 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMorphology Matters: A Multilingual Language Modeling Analysis
Paper and Code
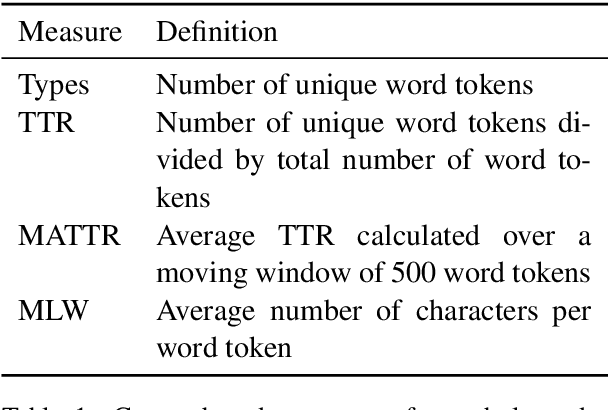
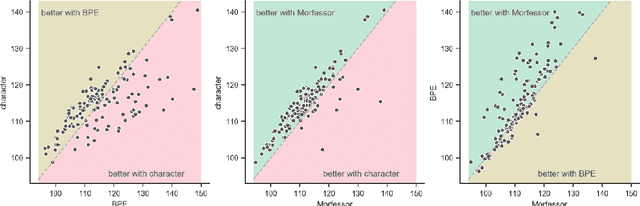
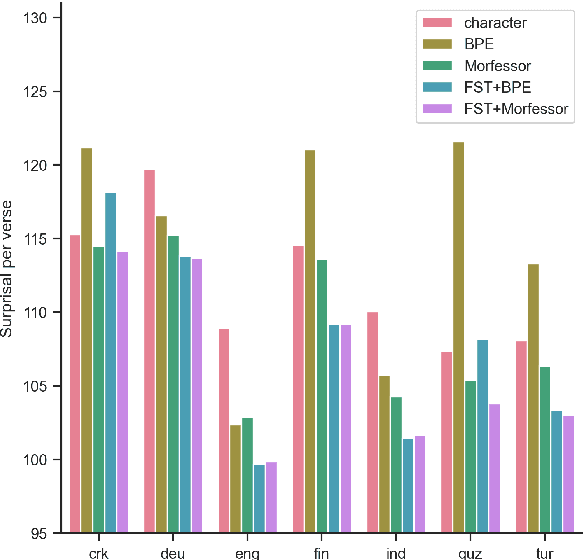
Prior studies in multilingual language modeling (e.g., Cotterell et al., 2018; Mielke et al., 2019) disagree on whether or not inflectional morphology makes languages harder to model. We attempt to resolve the disagreement and extend those studies. We compile a larger corpus of 145 Bible translations in 92 languages and a larger number of typological features. We fill in missing typological data for several languages and consider corpus-based measures of morphological complexity in addition to expert-produced typological features. We find that several morphological measures are significantly associated with higher surprisal when LSTM models are trained with BPE-segmented data. We also investigate linguistically-motivated subword segmentation strategies like Morfessor and Finite-State Transducers (FSTs) and find that these segmentation strategies yield better performance and reduce the impact of a language's morphology on language modeling.