 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAny2Poster: Any-Source Poster Generation Across Modalities and Domains
Jun 01, 2026Visual posters are a compact medium for communicating dense information, yet progress on automatic poster generation remains difficult to measure because existing evaluations are often restricted to paper-only inputs, narrow domains, or surface-level visual similarity. We introduce Any2Poster Bench, a benchmark for any-source poster generation that evaluates systems across eight input modalities--PDFs, URLs, PPTX, DOCX, Markdown, LaTeX, notebooks, and videos--and five content domains. Any2Poster Bench pairs each source with quiz-based probes of verbatim factual retention and interpretive understanding, together with VLM-based judgments of visual quality, layout, readability, content completeness, and logical flow, enabling reproducible assessment of both information fidelity and visual communication. To instantiate and validate this benchmark, we further present Any2Poster Agent, an end-to-end reference agent that parses heterogeneous sources, organizes salient content, plans poster layouts, renders posters, and iteratively refines them using visual feedback. On Any2Poster Bench, Any2Poster Agent achieves 87.25% average accuracy across input modalities and 87.28% across content domains. On PaperQuiz-style evaluation, where prior paper-to-poster agents are directly comparable, Any2Poster Agent improves over PosterAgent-4o from 51.06-51.33% to 72.58% overall accuracy and from 116-121 to 145.16 in density-augmented score. Together, Any2Poster Bench and Any2Poster Agent provide a reusable evaluation resource and a competitive baseline for studying multimodal, domain-general poster generation.
FutureX-Pro: Extending Future Prediction to High-Value Vertical Domains
Jan 18, 2026Building upon FutureX, which established a live benchmark for general-purpose future prediction, this report introduces FutureX-Pro, including FutureX-Finance, FutureX-Retail, FutureX-PublicHealth, FutureX-NaturalDisaster, and FutureX-Search. These together form a specialized framework extending agentic future prediction to high-value vertical domains. While generalist agents demonstrate proficiency in open-domain search, their reliability in capital-intensive and safety-critical sectors remains under-explored. FutureX-Pro targets four economically and socially pivotal verticals: Finance, Retail, Public Health, and Natural Disaster. We benchmark agentic Large Language Models (LLMs) on entry-level yet foundational prediction tasks -- ranging from forecasting market indicators and supply chain demands to tracking epidemic trends and natural disasters. By adapting the contamination-free, live-evaluation pipeline of FutureX, we assess whether current State-of-the-Art (SOTA) agentic LLMs possess the domain grounding necessary for industrial deployment. Our findings reveal the performance gap between generalist reasoning and the precision required for high-value vertical applications.
Gated Attention for Large Language Models: Non-linearity, Sparsity, and Attention-Sink-Free
May 10, 2025Gating mechanisms have been widely utilized, from early models like LSTMs and Highway Networks to recent state space models, linear attention, and also softmax attention. Yet, existing literature rarely examines the specific effects of gating. In this work, we conduct comprehensive experiments to systematically investigate gating-augmented softmax attention variants. Specifically, we perform a comprehensive comparison over 30 variants of 15B Mixture-of-Experts (MoE) models and 1.7B dense models trained on a 3.5 trillion token dataset. Our central finding is that a simple modification-applying a head-specific sigmoid gate after the Scaled Dot-Product Attention (SDPA)-consistently improves performance. This modification also enhances training stability, tolerates larger learning rates, and improves scaling properties. By comparing various gating positions and computational variants, we attribute this effectiveness to two key factors: (1) introducing non-linearity upon the low-rank mapping in the softmax attention, and (2) applying query-dependent sparse gating scores to modulate the SDPA output. Notably, we find this sparse gating mechanism mitigates 'attention sink' and enhances long-context extrapolation performance, and we also release related $\href{https://github.com/qiuzh20/gated_attention}{codes}$ and $\href{https://huggingface.co/QwQZh/gated_attention}{models}$ to facilitate future research.
LeanProgress: Guiding Search for Neural Theorem Proving via Proof Progress Prediction
Feb 25, 2025Mathematical reasoning remains a significant challenge for Large Language Models (LLMs) due to hallucinations. When combined with formal proof assistants like Lean, these hallucinations can be eliminated through rigorous verification, making theorem proving reliable. However, even with formal verification, LLMs still struggle with long proofs and complex mathematical formalizations. While Lean with LLMs offers valuable assistance with retrieving lemmas, generating tactics, or even complete proofs, it lacks a crucial capability: providing a sense of proof progress. This limitation particularly impacts the overall development efficiency in large formalization projects. We introduce LeanProgress, a method that predicts the progress in the proof. Training and evaluating our models made on a large corpus of Lean proofs from Lean Workbook Plus and Mathlib4 and how many steps remain to complete it, we employ data preprocessing and balancing techniques to handle the skewed distribution of proof lengths. Our experiments show that LeanProgress achieves an overall prediction accuracy of 75.1\% in predicting the amount of progress and, hence, the remaining number of steps. When integrated into a best-first search framework using Reprover, our method shows a 3.8\% improvement on Mathlib4 compared to baseline performances of 41.2\%, particularly for longer proofs. These results demonstrate how proof progress prediction can enhance both automated and interactive theorem proving, enabling users to make more informed decisions about proof strategies.
InternLM2.5-StepProver: Advancing Automated Theorem Proving via Expert Iteration on Large-Scale LEAN Problems
Oct 21, 2024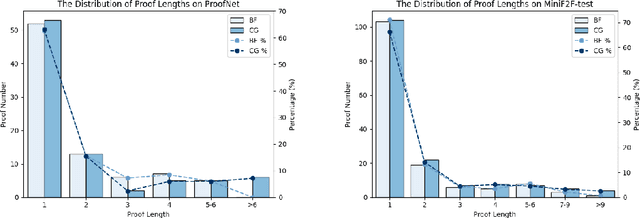

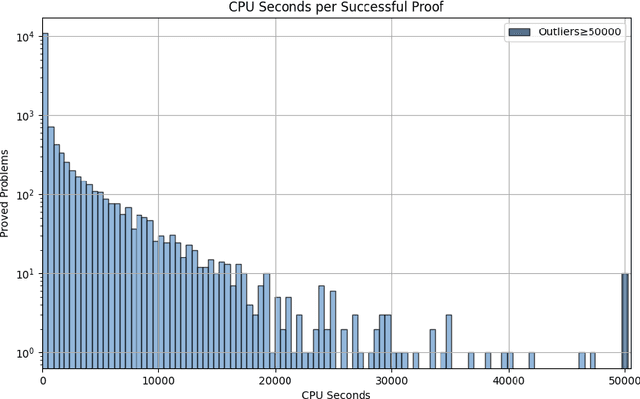

Large Language Models (LLMs) have emerged as powerful tools in mathematical theorem proving, particularly when utilizing formal languages such as LEAN. The major learning paradigm is expert iteration, which necessitates a pre-defined dataset comprising numerous mathematical problems. In this process, LLMs attempt to prove problems within the dataset and iteratively refine their capabilities through self-training on the proofs they discover. We propose to use large scale LEAN problem datasets Lean-workbook for expert iteration with more than 20,000 CPU days. During expert iteration, we found log-linear trends between solved problem amount with proof length and CPU usage. We train a critic model to select relatively easy problems for policy models to make trials and guide the model to search for deeper proofs. InternLM2.5-StepProver achieves open-source state-of-the-art on MiniF2F, Lean-Workbook-Plus, ProofNet, and Putnam benchmarks. Specifically, it achieves a pass of 65.9% on the MiniF2F-test and proves (or disproves) 17.0% of problems in Lean-Workbook-Plus which shows a significant improvement compared to only 9.5% of problems proved when Lean-Workbook-Plus was released. We open-source our models and searched proofs at https://github.com/InternLM/InternLM-Math and https://huggingface.co/datasets/internlm/Lean-Workbook.
ActFormer: Scalable Collaborative Perception via Active Queries
Mar 08, 2024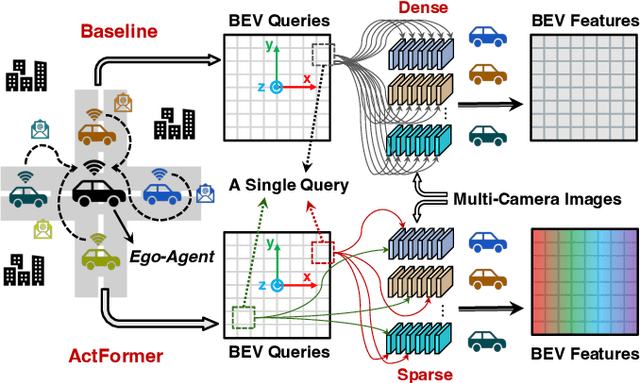
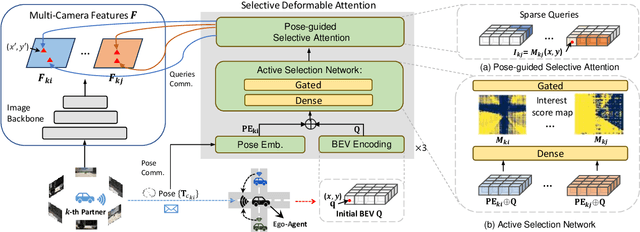
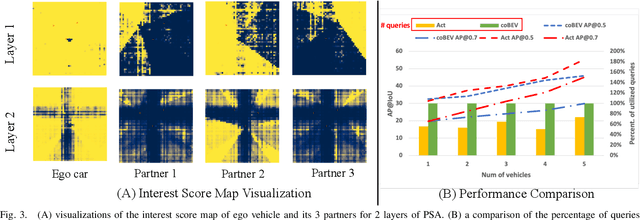
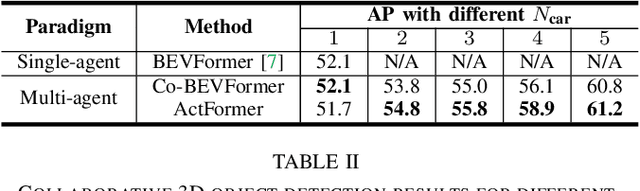
Collaborative perception leverages rich visual observations from multiple robots to extend a single robot's perception ability beyond its field of view. Many prior works receive messages broadcast from all collaborators, leading to a scalability challenge when dealing with a large number of robots and sensors. In this work, we aim to address \textit{scalable camera-based collaborative perception} with a Transformer-based architecture. Our key idea is to enable a single robot to intelligently discern the relevance of the collaborators and their associated cameras according to a learned spatial prior. This proactive understanding of the visual features' relevance does not require the transmission of the features themselves, enhancing both communication and computation efficiency. Specifically, we present ActFormer, a Transformer that learns bird's eye view (BEV) representations by using predefined BEV queries to interact with multi-robot multi-camera inputs. Each BEV query can actively select relevant cameras for information aggregation based on pose information, instead of interacting with all cameras indiscriminately. Experiments on the V2X-Sim dataset demonstrate that ActFormer improves the detection performance from 29.89% to 45.15% in terms of AP@0.7 with about 50% fewer queries, showcasing the effectiveness of ActFormer in multi-agent collaborative 3D object detection.