 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParkingTwin: Training-Free Streaming 3D Reconstruction for Parking-Lot Digital Twins
Jan 20, 2026High-fidelity parking-lot digital twins provide essential priors for path planning, collision checking, and perception validation in Automated Valet Parking (AVP). Yet robot-oriented reconstruction faces a trilemma: sparse forward-facing views cause weak parallax and ill-posed geometry; dynamic occlusions and extreme lighting hinder stable texture fusion; and neural rendering typically needs expensive offline optimization, violating edge-side streaming constraints. We propose ParkingTwin, a training-free, lightweight system for online streaming 3D reconstruction. First, OSM-prior-driven geometric construction uses OpenStreetMap semantic topology to directly generate a metric-consistent TSDF, replacing blind geometric search with deterministic mapping and avoiding costly optimization. Second, geometry-aware dynamic filtering employs a quad-modal constraint field (normal/height/depth consistency) to reject moving vehicles and transient occlusions in real time. Third, illumination-robust fusion in CIELAB decouples luminance and chromaticity via adaptive L-channel weighting and depth-gradient suppression, reducing seams under abrupt lighting changes. ParkingTwin runs at 30+ FPS on an entry-level GTX 1660. On a 68,000 m^2 real-world dataset, it achieves SSIM 0.87 (+16.0%), delivers about 15x end-to-end speedup, and reduces GPU memory by 83.3% compared with state-of-the-art 3D Gaussian Splatting (3DGS) that typically requires high-end GPUs (RTX 4090D). The system outputs explicit triangle meshes compatible with Unity/Unreal digital-twin pipelines. Project page: https://mihoutao-liu.github.io/ParkingTwin/
Hierarchical Refinement: Optimal Transport to Infinity and Beyond
Mar 04, 2025Optimal transport (OT) has enjoyed great success in machine-learning as a principled way to align datasets via a least-cost correspondence. This success was driven in large part by the runtime efficiency of the Sinkhorn algorithm [Cuturi 2013], which computes a coupling between points from two datasets. However, Sinkhorn has quadratic space complexity in the number of points, limiting the scalability to larger datasets. Low-rank OT achieves linear-space complexity, but by definition, cannot compute a one-to-one correspondence between points. When the optimal transport problem is an assignment problem between datasets then the optimal mapping, known as the Monge map, is guaranteed to be a bijection. In this setting, we show that the factors of an optimal low-rank coupling co-cluster each point with its image under the Monge map. We leverage this invariant to derive an algorithm, Hierarchical Refinement (HiRef), that dynamically constructs a multiscale partition of a dataset using low-rank OT subproblems, culminating in a bijective coupling. Hierarchical Refinement uses linear space and has log-linear runtime, retaining the space advantage of low-rank OT while overcoming its limited resolution. We demonstrate the advantages of Hierarchical Refinement on several datasets, including ones containing over a million points, scaling full-rank OT to problems previously beyond Sinkhorn's reach.
CityWalker: Learning Embodied Urban Navigation from Web-Scale Videos
Nov 26, 2024Navigating dynamic urban environments presents significant challenges for embodied agents, requiring advanced spatial reasoning and adherence to common-sense norms. Despite progress, existing visual navigation methods struggle in map-free or off-street settings, limiting the deployment of autonomous agents like last-mile delivery robots. To overcome these obstacles, we propose a scalable, data-driven approach for human-like urban navigation by training agents on thousands of hours of in-the-wild city walking and driving videos sourced from the web. We introduce a simple and scalable data processing pipeline that extracts action supervision from these videos, enabling large-scale imitation learning without costly annotations. Our model learns sophisticated navigation policies to handle diverse challenges and critical scenarios. Experimental results show that training on large-scale, diverse datasets significantly enhances navigation performance, surpassing current methods. This work shows the potential of using abundant online video data to develop robust navigation policies for embodied agents in dynamic urban settings. https://ai4ce.github.io/CityWalker/
Low-Rank Optimal Transport through Factor Relaxation with Latent Coupling
Nov 15, 2024



Optimal transport (OT) is a general framework for finding a minimum-cost transport plan, or coupling, between probability distributions, and has many applications in machine learning. A key challenge in applying OT to massive datasets is the quadratic scaling of the coupling matrix with the size of the dataset. [Forrow et al. 2019] introduced a factored coupling for the k-Wasserstein barycenter problem, which [Scetbon et al. 2021] adapted to solve the primal low-rank OT problem. We derive an alternative parameterization of the low-rank problem based on the $\textit{latent coupling}$ (LC) factorization previously introduced by [Lin et al. 2021] generalizing [Forrow et al. 2019]. The LC factorization has multiple advantages for low-rank OT including decoupling the problem into three OT problems and greater flexibility and interpretability. We leverage these advantages to derive a new algorithm $\textit{Factor Relaxation with Latent Coupling}$ (FRLC), which uses $\textit{coordinate}$ mirror descent to compute the LC factorization. FRLC handles multiple OT objectives (Wasserstein, Gromov-Wasserstein, Fused Gromov-Wasserstein), and marginal constraints (balanced, unbalanced, and semi-relaxed) with linear space complexity. We provide theoretical results on FRLC, and demonstrate superior performance on diverse applications -- including graph clustering and spatial transcriptomics -- while demonstrating its interpretability.
Multiview Scene Graph
Oct 15, 2024



A proper scene representation is central to the pursuit of spatial intelligence where agents can robustly reconstruct and efficiently understand 3D scenes. A scene representation is either metric, such as landmark maps in 3D reconstruction, 3D bounding boxes in object detection, or voxel grids in occupancy prediction, or topological, such as pose graphs with loop closures in SLAM or visibility graphs in SfM. In this work, we propose to build Multiview Scene Graphs (MSG) from unposed images, representing a scene topologically with interconnected place and object nodes. The task of building MSG is challenging for existing representation learning methods since it needs to jointly address both visual place recognition, object detection, and object association from images with limited fields of view and potentially large viewpoint changes. To evaluate any method tackling this task, we developed an MSG dataset and annotation based on a public 3D dataset. We also propose an evaluation metric based on the intersection-over-union score of MSG edges. Moreover, we develop a novel baseline method built on mainstream pretrained vision models, combining visual place recognition and object association into one Transformer decoder architecture. Experiments demonstrate our method has superior performance compared to existing relevant baselines.
Breaking the Black-Box: Confidence-Guided Model Inversion Attack for Distribution Shift
Feb 28, 2024



Model inversion attacks (MIAs) seek to infer the private training data of a target classifier by generating synthetic images that reflect the characteristics of the target class through querying the model. However, prior studies have relied on full access to the target model, which is not practical in real-world scenarios. Additionally, existing black-box MIAs assume that the image prior and target model follow the same distribution. However, when confronted with diverse data distribution settings, these methods may result in suboptimal performance in conducting attacks. To address these limitations, this paper proposes a \textbf{C}onfidence-\textbf{G}uided \textbf{M}odel \textbf{I}nversion attack method called CG-MI, which utilizes the latent space of a pre-trained publicly available generative adversarial network (GAN) as prior information and gradient-free optimizer, enabling high-resolution MIAs across different data distributions in a black-box setting. Our experiments demonstrate that our method significantly \textbf{outperforms the SOTA black-box MIA by more than 49\% for Celeba and 58\% for Facescrub in different distribution settings}. Furthermore, our method exhibits the ability to generate high-quality images \textbf{comparable to those produced by white-box attacks}. Our method provides a practical and effective solution for black-box model inversion attacks.
LiDAR-based 4D Occupancy Completion and Forecasting
Oct 17, 2023
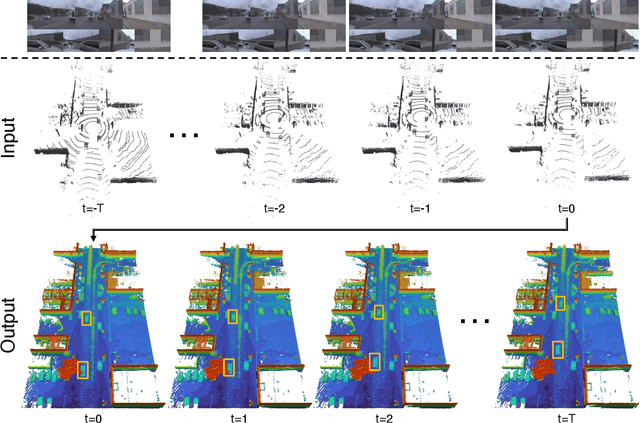
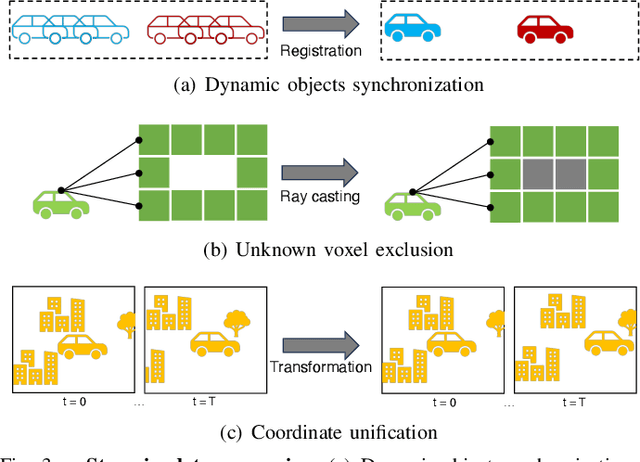
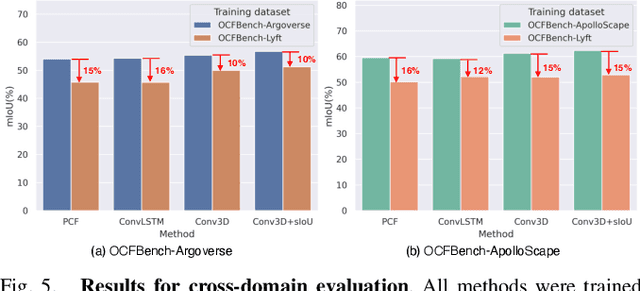
Scene completion and forecasting are two popular perception problems in research for mobile agents like autonomous vehicles. Existing approaches treat the two problems in isolation, resulting in a separate perception of the two aspects. In this paper, we introduce a novel LiDAR perception task of Occupancy Completion and Forecasting (OCF) in the context of autonomous driving to unify these aspects into a cohesive framework. This task requires new algorithms to address three challenges altogether: (1) sparse-to-dense reconstruction, (2) partial-to-complete hallucination, and (3) 3D-to-4D prediction. To enable supervision and evaluation, we curate a large-scale dataset termed OCFBench from public autonomous driving datasets. We analyze the performance of closely related existing baseline models and our own ones on our dataset. We envision that this research will inspire and call for further investigation in this evolving and crucial area of 4D perception. Our code for data curation and baseline implementation is available at https://github.com/ai4ce/Occ4cast.
SSCBench: A Large-Scale 3D Semantic Scene Completion Benchmark for Autonomous Driving
Jun 15, 2023Semantic scene completion (SSC) is crucial for holistic 3D scene understanding by jointly estimating semantics and geometry from sparse observations. However, progress in SSC, particularly in autonomous driving scenarios, is hindered by the scarcity of high-quality datasets. To overcome this challenge, we introduce SSCBench, a comprehensive benchmark that integrates scenes from widely-used automotive datasets (e.g., KITTI-360, nuScenes, and Waymo). SSCBench follows an established setup and format in the community, facilitating the easy exploration of the camera- and LiDAR-based SSC across various real-world scenarios. We present quantitative and qualitative evaluations of state-of-the-art algorithms on SSCBench and commit to continuously incorporating novel automotive datasets and SSC algorithms to drive further advancements in this field. Our resources are released on https://github.com/ai4ce/SSCBench.
DeepMapping2: Self-Supervised Large-Scale LiDAR Map Optimization
Dec 13, 2022LiDAR mapping is important yet challenging in self-driving and mobile robotics. To tackle such a global point cloud registration problem, DeepMapping converts the complex map estimation into a self-supervised training of simple deep networks. Despite its broad convergence range on small datasets, DeepMapping still cannot produce satisfactory results on large-scale datasets with thousands of frames. This is due to the lack of loop closures and exact cross-frame point correspondences, and the slow convergence of its global localization network. We propose DeepMapping2 by adding two novel techniques to address these issues: (1) organization of training batch based on map topology from loop closing, and (2) self-supervised local-to-global point consistency loss leveraging pairwise registration. Our experiments and ablation studies on public datasets (KITTI, NCLT, and Nebula) demonstrate the effectiveness of our method. Our code will be released.
Self-Supervised Visual Place Recognition by Mining Temporal and Feature Neighborhoods
Aug 19, 2022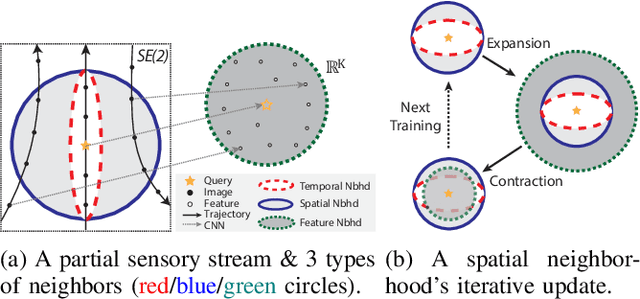

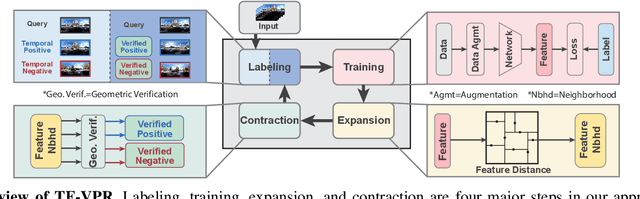
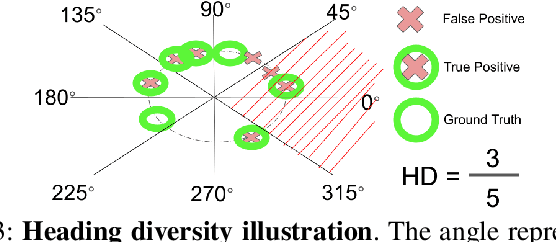
Visual place recognition (VPR) using deep networks has achieved state-of-the-art performance. However, most of them require a training set with ground truth sensor poses to obtain positive and negative samples of each observation's spatial neighborhood for supervised learning. When such information is unavailable, temporal neighborhoods from a sequentially collected data stream could be exploited for self-supervised training, although we find its performance suboptimal. Inspired by noisy label learning, we propose a novel self-supervised framework named \textit{TF-VPR} that uses temporal neighborhoods and learnable feature neighborhoods to discover unknown spatial neighborhoods. Our method follows an iterative training paradigm which alternates between: (1) representation learning with data augmentation, (2) positive set expansion to include the current feature space neighbors, and (3) positive set contraction via geometric verification. We conduct comprehensive experiments on both simulated and real datasets, with either RGB images or point clouds as inputs. The results show that our method outperforms our baselines in recall rate, robustness, and heading diversity, a novel metric we propose for VPR. Our code and datasets can be found at https://ai4ce.github.io/TF-VPR/.