 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Refinement: Optimal Transport to Infinity and Beyond
Mar 04, 2025Optimal transport (OT) has enjoyed great success in machine-learning as a principled way to align datasets via a least-cost correspondence. This success was driven in large part by the runtime efficiency of the Sinkhorn algorithm [Cuturi 2013], which computes a coupling between points from two datasets. However, Sinkhorn has quadratic space complexity in the number of points, limiting the scalability to larger datasets. Low-rank OT achieves linear-space complexity, but by definition, cannot compute a one-to-one correspondence between points. When the optimal transport problem is an assignment problem between datasets then the optimal mapping, known as the Monge map, is guaranteed to be a bijection. In this setting, we show that the factors of an optimal low-rank coupling co-cluster each point with its image under the Monge map. We leverage this invariant to derive an algorithm, Hierarchical Refinement (HiRef), that dynamically constructs a multiscale partition of a dataset using low-rank OT subproblems, culminating in a bijective coupling. Hierarchical Refinement uses linear space and has log-linear runtime, retaining the space advantage of low-rank OT while overcoming its limited resolution. We demonstrate the advantages of Hierarchical Refinement on several datasets, including ones containing over a million points, scaling full-rank OT to problems previously beyond Sinkhorn's reach.
Quantifying and Reducing Bias in Maximum Likelihood Estimation of Structured Anomalies
Jul 15, 2020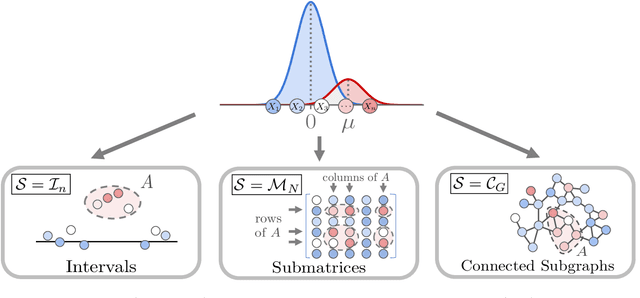

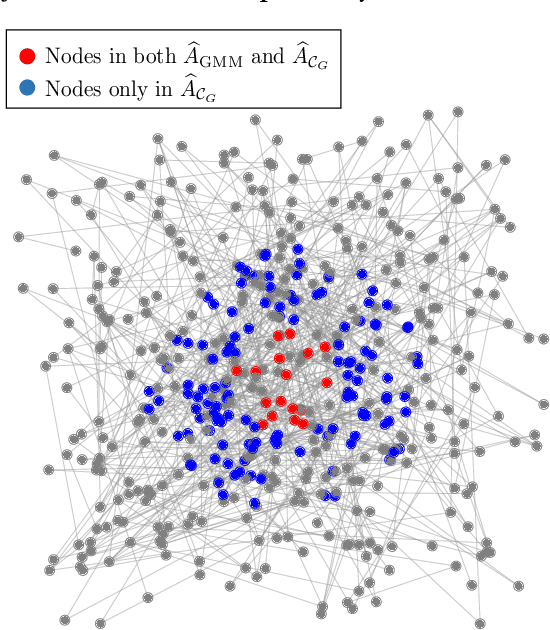
Anomaly estimation, or the problem of finding a subset of a dataset that differs from the rest of the dataset, is a classic problem in machine learning and data mining. In both theoretical work and in applications, the anomaly is assumed to have a specific structure defined by membership in an $\textit{anomaly family}$. For example, in temporal data the anomaly family may be time intervals, while in network data the anomaly family may be connected subgraphs. The most prominent approach for anomaly estimation is to compute the Maximum Likelihood Estimator (MLE) of the anomaly. However, it was recently observed that for some anomaly families, the MLE is an asymptotically $\textit{biased}$ estimator of the anomaly. Here, we demonstrate that the bias of the MLE depends on the size of the anomaly family. We prove that if the number of sets in the anomaly family that contain the anomaly is sub-exponential, then the MLE is asymptotically unbiased. At the same time, we provide empirical evidence that the converse is also true: if the number of such sets is exponential, then the MLE is asymptotically biased. Our analysis unifies a number of earlier results on the bias of the MLE for specific anomaly families, including intervals, submatrices, and connected subgraphs. Next, we derive a new anomaly estimator using a mixture model, and we empirically demonstrate that our estimator is asymptotically unbiased regardless of the size of the anomaly family. We illustrate the benefits of our estimator on both simulated disease outbreak data and a real-world highway traffic dataset.