 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCRAG: Can 3D Generative Models Help 3D Assembly?
Feb 26, 2026Most existing 3D assembly methods treat the problem as pure pose estimation, rearranging observed parts via rigid transformations. In contrast, human assembly naturally couples structural reasoning with holistic shape inference. Inspired by this intuition, we reformulate 3D assembly as a joint problem of assembly and generation. We show that these two processes are mutually reinforcing: assembly provides part-level structural priors for generation, while generation injects holistic shape context that resolves ambiguities in assembly. Unlike prior methods that cannot synthesize missing geometry, we propose CRAG, which simultaneously generates plausible complete shapes and predicts poses for input parts. Extensive experiments demonstrate state-of-the-art performance across in-the-wild objects with diverse geometries, varying part counts, and missing pieces. Our code and models will be released.
From Intention to Execution: Probing the Generalization Boundaries of Vision-Language-Action Models
Jun 11, 2025One promise that Vision-Language-Action (VLA) models hold over traditional imitation learning for robotics is to leverage the broad generalization capabilities of large Vision-Language Models (VLMs) to produce versatile, "generalist" robot policies. However, current evaluations of VLAs remain insufficient. Traditional imitation learning benchmarks are unsuitable due to the lack of language instructions. Emerging benchmarks for VLAs that incorporate language often come with limited evaluation tasks and do not intend to investigate how much VLM pretraining truly contributes to the generalization capabilities of the downstream robotic policy. Meanwhile, much research relies on real-world robot setups designed in isolation by different institutions, which creates a barrier for reproducibility and accessibility. To address this gap, we introduce a unified probing suite of 50 simulation-based tasks across 10 subcategories spanning language instruction, vision, and objects. We systematically evaluate several state-of-the-art VLA architectures on this suite to understand their generalization capability. Our results show that while VLM backbones endow VLAs with robust perceptual understanding and high level planning, which we refer to as good intentions, this does not reliably translate into precise motor execution: when faced with out-of-distribution observations, policies often exhibit coherent intentions, but falter in action execution. Moreover, finetuning on action data can erode the original VLM's generalist reasoning abilities. We release our task suite and evaluation code to serve as a standardized benchmark for future VLAs and to drive research on closing the perception-to-action gap. More information, including the source code, can be found at https://ai4ce.github.io/INT-ACT/
When language and vision meet road safety: leveraging multimodal large language models for video-based traffic accident analysis
Jan 17, 2025



The increasing availability of traffic videos functioning on a 24/7/365 time scale has the great potential of increasing the spatio-temporal coverage of traffic accidents, which will help improve traffic safety. However, analyzing footage from hundreds, if not thousands, of traffic cameras in a 24/7/365 working protocol remains an extremely challenging task, as current vision-based approaches primarily focus on extracting raw information, such as vehicle trajectories or individual object detection, but require laborious post-processing to derive actionable insights. We propose SeeUnsafe, a new framework that integrates Multimodal Large Language Model (MLLM) agents to transform video-based traffic accident analysis from a traditional extraction-then-explanation workflow to a more interactive, conversational approach. This shift significantly enhances processing throughput by automating complex tasks like video classification and visual grounding, while improving adaptability by enabling seamless adjustments to diverse traffic scenarios and user-defined queries. Our framework employs a severity-based aggregation strategy to handle videos of various lengths and a novel multimodal prompt to generate structured responses for review and evaluation and enable fine-grained visual grounding. We introduce IMS (Information Matching Score), a new MLLM-based metric for aligning structured responses with ground truth. We conduct extensive experiments on the Toyota Woven Traffic Safety dataset, demonstrating that SeeUnsafe effectively performs accident-aware video classification and visual grounding by leveraging off-the-shelf MLLMs. Source code will be available at \url{https://github.com/ai4ce/SeeUnsafe}.
CityWalker: Learning Embodied Urban Navigation from Web-Scale Videos
Nov 26, 2024



Navigating dynamic urban environments presents significant challenges for embodied agents, requiring advanced spatial reasoning and adherence to common-sense norms. Despite progress, existing visual navigation methods struggle in map-free or off-street settings, limiting the deployment of autonomous agents like last-mile delivery robots. To overcome these obstacles, we propose a scalable, data-driven approach for human-like urban navigation by training agents on thousands of hours of in-the-wild city walking and driving videos sourced from the web. We introduce a simple and scalable data processing pipeline that extracts action supervision from these videos, enabling large-scale imitation learning without costly annotations. Our model learns sophisticated navigation policies to handle diverse challenges and critical scenarios. Experimental results show that training on large-scale, diverse datasets significantly enhances navigation performance, surpassing current methods. This work shows the potential of using abundant online video data to develop robust navigation policies for embodied agents in dynamic urban settings. https://ai4ce.github.io/CityWalker/
Multiview Scene Graph
Oct 15, 2024



A proper scene representation is central to the pursuit of spatial intelligence where agents can robustly reconstruct and efficiently understand 3D scenes. A scene representation is either metric, such as landmark maps in 3D reconstruction, 3D bounding boxes in object detection, or voxel grids in occupancy prediction, or topological, such as pose graphs with loop closures in SLAM or visibility graphs in SfM. In this work, we propose to build Multiview Scene Graphs (MSG) from unposed images, representing a scene topologically with interconnected place and object nodes. The task of building MSG is challenging for existing representation learning methods since it needs to jointly address both visual place recognition, object detection, and object association from images with limited fields of view and potentially large viewpoint changes. To evaluate any method tackling this task, we developed an MSG dataset and annotation based on a public 3D dataset. We also propose an evaluation metric based on the intersection-over-union score of MSG edges. Moreover, we develop a novel baseline method built on mainstream pretrained vision models, combining visual place recognition and object association into one Transformer decoder architecture. Experiments demonstrate our method has superior performance compared to existing relevant baselines.
VLM See, Robot Do: Human Demo Video to Robot Action Plan via Vision Language Model
Oct 11, 2024Vision Language Models (VLMs) have recently been adopted in robotics for their capability in common sense reasoning and generalizability. Existing work has applied VLMs to generate task and motion planning from natural language instructions and simulate training data for robot learning. In this work, we explore using VLM to interpret human demonstration videos and generate robot task planning. Our method integrates keyframe selection, visual perception, and VLM reasoning into a pipeline. We named it SeeDo because it enables the VLM to ''see'' human demonstrations and explain the corresponding plans to the robot for it to ''do''. To validate our approach, we collected a set of long-horizon human videos demonstrating pick-and-place tasks in three diverse categories and designed a set of metrics to comprehensively benchmark SeeDo against several baselines, including state-of-the-art video-input VLMs. The experiments demonstrate SeeDo's superior performance. We further deployed the generated task plans in both a simulation environment and on a real robot arm.
Tell Me Where You Are: Multimodal LLMs Meet Place Recognition
Jun 25, 2024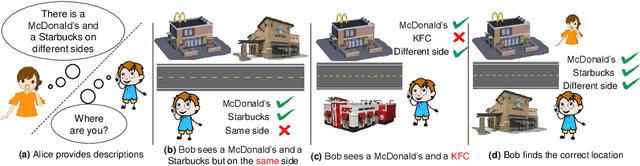
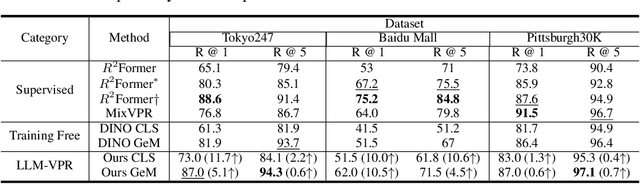
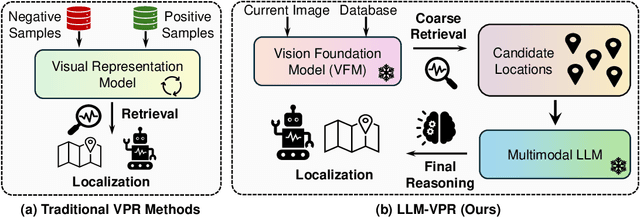
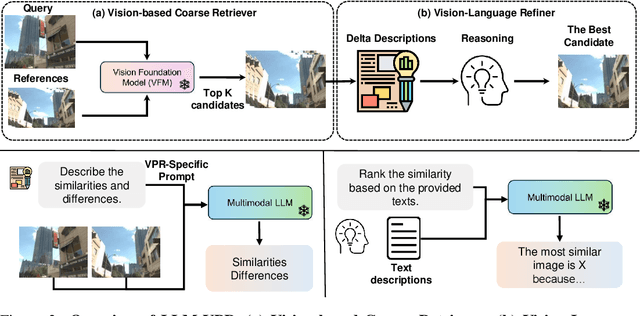
Large language models (LLMs) exhibit a variety of promising capabilities in robotics, including long-horizon planning and commonsense reasoning. However, their performance in place recognition is still underexplored. In this work, we introduce multimodal LLMs (MLLMs) to visual place recognition (VPR), where a robot must localize itself using visual observations. Our key design is to use vision-based retrieval to propose several candidates and then leverage language-based reasoning to carefully inspect each candidate for a final decision. Specifically, we leverage the robust visual features produced by off-the-shelf vision foundation models (VFMs) to obtain several candidate locations. We then prompt an MLLM to describe the differences between the current observation and each candidate in a pairwise manner, and reason about the best candidate based on these descriptions. Our results on three datasets demonstrate that integrating the general-purpose visual features from VFMs with the reasoning capabilities of MLLMs already provides an effective place recognition solution, without any VPR-specific supervised training. We believe our work can inspire new possibilities for applying and designing foundation models, i.e., VFMs, LLMs, and MLLMs, to enhance the localization and navigation of mobile robots.
LUWA Dataset: Learning Lithic Use-Wear Analysis on Microscopic Images
Mar 27, 2024



Lithic Use-Wear Analysis (LUWA) using microscopic images is an underexplored vision-for-science research area. It seeks to distinguish the worked material, which is critical for understanding archaeological artifacts, material interactions, tool functionalities, and dental records. However, this challenging task goes beyond the well-studied image classification problem for common objects. It is affected by many confounders owing to the complex wear mechanism and microscopic imaging, which makes it difficult even for human experts to identify the worked material successfully. In this paper, we investigate the following three questions on this unique vision task for the first time:(i) How well can state-of-the-art pre-trained models (like DINOv2) generalize to the rarely seen domain? (ii) How can few-shot learning be exploited for scarce microscopic images? (iii) How do the ambiguous magnification and sensing modality influence the classification accuracy? To study these, we collaborated with archaeologists and built the first open-source and the largest LUWA dataset containing 23,130 microscopic images with different magnifications and sensing modalities. Extensive experiments show that existing pre-trained models notably outperform human experts but still leave a large gap for improvements. Most importantly, the LUWA dataset provides an underexplored opportunity for vision and learning communities and complements existing image classification problems on common objects.
ActFormer: Scalable Collaborative Perception via Active Queries
Mar 08, 2024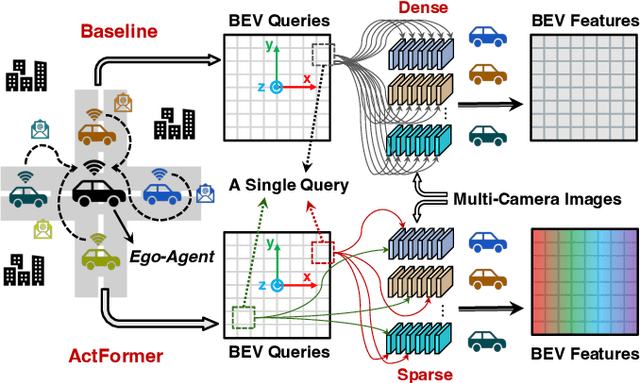
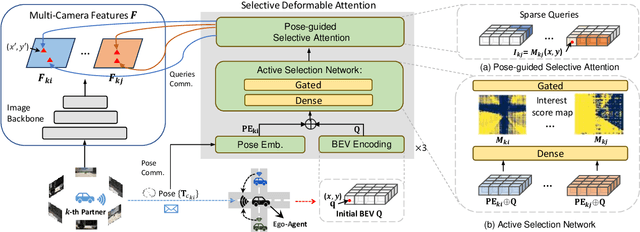
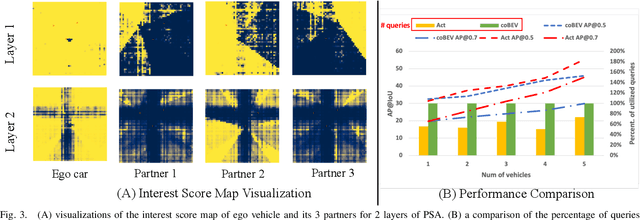
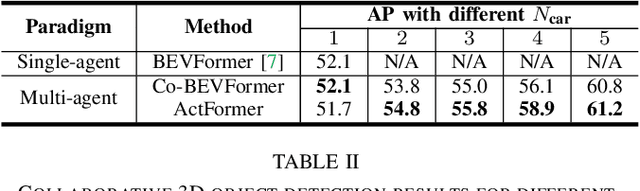
Collaborative perception leverages rich visual observations from multiple robots to extend a single robot's perception ability beyond its field of view. Many prior works receive messages broadcast from all collaborators, leading to a scalability challenge when dealing with a large number of robots and sensors. In this work, we aim to address \textit{scalable camera-based collaborative perception} with a Transformer-based architecture. Our key idea is to enable a single robot to intelligently discern the relevance of the collaborators and their associated cameras according to a learned spatial prior. This proactive understanding of the visual features' relevance does not require the transmission of the features themselves, enhancing both communication and computation efficiency. Specifically, we present ActFormer, a Transformer that learns bird's eye view (BEV) representations by using predefined BEV queries to interact with multi-robot multi-camera inputs. Each BEV query can actively select relevant cameras for information aggregation based on pose information, instead of interacting with all cameras indiscriminately. Experiments on the V2X-Sim dataset demonstrate that ActFormer improves the detection performance from 29.89% to 45.15% in terms of AP@0.7 with about 50% fewer queries, showcasing the effectiveness of ActFormer in multi-agent collaborative 3D object detection.
URLOST: Unsupervised Representation Learning without Stationarity or Topology
Oct 06, 2023Unsupervised representation learning has seen tremendous progress but is constrained by its reliance on data modality-specific stationarity and topology, a limitation not found in biological intelligence systems. For instance, human vision processes visual signals derived from irregular and non-stationary sampling lattices yet accurately perceives the geometry of the world. We introduce a novel framework that learns from high-dimensional data lacking stationarity and topology. Our model combines a learnable self-organizing layer, density adjusted spectral clustering, and masked autoencoders. We evaluate its effectiveness on simulated biological vision data, neural recordings from the primary visual cortex, and gene expression datasets. Compared to state-of-the-art unsupervised learning methods like SimCLR and MAE, our model excels at learning meaningful representations across diverse modalities without depending on stationarity or topology. It also outperforms other methods not dependent on these factors, setting a new benchmark in the field. This work represents a step toward unsupervised learning methods that can generalize across diverse high-dimensional data modalities.