 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransport Clustering: Solving Low-Rank Optimal Transport via Clustering
Mar 03, 2026Optimal transport (OT) finds a least cost transport plan between two probability distributions using a cost matrix defined on pairs of points. Unlike standard OT, which infers unstructured pointwise mappings, low-rank optimal transport explicitly constrains the rank of the transport plan to infer latent structure. This improves statistical stability and robustness, yields sharper parametric rates for estimating Wasserstein distances adaptive to the intrinsic rank, and generalizes $K$-means to co-clustering. These advantages, however, come at the cost of a non-convex and NP-hard optimization problem. We introduce transport clustering, an algorithm to compute a low-rank OT plan that reduces low-rank OT to a clustering problem on correspondences obtained from a full-rank $\textit{transport registration}$ step. We prove that this reduction yields polynomial-time, constant-factor approximation algorithms for low-rank OT: specifically, a $(1+γ)$ approximation for negative-type metrics and a $(1+γ+\sqrt{2γ}\,)$ approximation for kernel costs, where $γ\in [0,1]$ denotes the approximation ratio of the optimal full-rank solution relative to the low-rank optimal. Empirically, transport clustering outperforms existing low-rank OT solvers on synthetic benchmarks and large-scale, high-dimensional datasets.
Implicit Bias of the JKO Scheme
Nov 18, 2025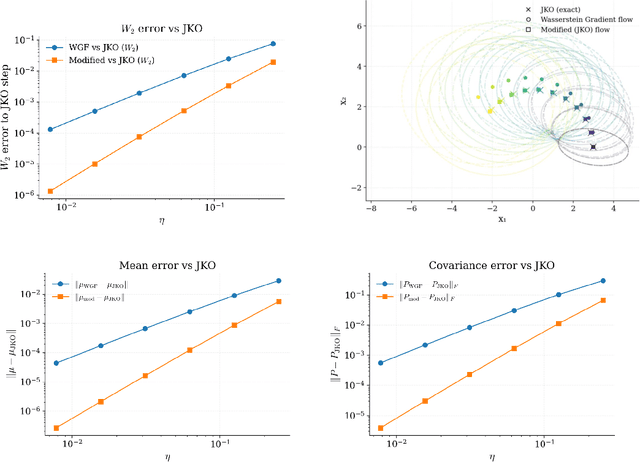

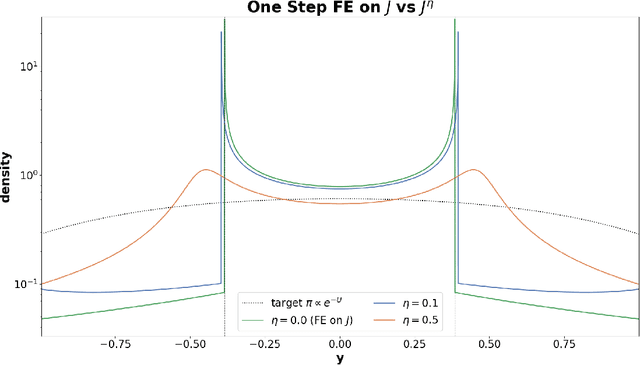
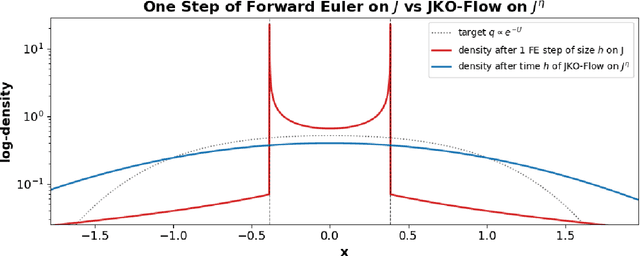
Wasserstein gradient flow provides a general framework for minimizing an energy functional $J$ over the space of probability measures on a Riemannian manifold $(M,g)$. Its canonical time-discretization, the Jordan-Kinderlehrer-Otto (JKO) scheme, produces for any step size $η>0$ a sequence of probability distributions $ρ_k^η$ that approximate to first order in $η$ Wasserstein gradient flow on $J$. But the JKO scheme also has many other remarkable properties not shared by other first order integrators, e.g. it preserves energy dissipation and exhibits unconditional stability for $λ$-geodesically convex functionals $J$. To better understand the JKO scheme we characterize its implicit bias at second order in $η$. We show that $ρ_k^η$ are approximated to order $η^2$ by Wasserstein gradient flow on a \emph{modified} energy \[ J^η(ρ) = J(ρ) - \fracη{4}\int_M \Big\lVert \nabla_g \frac{δJ}{δρ} (ρ) \Big\rVert_{2}^{2} \,ρ(dx), \] obtained by subtracting from $J$ the squared metric curvature of $J$ times $η/4$. The JKO scheme therefore adds at second order in $η$ a \textit{deceleration} in directions where the metric curvature of $J$ is rapidly changing. This corresponds to canonical implicit biases for common functionals: for entropy the implicit bias is the Fisher information, for KL-divergence it is the Fisher-Hyv{ä}rinen divergence, and for Riemannian gradient descent it is the kinetic energy in the metric $g$. To understand the differences between minimizing $J$ and $J^η$ we study \emph{JKO-Flow}, Wasserstein gradient flow on $J^η$, in several simple numerical examples. These include exactly solvable Langevin dynamics on the Bures-Wasserstein space and Langevin sampling from a quartic potential in 1D.
Hierarchical Refinement: Optimal Transport to Infinity and Beyond
Mar 04, 2025



Optimal transport (OT) has enjoyed great success in machine-learning as a principled way to align datasets via a least-cost correspondence. This success was driven in large part by the runtime efficiency of the Sinkhorn algorithm [Cuturi 2013], which computes a coupling between points from two datasets. However, Sinkhorn has quadratic space complexity in the number of points, limiting the scalability to larger datasets. Low-rank OT achieves linear-space complexity, but by definition, cannot compute a one-to-one correspondence between points. When the optimal transport problem is an assignment problem between datasets then the optimal mapping, known as the Monge map, is guaranteed to be a bijection. In this setting, we show that the factors of an optimal low-rank coupling co-cluster each point with its image under the Monge map. We leverage this invariant to derive an algorithm, Hierarchical Refinement (HiRef), that dynamically constructs a multiscale partition of a dataset using low-rank OT subproblems, culminating in a bijective coupling. Hierarchical Refinement uses linear space and has log-linear runtime, retaining the space advantage of low-rank OT while overcoming its limited resolution. We demonstrate the advantages of Hierarchical Refinement on several datasets, including ones containing over a million points, scaling full-rank OT to problems previously beyond Sinkhorn's reach.
Low-Rank Optimal Transport through Factor Relaxation with Latent Coupling
Nov 15, 2024



Optimal transport (OT) is a general framework for finding a minimum-cost transport plan, or coupling, between probability distributions, and has many applications in machine learning. A key challenge in applying OT to massive datasets is the quadratic scaling of the coupling matrix with the size of the dataset. [Forrow et al. 2019] introduced a factored coupling for the k-Wasserstein barycenter problem, which [Scetbon et al. 2021] adapted to solve the primal low-rank OT problem. We derive an alternative parameterization of the low-rank problem based on the $\textit{latent coupling}$ (LC) factorization previously introduced by [Lin et al. 2021] generalizing [Forrow et al. 2019]. The LC factorization has multiple advantages for low-rank OT including decoupling the problem into three OT problems and greater flexibility and interpretability. We leverage these advantages to derive a new algorithm $\textit{Factor Relaxation with Latent Coupling}$ (FRLC), which uses $\textit{coordinate}$ mirror descent to compute the LC factorization. FRLC handles multiple OT objectives (Wasserstein, Gromov-Wasserstein, Fused Gromov-Wasserstein), and marginal constraints (balanced, unbalanced, and semi-relaxed) with linear space complexity. We provide theoretical results on FRLC, and demonstrate superior performance on diverse applications -- including graph clustering and spatial transcriptomics -- while demonstrating its interpretability.
System Identification for Continuous-time Linear Dynamical Systems
Aug 23, 2023The problem of system identification for the Kalman filter, relying on the expectation-maximization (EM) procedure to learn the underlying parameters of a dynamical system, has largely been studied assuming that observations are sampled at equally-spaced time points. However, in many applications this is a restrictive and unrealistic assumption. This paper addresses system identification for the continuous-discrete filter, with the aim of generalizing learning for the Kalman filter by relying on a solution to a continuous-time It\^o stochastic differential equation (SDE) for the latent state and covariance dynamics. We introduce a novel two-filter, analytical form for the posterior with a Bayesian derivation, which yields analytical updates which do not require the forward-pass to be pre-computed. Using this analytical and efficient computation of the posterior, we provide an EM procedure which estimates the parameters of the SDE, naturally incorporating irregularly sampled measurements. Generalizing the learning of latent linear dynamical systems (LDS) to continuous-time may extend the use of the hybrid Kalman filter to data which is not regularly sampled or has intermittent missing values, and can extend the power of non-linear system identification methods such as switching LDS (SLDS), which rely on EM for the linear discrete-time Kalman filter as a sub-unit for learning locally linearized behavior of a non-linear system. We apply the method by learning the parameters of a latent, multivariate Fokker-Planck SDE representing a toggle-switch genetic circuit using biologically realistic parameters, and compare the efficacy of learning relative to the discrete-time Kalman filter as the step-size irregularity and spectral-radius of the dynamics-matrix increases.