 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSampling Bias in Deep Active Classification: An Empirical Study
Paper and Code
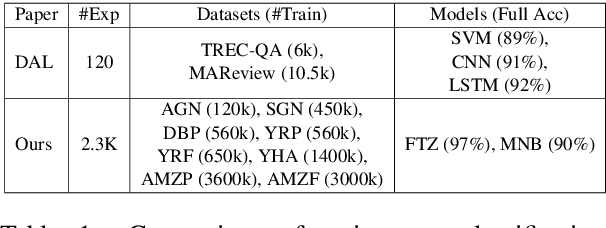
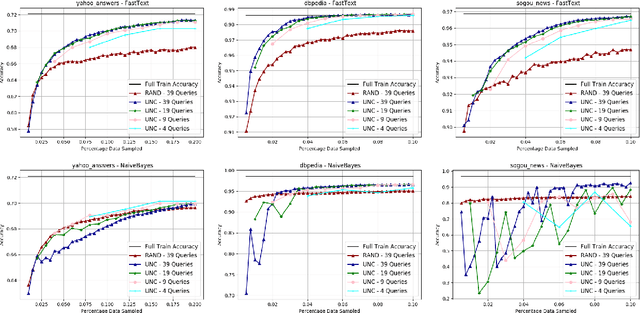
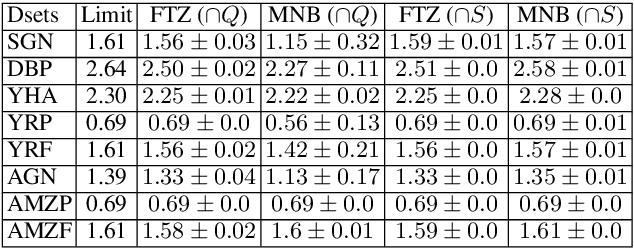
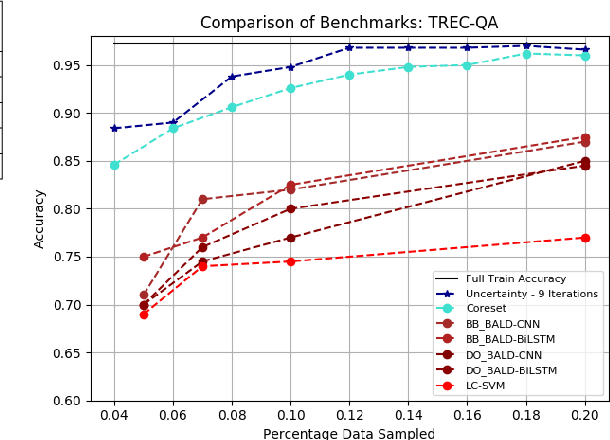
The exploding cost and time needed for data labeling and model training are bottlenecks for training DNN models on large datasets. Identifying smaller representative data samples with strategies like active learning can help mitigate such bottlenecks. Previous works on active learning in NLP identify the problem of sampling bias in the samples acquired by uncertainty-based querying and develop costly approaches to address it. Using a large empirical study, we demonstrate that active set selection using the posterior entropy of deep models like FastText.zip (FTZ) is robust to sampling biases and to various algorithmic choices (query size and strategies) unlike that suggested by traditional literature. We also show that FTZ based query strategy produces sample sets similar to those from more sophisticated approaches (e.g ensemble networks). Finally, we show the effectiveness of the selected samples by creating tiny high-quality datasets, and utilizing them for fast and cheap training of large models. Based on the above, we propose a simple baseline for deep active text classification that outperforms the state-of-the-art. We expect the presented work to be useful and informative for dataset compression and for problems involving active, semi-supervised or online learning scenarios. Code and models are available at: https://github.com/drimpossible/Sampling-Bias-Active-Learning