 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs Information Density Uniform when Utterances are Grounded on Perception and Discourse?
Feb 16, 2026The Uniform Information Density (UID) hypothesis posits that speakers are subject to a communicative pressure to distribute information evenly within utterances, minimising surprisal variance. While this hypothesis has been tested empirically, prior studies are limited exclusively to text-only inputs, abstracting away from the perceptual context in which utterances are produced. In this work, we present the first computational study of UID in visually grounded settings. We estimate surprisal using multilingual vision-and-language models over image-caption data in 30 languages and visual storytelling data in 13 languages, together spanning 11 families. We find that grounding on perception consistently smooths the distribution of information, increasing both global and local uniformity across typologically diverse languages compared to text-only settings. In visual narratives, grounding in both image and discourse contexts has additional effects, with the strongest surprisal reductions occurring at the onset of discourse units. Overall, this study takes a first step towards modelling the temporal dynamics of information flow in ecologically plausible, multimodal language use, and finds that grounded language exhibits greater information uniformity, supporting a context-sensitive formulation of UID.
A Grounded Typology of Word Classes
Dec 13, 2024We propose a grounded approach to meaning in language typology. We treat data from perceptual modalities, such as images, as a language-agnostic representation of meaning. Hence, we can quantify the function--form relationship between images and captions across languages. Inspired by information theory, we define "groundedness", an empirical measure of contextual semantic contentfulness (formulated as a difference in surprisal) which can be computed with multilingual multimodal language models. As a proof of concept, we apply this measure to the typology of word classes. Our measure captures the contentfulness asymmetry between functional (grammatical) and lexical (content) classes across languages, but contradicts the view that functional classes do not convey content. Moreover, we find universal trends in the hierarchy of groundedness (e.g., nouns > adjectives > verbs), and show that our measure partly correlates with psycholinguistic concreteness norms in English. We release a dataset of groundedness scores for 30 languages. Our results suggest that the grounded typology approach can provide quantitative evidence about semantic function in language.
Structural Biases for Improving Transformers on Translation into Morphologically Rich Languages
Aug 11, 2022
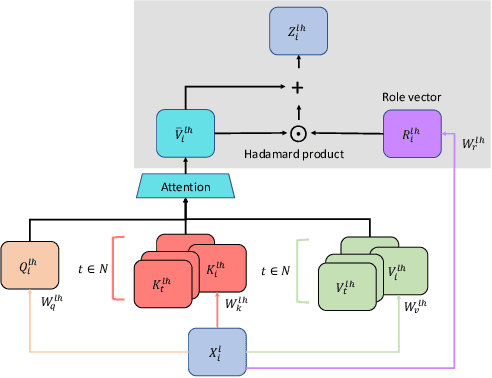

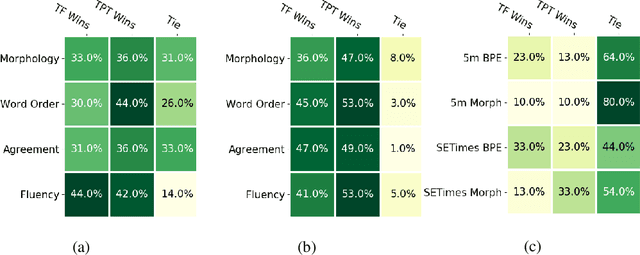
Machine translation has seen rapid progress with the advent of Transformer-based models. These models have no explicit linguistic structure built into them, yet they may still implicitly learn structured relationships by attending to relevant tokens. We hypothesize that this structural learning could be made more robust by explicitly endowing Transformers with a structural bias, and we investigate two methods for building in such a bias. One method, the TP-Transformer, augments the traditional Transformer architecture to include an additional component to represent structure. The second method imbues structure at the data level by segmenting the data with morphological tokenization. We test these methods on translating from English into morphologically rich languages, Turkish and Inuktitut, and consider both automatic metrics and human evaluations. We find that each of these two approaches allows the network to achieve better performance, but this improvement is dependent on the size of the dataset. In sum, structural encoding methods make Transformers more sample-efficient, enabling them to perform better from smaller amounts of data.
* Revised edition to 4th Workshop on Technologies for MT of Low Resource Languages
Morphology Matters: A Multilingual Language Modeling Analysis
Dec 11, 2020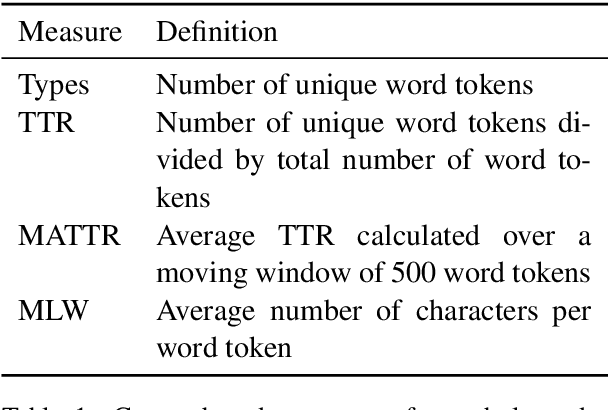
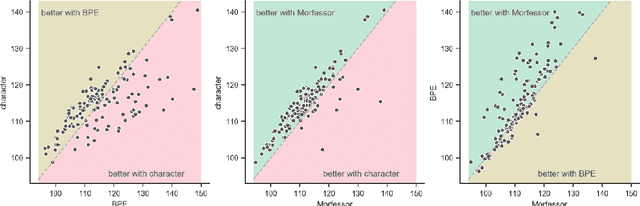
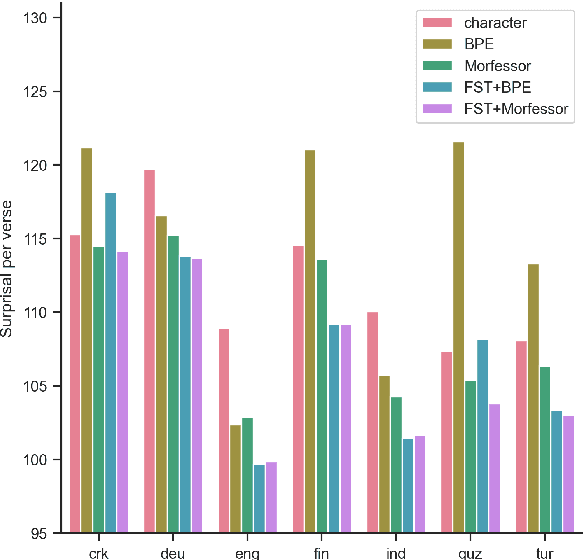
Prior studies in multilingual language modeling (e.g., Cotterell et al., 2018; Mielke et al., 2019) disagree on whether or not inflectional morphology makes languages harder to model. We attempt to resolve the disagreement and extend those studies. We compile a larger corpus of 145 Bible translations in 92 languages and a larger number of typological features. We fill in missing typological data for several languages and consider corpus-based measures of morphological complexity in addition to expert-produced typological features. We find that several morphological measures are significantly associated with higher surprisal when LSTM models are trained with BPE-segmented data. We also investigate linguistically-motivated subword segmentation strategies like Morfessor and Finite-State Transducers (FSTs) and find that these segmentation strategies yield better performance and reduce the impact of a language's morphology on language modeling.
Neural Polysynthetic Language Modelling
May 13, 2020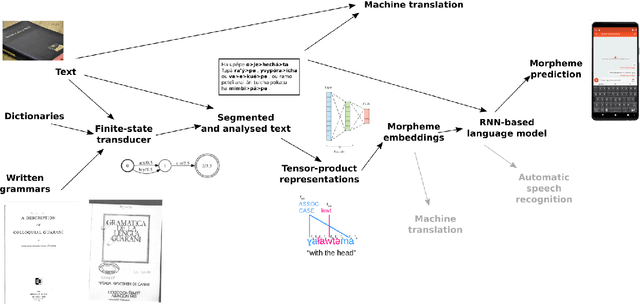

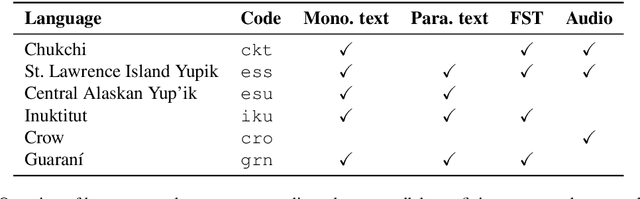
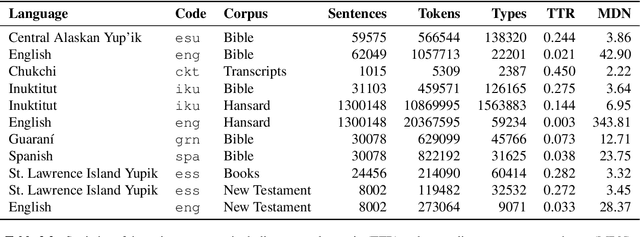
Research in natural language processing commonly assumes that approaches that work well for English and and other widely-used languages are "language agnostic". In high-resource languages, especially those that are analytic, a common approach is to treat morphologically-distinct variants of a common root as completely independent word types. This assumes, that there are limited morphological inflections per root, and that the majority will appear in a large enough corpus, so that the model can adequately learn statistics about each form. Approaches like stemming, lemmatization, or subword segmentation are often used when either of those assumptions do not hold, particularly in the case of synthetic languages like Spanish or Russian that have more inflection than English. In the literature, languages like Finnish or Turkish are held up as extreme examples of complexity that challenge common modelling assumptions. Yet, when considering all of the world's languages, Finnish and Turkish are closer to the average case. When we consider polysynthetic languages (those at the extreme of morphological complexity), approaches like stemming, lemmatization, or subword modelling may not suffice. These languages have very high numbers of hapax legomena, showing the need for appropriate morphological handling of words, without which it is not possible for a model to capture enough word statistics. We examine the current state-of-the-art in language modelling, machine translation, and text prediction for four polysynthetic languages: Guaran\'i, St. Lawrence Island Yupik, Central Alaskan Yupik, and Inuktitut. We then propose a novel framework for language modelling that combines knowledge representations from finite-state morphological analyzers with Tensor Product Representations in order to enable neural language models capable of handling the full range of typologically variant languages.