into atomic core skills such as calculation, fact retrieval, simulation, enumeration, and diagnostic, providing a concrete framework for addressing the fundamental question of what constitutes reasoning in LLMs. By isolating and measuring these core skills, the benchmark offers a more granular view of how specific cognitive abilities emerge, transfer, and sometimes collapse during post-training. Combined with analyses of low-level statistical patterns such as distributional divergence and parameter statistics, it enables a fine-grained study of how generalization evolves under SFT and RL across mathematical, scientific reasoning, and non-reasoning tasks. Our meta-probing framework tracks model behavior at different training stages and reveals that RL-tuned models maintain more stable behavioral profiles and resist collapse in reasoning skills, whereas SFT models exhibit sharper drift and overfit to surface patterns. This work provides new insights into the nature of reasoning in LLMs and points toward principles for designing training strategies that foster broad, robust generalization.
Adaptation of Agentic AI
Dec 22, 2025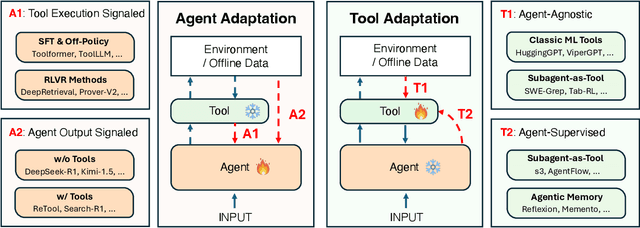
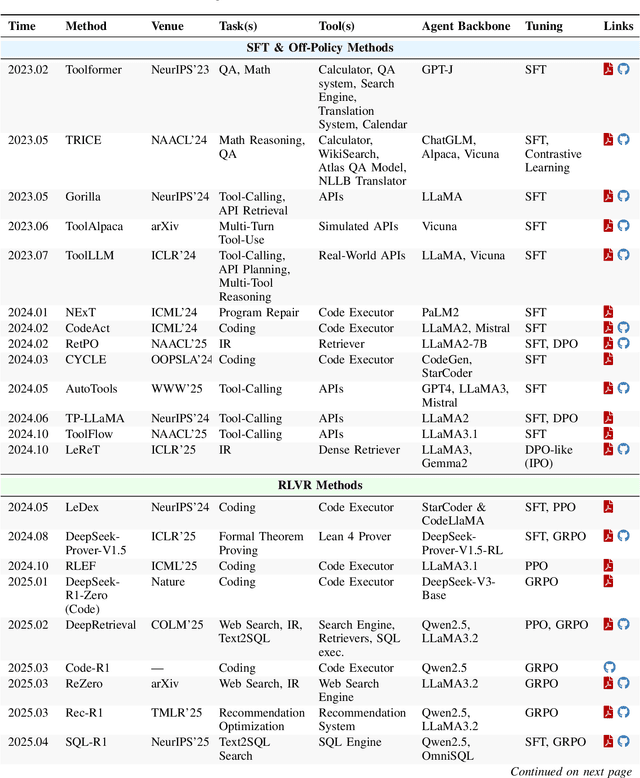
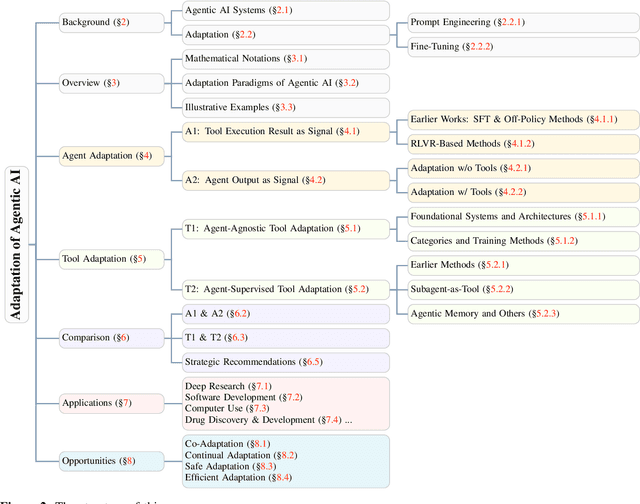
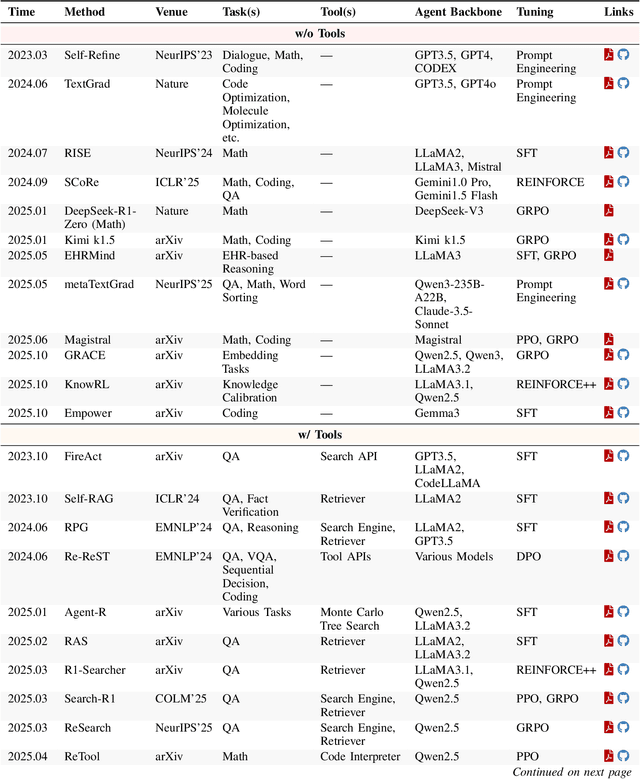
Cutting-edge agentic AI systems are built on foundation models that can be adapted to plan, reason, and interact with external tools to perform increasingly complex and specialized tasks. As these systems grow in capability and scope, adaptation becomes a central mechanism for improving performance, reliability, and generalization. In this paper, we unify the rapidly expanding research landscape into a systematic framework that spans both agent adaptations and tool adaptations. We further decompose these into tool-execution-signaled and agent-output-signaled forms of agent adaptation, as well as agent-agnostic and agent-supervised forms of tool adaptation. We demonstrate that this framework helps clarify the design space of adaptation strategies in agentic AI, makes their trade-offs explicit, and provides practical guidance for selecting or switching among strategies during system design. We then review the representative approaches in each category, analyze their strengths and limitations, and highlight key open challenges and future opportunities. Overall, this paper aims to offer a conceptual foundation and practical roadmap for researchers and practitioners seeking to build more capable, efficient, and reliable agentic AI systems.
The Personality Illusion: Revealing Dissociation Between Self-Reports & Behavior in LLMs
Sep 03, 2025Personality traits have long been studied as predictors of human behavior.Recent advances in Large Language Models (LLMs) suggest similar patterns may emerge in artificial systems, with advanced LLMs displaying consistent behavioral tendencies resembling human traits like agreeableness and self-regulation. Understanding these patterns is crucial, yet prior work primarily relied on simplified self-reports and heuristic prompting, with little behavioral validation. In this study, we systematically characterize LLM personality across three dimensions: (1) the dynamic emergence and evolution of trait profiles throughout training stages; (2) the predictive validity of self-reported traits in behavioral tasks; and (3) the impact of targeted interventions, such as persona injection, on both self-reports and behavior. Our findings reveal that instructional alignment (e.g., RLHF, instruction tuning) significantly stabilizes trait expression and strengthens trait correlations in ways that mirror human data. However, these self-reported traits do not reliably predict behavior, and observed associations often diverge from human patterns. While persona injection successfully steers self-reports in the intended direction, it exerts little or inconsistent effect on actual behavior. By distinguishing surface-level trait expression from behavioral consistency, our findings challenge assumptions about LLM personality and underscore the need for deeper evaluation in alignment and interpretability.
LeanProgress: Guiding Search for Neural Theorem Proving via Proof Progress Prediction
Feb 25, 2025Mathematical reasoning remains a significant challenge for Large Language Models (LLMs) due to hallucinations. When combined with formal proof assistants like Lean, these hallucinations can be eliminated through rigorous verification, making theorem proving reliable. However, even with formal verification, LLMs still struggle with long proofs and complex mathematical formalizations. While Lean with LLMs offers valuable assistance with retrieving lemmas, generating tactics, or even complete proofs, it lacks a crucial capability: providing a sense of proof progress. This limitation particularly impacts the overall development efficiency in large formalization projects. We introduce LeanProgress, a method that predicts the progress in the proof. Training and evaluating our models made on a large corpus of Lean proofs from Lean Workbook Plus and Mathlib4 and how many steps remain to complete it, we employ data preprocessing and balancing techniques to handle the skewed distribution of proof lengths. Our experiments show that LeanProgress achieves an overall prediction accuracy of 75.1\% in predicting the amount of progress and, hence, the remaining number of steps. When integrated into a best-first search framework using Reprover, our method shows a 3.8\% improvement on Mathlib4 compared to baseline performances of 41.2\%, particularly for longer proofs. These results demonstrate how proof progress prediction can enhance both automated and interactive theorem proving, enabling users to make more informed decisions about proof strategies.
LeanAgent: Lifelong Learning for Formal Theorem Proving
Oct 08, 2024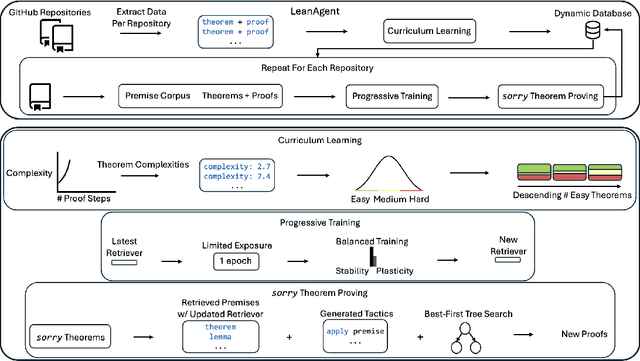
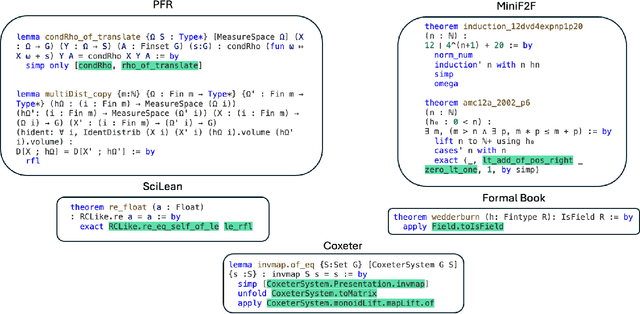
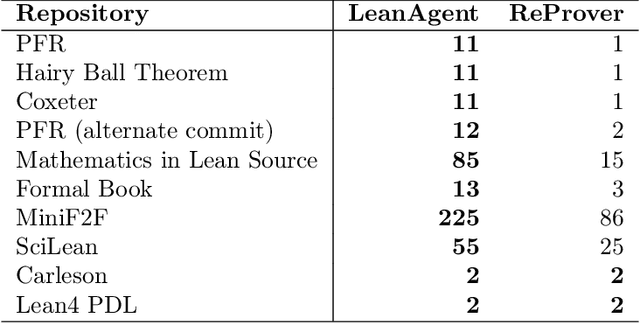
Large Language Models (LLMs) have been successful in mathematical reasoning tasks such as formal theorem proving when integrated with interactive proof assistants like Lean. Existing approaches involve training or fine-tuning an LLM on a specific dataset to perform well on particular domains, such as undergraduate-level mathematics. These methods struggle with generalizability to advanced mathematics. A fundamental limitation is that these approaches operate on static domains, failing to capture how mathematicians often work across multiple domains and projects simultaneously or cyclically. We present LeanAgent, a novel lifelong learning framework for theorem proving that continuously generalizes to and improves on ever-expanding mathematical knowledge without forgetting previously learned knowledge. LeanAgent introduces several key innovations, including a curriculum learning strategy that optimizes the learning trajectory in terms of mathematical difficulty, a dynamic database for efficient management of evolving mathematical knowledge, and progressive training to balance stability and plasticity. LeanAgent successfully proves 162 theorems previously unproved by humans across 23 diverse Lean repositories, many from advanced mathematics. It performs up to 11$\times$ better than the static LLM baseline, proving challenging theorems in domains like abstract algebra and algebraic topology while showcasing a clear progression of learning from basic concepts to advanced topics. In addition, we analyze LeanAgent's superior performance on key lifelong learning metrics. LeanAgent achieves exceptional scores in stability and backward transfer, where learning new tasks improves performance on previously learned tasks. This emphasizes LeanAgent's continuous generalizability and improvement, explaining its superior theorem proving performance.
Creative and Context-Aware Translation of East Asian Idioms with GPT-4
Oct 01, 2024As a type of figurative language, an East Asian idiom condenses rich cultural background into only a few characters. Translating such idioms is challenging for human translators, who often resort to choosing a context-aware translation from an existing list of candidates. However, compiling a dictionary of candidate translations demands much time and creativity even for expert translators. To alleviate such burden, we evaluate if GPT-4 can help generate high-quality translations. Based on automatic evaluations of faithfulness and creativity, we first identify Pareto-optimal prompting strategies that can outperform translation engines from Google and DeepL. Then, at a low cost, our context-aware translations can achieve far more high-quality translations per idiom than the human baseline. We open-source all code and data to facilitate further research.
Towards Large Language Models as Copilots for Theorem Proving in Lean
Apr 18, 2024Theorem proving is an important challenge for large language models (LLMs), as formal proofs can be checked rigorously by proof assistants such as Lean, leaving no room for hallucination. Existing LLM-based provers try to prove theorems in a fully autonomous mode without human intervention. In this mode, they struggle with novel and challenging theorems, for which human insights may be critical. In this paper, we explore LLMs as copilots that assist humans in proving theorems. We introduce Lean Copilot, a framework for running LLM inference in Lean. It enables programmers to build various LLM-based proof automation tools that integrate seamlessly into the workflow of Lean users. Using Lean Copilot, we build tools for suggesting proof steps (tactic suggestion), completing intermediate proof goals (proof search), and selecting relevant premises (premise selection) using LLMs. Users can use our pretrained models or bring their own ones that run either locally (with or without GPUs) or on the cloud. Experimental results demonstrate the effectiveness of our method in assisting humans and automating theorem proving process compared to existing rule-based proof automation in Lean. We open source all codes under a permissive MIT license to facilitate further research.
LeanDojo: Theorem Proving with Retrieval-Augmented Language Models
Jun 27, 2023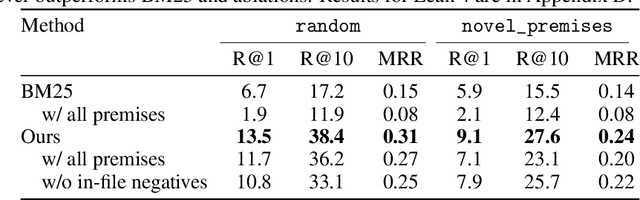
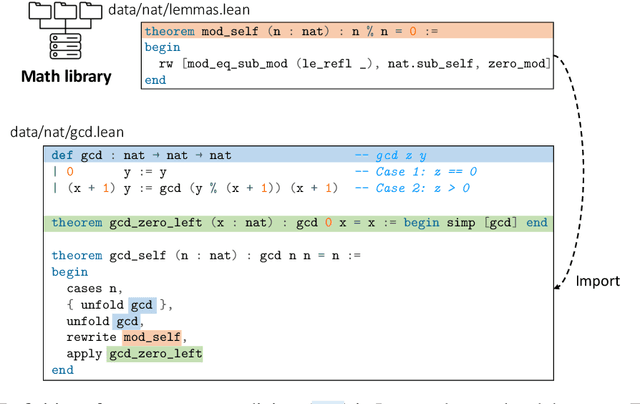

Large language models (LLMs) have shown promise in proving formal theorems using proof assistants such as Lean. However, existing methods are difficult to reproduce or build on, due to private code, data, and large compute requirements. This has created substantial barriers to research on machine learning methods for theorem proving. This paper removes these barriers by introducing LeanDojo: an open-source Lean playground consisting of toolkits, data, models, and benchmarks. LeanDojo extracts data from Lean and enables interaction with the proof environment programmatically. It contains fine-grained annotations of premises in proofs, providing valuable data for premise selection: a key bottleneck in theorem proving. Using this data, we develop ReProver (Retrieval-Augmented Prover): the first LLM-based prover that is augmented with retrieval for selecting premises from a vast math library. It is inexpensive and needs only one GPU week of training. Our retriever leverages LeanDojo's program analysis capability to identify accessible premises and hard negative examples, which makes retrieval much more effective. Furthermore, we construct a new benchmark consisting of 96,962 theorems and proofs extracted from Lean's math library. It features challenging data split requiring the prover to generalize to theorems relying on novel premises that are never used in training. We use this benchmark for training and evaluation, and experimental results demonstrate the effectiveness of ReProver over non-retrieval baselines and GPT-4. We thus provide the first set of open-source LLM-based theorem provers without any proprietary datasets and release it under a permissive MIT license to facilitate further research.
For a Higher Capacity: The Combination of FTN and NOMA Technologies in SC and MIMO Scenarios
Jul 18, 2022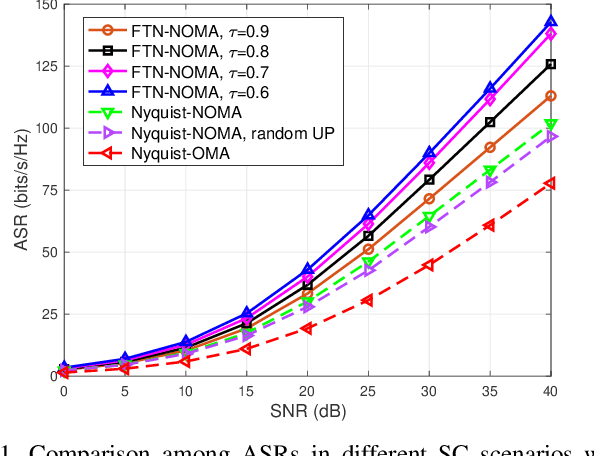
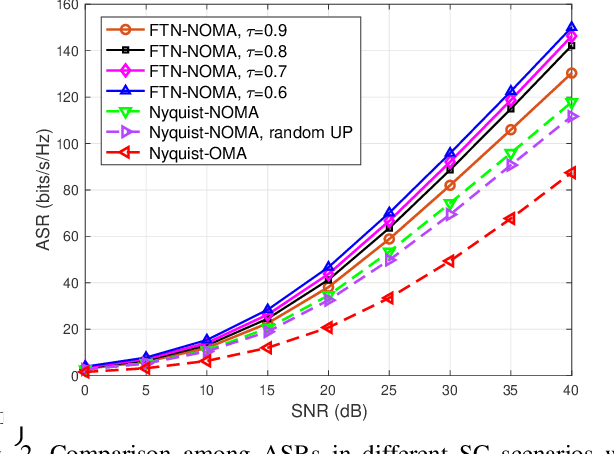
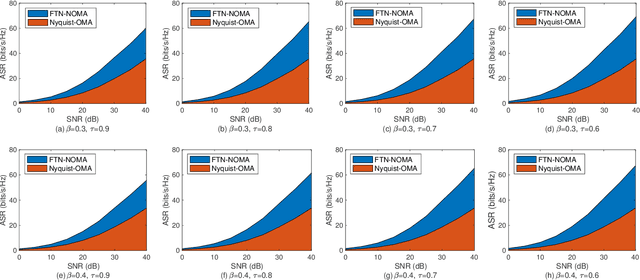
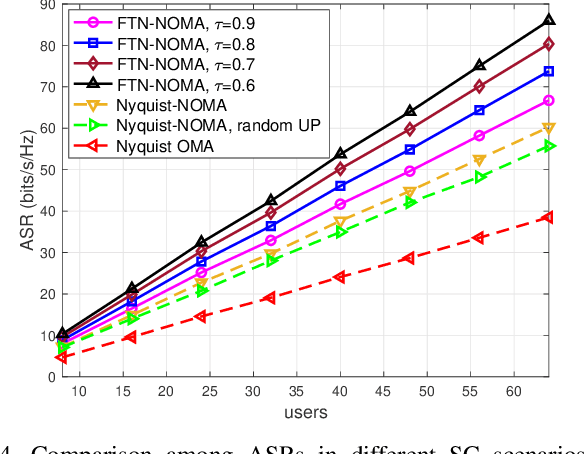
The development of the industrial Internet of Things (IoT) calls for higher spectrum efficiency (SE). Faster than Nyquist (FTN) and non-orthogonal multiple access (NOMA) are both promising paradigms to improve the SE without any extra spectrum resources required. The combination of FTN and NOMA is an interesting issue and has been focused on recently. In the NOMA technology, user pairing and power allocation are key algorithms determining system capacity. This paper first proposes a joint user pairing and power allocation algorithm for the FTN-based single-carrier (SC) NOMA system. Then, the FTN-based multiple-input-multiple-output (MIMO) NOMA is studied and a dynamic user pairing and power allocation scheme is presented. In both scenarios, the maximum available sum rate (ASR) is the target. While based on the fairness principle, the user's SE in the NOMA system is guaranteed to be no less than that in the OMA system. Simulation results show the advantage of the FTN-based NOMA with the proposed scheme in ASR and quality of service (QoS) performance. As far as we know, this paper is the first solution to the issue of user pairing and power allocation in FTN-based NOMA, which proves the great advantage of the combination of these two state-of-the-art technologies.