 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHoVer: A Dataset for Many-Hop Fact Extraction And Claim Verification
Nov 16, 2020

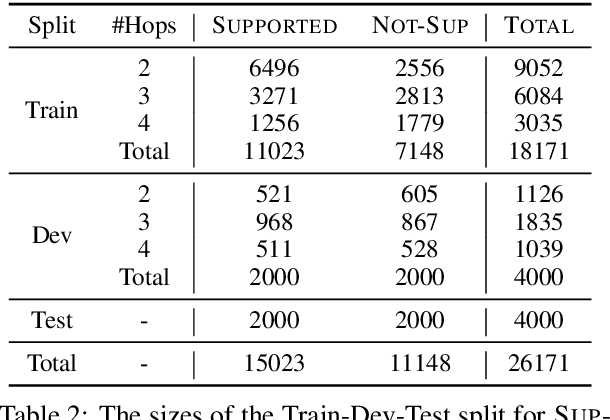
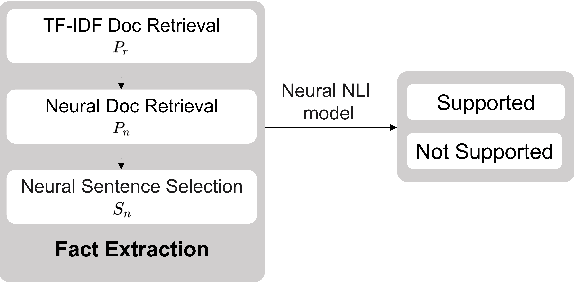
We introduce HoVer (HOppy VERification), a dataset for many-hop evidence extraction and fact verification. It challenges models to extract facts from several Wikipedia articles that are relevant to a claim and classify whether the claim is Supported or Not-Supported by the facts. In HoVer, the claims require evidence to be extracted from as many as four English Wikipedia articles and embody reasoning graphs of diverse shapes. Moreover, most of the 3/4-hop claims are written in multiple sentences, which adds to the complexity of understanding long-range dependency relations such as coreference. We show that the performance of an existing state-of-the-art semantic-matching model degrades significantly on our dataset as the number of reasoning hops increases, hence demonstrating the necessity of many-hop reasoning to achieve strong results. We hope that the introduction of this challenging dataset and the accompanying evaluation task will encourage research in many-hop fact retrieval and information verification. We make the HoVer dataset publicly available at https://hover-nlp.github.io
Sampling Bias in Deep Active Classification: An Empirical Study
Sep 20, 2019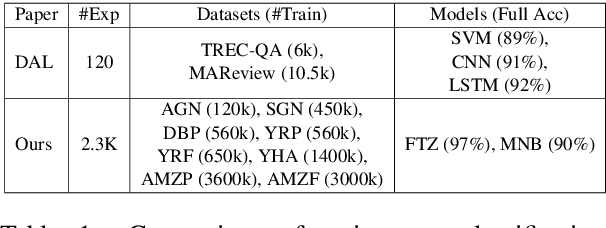
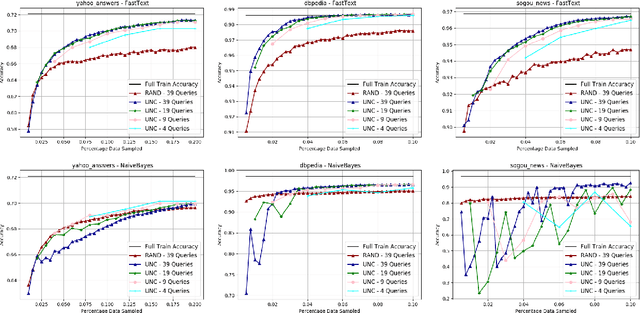
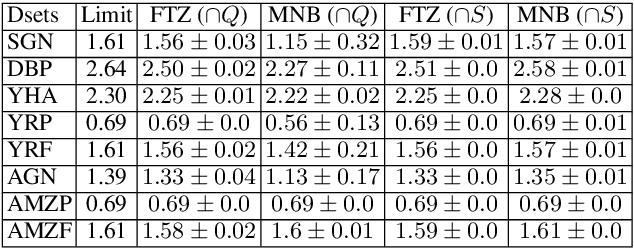
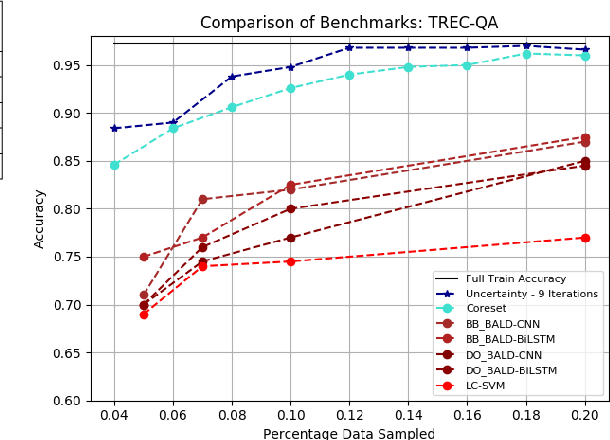
The exploding cost and time needed for data labeling and model training are bottlenecks for training DNN models on large datasets. Identifying smaller representative data samples with strategies like active learning can help mitigate such bottlenecks. Previous works on active learning in NLP identify the problem of sampling bias in the samples acquired by uncertainty-based querying and develop costly approaches to address it. Using a large empirical study, we demonstrate that active set selection using the posterior entropy of deep models like FastText.zip (FTZ) is robust to sampling biases and to various algorithmic choices (query size and strategies) unlike that suggested by traditional literature. We also show that FTZ based query strategy produces sample sets similar to those from more sophisticated approaches (e.g ensemble networks). Finally, we show the effectiveness of the selected samples by creating tiny high-quality datasets, and utilizing them for fast and cheap training of large models. Based on the above, we propose a simple baseline for deep active text classification that outperforms the state-of-the-art. We expect the presented work to be useful and informative for dataset compression and for problems involving active, semi-supervised or online learning scenarios. Code and models are available at: https://github.com/drimpossible/Sampling-Bias-Active-Learning
A Characterization of Mean Squared Error for Estimator with Bagging
Aug 07, 2019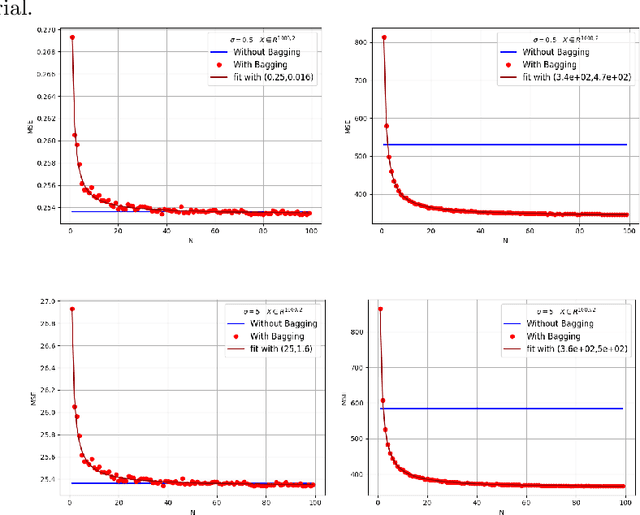
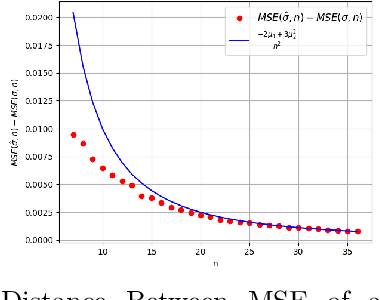
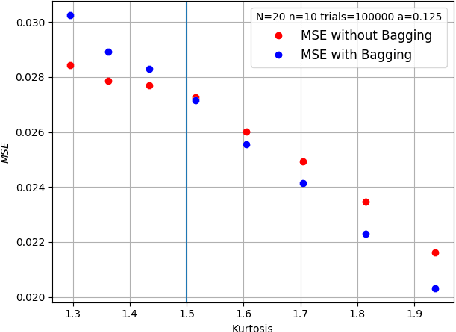
Bagging can significantly improve the generalization performance of unstable machine learning algorithms such as trees or neural networks. Though bagging is now widely used in practice and many empirical studies have explored its behavior, we still know little about the theoretical properties of bagged predictions. In this paper, we theoretically investigate how the bagging method can reduce the Mean Squared Error (MSE) when applied on a statistical estimator. First, we prove that for any estimator, increasing the number of bagged estimators $N$ in the average can only reduce the MSE. This intuitive result, observed empirically and discussed in the literature, has not yet been rigorously proved. Second, we focus on the standard estimator of variance called unbiased sample variance and we develop an exact analytical expression of the MSE for this estimator with bagging. This allows us to rigorously discuss the number of iterations $N$ and the batch size $m$ of the bagging method. From this expression, we state that only if the kurtosis of the distribution is greater than $\frac{3}{2}$, the MSE of the variance estimator can be reduced with bagging. This result is important because it demonstrates that for distribution with low kurtosis, bagging can only deteriorate the performance of a statistical prediction. Finally, we propose a novel general-purpose algorithm to estimate with high precision the variance of a sample.