 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying and Reducing Bias in Maximum Likelihood Estimation of Structured Anomalies
Jul 15, 2020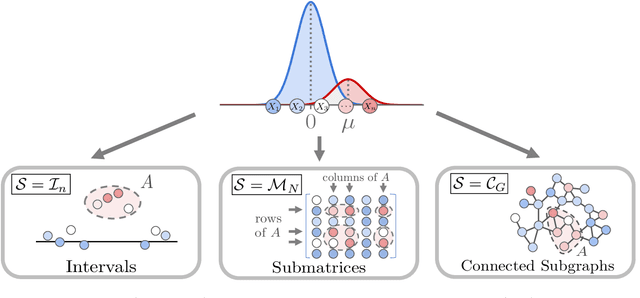

Anomaly estimation, or the problem of finding a subset of a dataset that differs from the rest of the dataset, is a classic problem in machine learning and data mining. In both theoretical work and in applications, the anomaly is assumed to have a specific structure defined by membership in an $\textit{anomaly family}$. For example, in temporal data the anomaly family may be time intervals, while in network data the anomaly family may be connected subgraphs. The most prominent approach for anomaly estimation is to compute the Maximum Likelihood Estimator (MLE) of the anomaly. However, it was recently observed that for some anomaly families, the MLE is an asymptotically $\textit{biased}$ estimator of the anomaly. Here, we demonstrate that the bias of the MLE depends on the size of the anomaly family. We prove that if the number of sets in the anomaly family that contain the anomaly is sub-exponential, then the MLE is asymptotically unbiased. At the same time, we provide empirical evidence that the converse is also true: if the number of such sets is exponential, then the MLE is asymptotically biased. Our analysis unifies a number of earlier results on the bias of the MLE for specific anomaly families, including intervals, submatrices, and connected subgraphs. Next, we derive a new anomaly estimator using a mixture model, and we empirically demonstrate that our estimator is asymptotically unbiased regardless of the size of the anomaly family. We illustrate the benefits of our estimator on both simulated disease outbreak data and a real-world highway traffic dataset.
Random Walks on Hypergraphs with Edge-Dependent Vertex Weights
May 20, 2019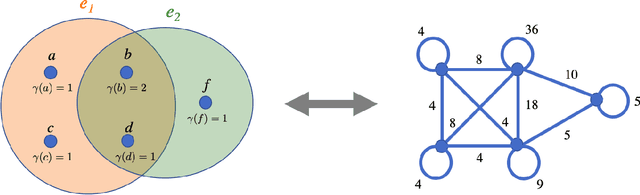
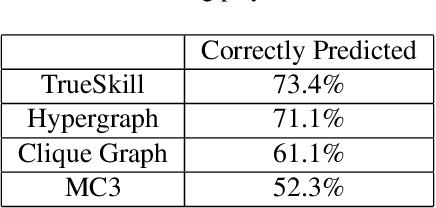
Hypergraphs are used in machine learning to model higher-order relationships in data. While spectral methods for graphs are well-established, spectral theory for hypergraphs remains an active area of research. In this paper, we use random walks to develop a spectral theory for hypergraphs with edge-dependent vertex weights: hypergraphs where every vertex $v$ has a weight $\gamma_e(v)$ for each incident hyperedge $e$ that describes the contribution of $v$ to the hyperedge $e$. We derive a random walk-based hypergraph Laplacian, and bound the mixing time of random walks on such hypergraphs. Moreover, we give conditions under which random walks on such hypergraphs are equivalent to random walks on graphs. As a corollary, we show that current machine learning methods that rely on Laplacians derived from random walks on hypergraphs with edge-independent vertex weights do not utilize higher-order relationships in the data. Finally, we demonstrate the advantages of hypergraphs with edge-dependent vertex weights on ranking applications using real-world datasets.