 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Potential of CoT for Reasoning: A Closer Look at Trace Dynamics
Feb 16, 2026Chain-of-thought (CoT) prompting is a de-facto standard technique to elicit reasoning-like responses from large language models (LLMs), allowing them to spell out individual steps before giving a final answer. While the resemblance to human-like reasoning is undeniable, the driving forces underpinning the success of CoT reasoning still remain largely unclear. In this work, we perform an in-depth analysis of CoT traces originating from competition-level mathematics questions, with the aim of better understanding how, and which parts of CoT actually contribute to the final answer. To this end, we introduce the notion of a potential, quantifying how much a given part of CoT increases the likelihood of a correct completion. Upon examination of reasoning traces through the lens of the potential, we identify surprising patterns including (1) its often strong non-monotonicity (due to reasoning tangents), (2) very sharp but sometimes tough to interpret spikes (reasoning insights and jumps) as well as (3) at times lucky guesses, where the model arrives at the correct answer without providing any relevant justifications before. While some of the behaviours of the potential are readily interpretable and align with human intuition (such as insights and tangents), others remain difficult to understand from a human perspective. To further quantify the reliance of LLMs on reasoning insights, we investigate the notion of CoT transferability, where we measure the potential of a weaker model under the partial CoT from another, stronger model. Indeed aligning with our previous results, we find that as little as 20% of partial CoT can ``unlock'' the performance of the weaker model on problems that were previously unsolvable for it, highlighting that a large part of the mechanics underpinning CoT are transferable.
LSTM-MAS: A Long Short-Term Memory Inspired Multi-Agent System for Long-Context Understanding
Jan 17, 2026Effectively processing long contexts remains a fundamental yet unsolved challenge for large language models (LLMs). Existing single-LLM-based methods primarily reduce the context window or optimize the attention mechanism, but they often encounter additional computational costs or constrained expanded context length. While multi-agent-based frameworks can mitigate these limitations, they remain susceptible to the accumulation of errors and the propagation of hallucinations. In this work, we draw inspiration from the Long Short-Term Memory (LSTM) architecture to design a Multi-Agent System called LSTM-MAS, emulating LSTM's hierarchical information flow and gated memory mechanisms for long-context understanding. Specifically, LSTM-MAS organizes agents in a chained architecture, where each node comprises a worker agent for segment-level comprehension, a filter agent for redundancy reduction, a judge agent for continuous error detection, and a manager agent for globally regulates information propagation and retention, analogous to LSTM and its input gate, forget gate, constant error carousel unit, and output gate. These novel designs enable controlled information transfer and selective long-term dependency modeling across textual segments, which can effectively avoid error accumulation and hallucination propagation. We conducted an extensive evaluation of our method. Compared with the previous best multi-agent approach, CoA, our model achieves improvements of 40.93%, 43.70%,121.57% and 33.12%, on NarrativeQA, Qasper, HotpotQA, and MuSiQue, respectively.
AdaptPrompt: Parameter-Efficient Adaptation of VLMs for Generalizable Deepfake Detection
Dec 19, 2025
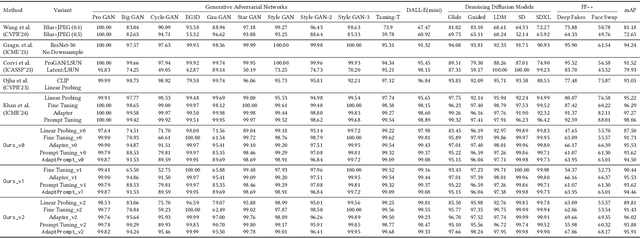
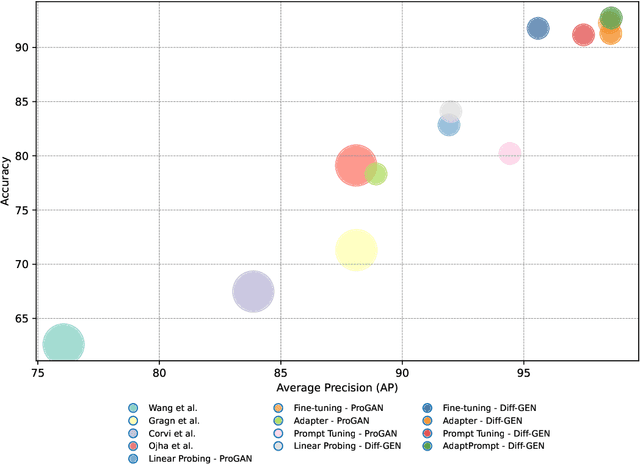
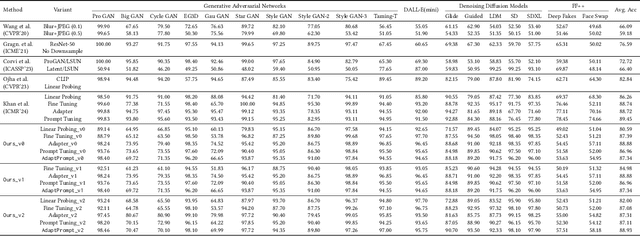
Recent advances in image generation have led to the widespread availability of highly realistic synthetic media, increasing the difficulty of reliable deepfake detection. A key challenge is generalization, as detectors trained on a narrow class of generators often fail when confronted with unseen models. In this work, we address the pressing need for generalizable detection by leveraging large vision-language models, specifically CLIP, to identify synthetic content across diverse generative techniques. First, we introduce Diff-Gen, a large-scale benchmark dataset comprising 100k diffusion-generated fakes that capture broad spectral artifacts unlike traditional GAN datasets. Models trained on Diff-Gen demonstrate stronger cross-domain generalization, particularly on previously unseen image generators. Second, we propose AdaptPrompt, a parameter-efficient transfer learning framework that jointly learns task-specific textual prompts and visual adapters while keeping the CLIP backbone frozen. We further show via layer ablation that pruning the final transformer block of the vision encoder enhances the retention of high-frequency generative artifacts, significantly boosting detection accuracy. Our evaluation spans 25 challenging test sets, covering synthetic content generated by GANs, diffusion models, and commercial tools, establishing a new state-of-the-art in both standard and cross-domain scenarios. We further demonstrate the framework's versatility through few-shot generalization (using as few as 320 images) and source attribution, enabling the precise identification of generator architectures in closed-set settings.
CityWalker: Learning Embodied Urban Navigation from Web-Scale Videos
Nov 26, 2024



Navigating dynamic urban environments presents significant challenges for embodied agents, requiring advanced spatial reasoning and adherence to common-sense norms. Despite progress, existing visual navigation methods struggle in map-free or off-street settings, limiting the deployment of autonomous agents like last-mile delivery robots. To overcome these obstacles, we propose a scalable, data-driven approach for human-like urban navigation by training agents on thousands of hours of in-the-wild city walking and driving videos sourced from the web. We introduce a simple and scalable data processing pipeline that extracts action supervision from these videos, enabling large-scale imitation learning without costly annotations. Our model learns sophisticated navigation policies to handle diverse challenges and critical scenarios. Experimental results show that training on large-scale, diverse datasets significantly enhances navigation performance, surpassing current methods. This work shows the potential of using abundant online video data to develop robust navigation policies for embodied agents in dynamic urban settings. https://ai4ce.github.io/CityWalker/
Inducing Systematicity in Transformers by Attending to Structurally Quantized Embeddings
Feb 09, 2024



Transformers generalize to novel compositions of structures and entities after being trained on a complex dataset, but easily overfit on datasets of insufficient complexity. We observe that when the training set is sufficiently complex, the model encodes sentences that have a common syntactic structure using a systematic attention pattern. Inspired by this observation, we propose SQ-Transformer (Structurally Quantized) that explicitly encourages systematicity in the embeddings and attention layers, even with a training set of low complexity. At the embedding level, we introduce Structure-oriented Vector Quantization (SoVQ) to cluster word embeddings into several classes of structurally equivalent entities. At the attention level, we devise the Systematic Attention Layer (SAL) and an alternative, Systematically Regularized Layer (SRL) that operate on the quantized word embeddings so that sentences of the same structure are encoded with invariant or similar attention patterns. Empirically, we show that SQ-Transformer achieves stronger compositional generalization than the vanilla Transformer on multiple low-complexity semantic parsing and machine translation datasets. In our analysis, we show that SoVQ indeed learns a syntactically clustered embedding space and SAL/SRL induces generalizable attention patterns, which lead to improved systematicity.
Data Factors for Better Compositional Generalization
Nov 08, 2023



Recent diagnostic datasets on compositional generalization, such as SCAN (Lake and Baroni, 2018) and COGS (Kim and Linzen, 2020), expose severe problems in models trained from scratch on these datasets. However, in contrast to this poor performance, state-of-the-art models trained on larger and more general datasets show better generalization ability. In this work, to reconcile this inconsistency, we conduct an empirical analysis by training Transformer models on a variety of training sets with different data factors, including dataset scale, pattern complexity, example difficulty, etc. First, we show that increased dataset complexity can lead to better generalization behavior on multiple different generalization challenges. To further understand this improvement, we show two axes of the benefit from more complex datasets: they provide more diverse examples so compositional understanding becomes more effective, and they also prevent ungeneralizable memorization of the examples due to reduced example repetition frequency. Finally, we explore how training examples of different difficulty levels influence generalization differently. On synthetic datasets, simple examples invoke stronger compositionality than hard examples do. On larger-scale real language datasets, while hard examples become more important potentially to ensure decent data coverage, a balanced mixture of simple and hard examples manages to induce the strongest generalizability. The code and data for this work are available at https://github.com/owenzx/data4comp
Mutual Exclusivity Training and Primitive Augmentation to Induce Compositionality
Nov 28, 2022Recent datasets expose the lack of the systematic generalization ability in standard sequence-to-sequence models. In this work, we analyze this behavior of seq2seq models and identify two contributing factors: a lack of mutual exclusivity bias (i.e., a source sequence already mapped to a target sequence is less likely to be mapped to other target sequences), and the tendency to memorize whole examples rather than separating structures from contents. We propose two techniques to address these two issues respectively: Mutual Exclusivity Training that prevents the model from producing seen generations when facing novel, unseen examples via an unlikelihood-based loss; and prim2primX data augmentation that automatically diversifies the arguments of every syntactic function to prevent memorizing and provide a compositional inductive bias without exposing test-set data. Combining these two techniques, we show substantial empirical improvements using standard sequence-to-sequence models (LSTMs and Transformers) on two widely-used compositionality datasets: SCAN and COGS. Finally, we provide analysis characterizing the improvements as well as the remaining challenges, and provide detailed ablations of our method. Our code is available at https://github.com/owenzx/met-primaug
Structural Biases for Improving Transformers on Translation into Morphologically Rich Languages
Aug 11, 2022
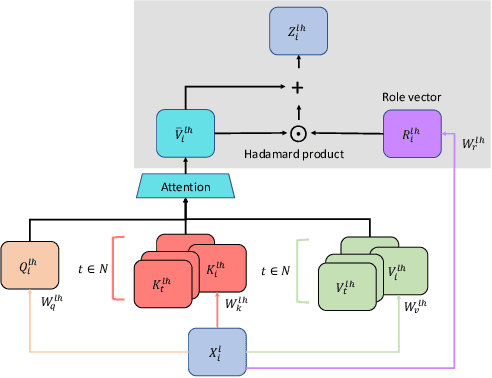

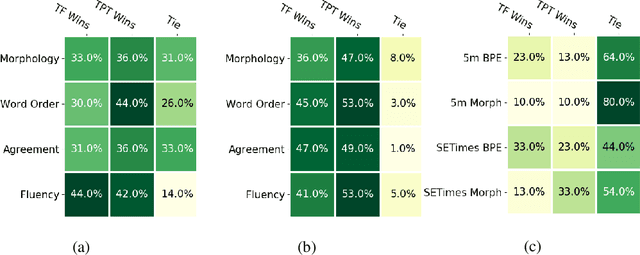
Machine translation has seen rapid progress with the advent of Transformer-based models. These models have no explicit linguistic structure built into them, yet they may still implicitly learn structured relationships by attending to relevant tokens. We hypothesize that this structural learning could be made more robust by explicitly endowing Transformers with a structural bias, and we investigate two methods for building in such a bias. One method, the TP-Transformer, augments the traditional Transformer architecture to include an additional component to represent structure. The second method imbues structure at the data level by segmenting the data with morphological tokenization. We test these methods on translating from English into morphologically rich languages, Turkish and Inuktitut, and consider both automatic metrics and human evaluations. We find that each of these two approaches allows the network to achieve better performance, but this improvement is dependent on the size of the dataset. In sum, structural encoding methods make Transformers more sample-efficient, enabling them to perform better from smaller amounts of data.
* Revised edition to 4th Workshop on Technologies for MT of Low Resource Languages
Learning and Analyzing Generation Order for Undirected Sequence Models
Dec 16, 2021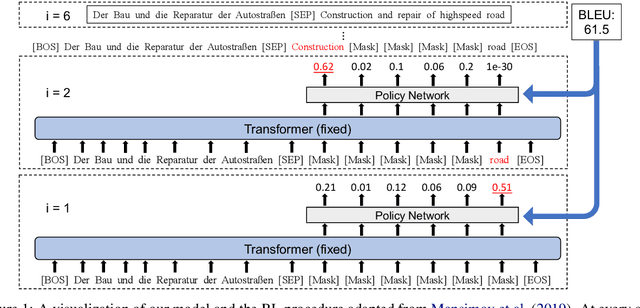


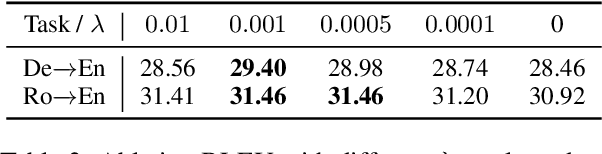
Undirected neural sequence models have achieved performance competitive with the state-of-the-art directed sequence models that generate monotonically from left to right in machine translation tasks. In this work, we train a policy that learns the generation order for a pre-trained, undirected translation model via reinforcement learning. We show that the translations decoded by our learned orders achieve higher BLEU scores than the outputs decoded from left to right or decoded by the learned order from Mansimov et al. (2019) on the WMT'14 German-English translation task. On examples with a maximum source and target length of 30 from De-En, WMT'16 English-Romanian, and WMT'21 English-Chinese translation tasks, our learned order outperforms all heuristic generation orders on four out of six tasks. We next carefully analyze the learned order patterns via qualitative and quantitative analysis. We show that our policy generally follows an outer-to-inner order, predicting the left-most and right-most positions first, and then moving toward the middle while skipping less important words at the beginning. Furthermore, the policy usually predicts positions for a single syntactic constituent structure in consecutive steps. We believe our findings could provide more insights on the mechanism of undirected generation models and encourage further research in this direction. Our code is publicly available at https://github.com/jiangycTarheel/undirected-generation
Inducing Transformer's Compositional Generalization Ability via Auxiliary Sequence Prediction Tasks
Sep 30, 2021
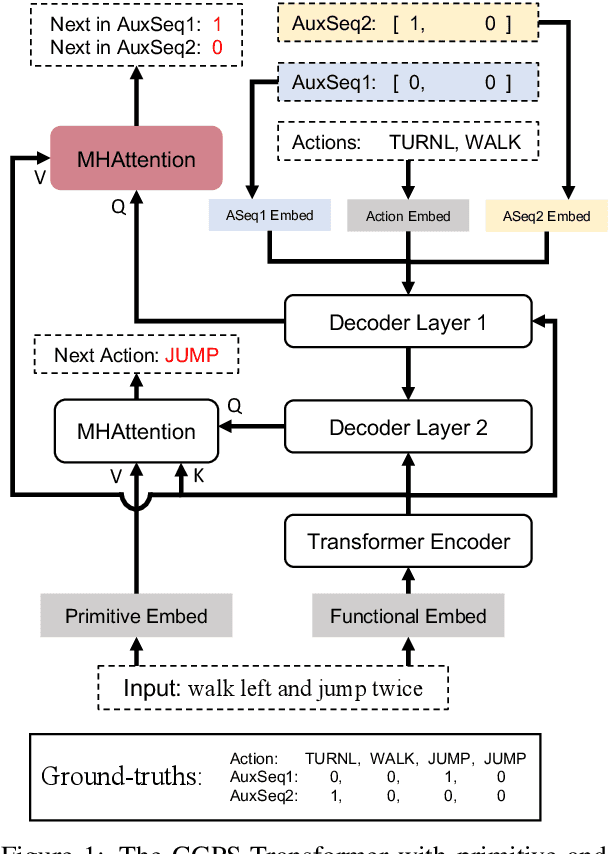


Systematic compositionality is an essential mechanism in human language, allowing the recombination of known parts to create novel expressions. However, existing neural models have been shown to lack this basic ability in learning symbolic structures. Motivated by the failure of a Transformer model on the SCAN compositionality challenge (Lake and Baroni, 2018), which requires parsing a command into actions, we propose two auxiliary sequence prediction tasks that track the progress of function and argument semantics, as additional training supervision. These automatically-generated sequences are more representative of the underlying compositional symbolic structures of the input data. During inference, the model jointly predicts the next action and the next tokens in the auxiliary sequences at each step. Experiments on the SCAN dataset show that our method encourages the Transformer to understand compositional structures of the command, improving its accuracy on multiple challenging splits from <= 10% to 100%. With only 418 (5%) training instances, our approach still achieves 97.8% accuracy on the MCD1 split. Therefore, we argue that compositionality can be induced in Transformers given minimal but proper guidance. We also show that a better result is achieved using less contextualized vectors as the attention's query, providing insights into architecture choices in achieving systematic compositionality. Finally, we show positive generalization results on the groundedSCAN task (Ruis et al., 2020). Our code is publicly available at: https://github.com/jiangycTarheel/compositional-auxseq