 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying Consistency in LLM Logical Reasoning via Structural Uncertainty
Jun 15, 2026Large language models can arrive at the same answer through reasoning paths that are unstable, contradictory, or difficult to rank consistently -- a failure mode especially prevalent in multi-step deductive reasoning. Existing methods assess reliability primarily through output dispersion -- measuring how much sampled answers differ -- but this discards a complementary signal: whether the model can consistently rank competing reasoning candidates. We propose structural uncertainty, a consistency-aware framework derived from the stability of self-preference-induced rankings over sampled reasoning solutions. Given a query, we generate multiple candidate solutions and ask the model to judge pairwise preferences among its own outputs. We aggregate self-preferences into ranking distributions via Bradley-Terry modeling with PageRank, and decompose the signal into two entropy-based components: across-trial ranking instability and within-trial candidate ambiguity. Across five LLMs and eight benchmarks, structural signals provide information complementary to answer dispersion: on logical and mathematical reasoning tasks, the combination improves identification of unreliable instances, while on factual retrieval the structural signal collapses toward uniformity, diagnosing a regime boundary where reasoning-level consistency evaluation is uninformative. The two components relate differently to accuracy: within-trial ambiguity correlates positively with correctness -- consistent with settings where multiple plausible solution paths remain competitive -- while across-trial instability correlates negatively, signaling unreliable reasoning. Structural uncertainty is best understood not as a universal confidence estimator, but as a regime-sensitive evaluator of logical reasoning consistency.
Efficient Classification of Long Documents Using Transformers
Mar 21, 2022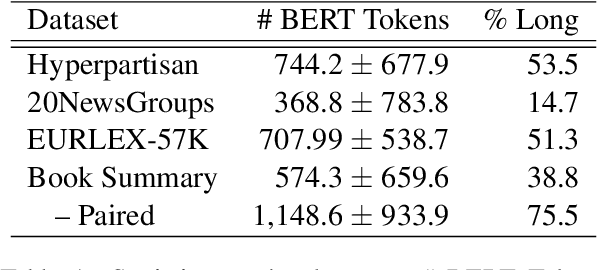
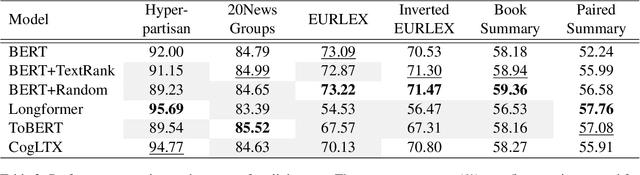
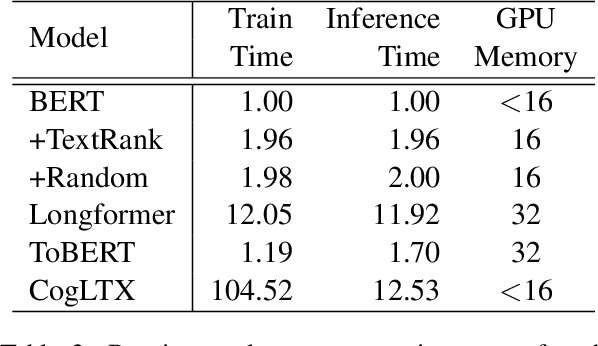
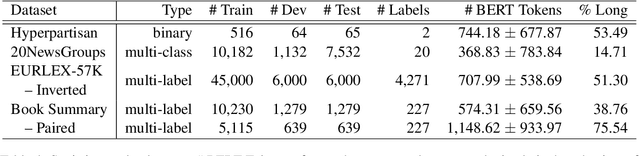
Several methods have been proposed for classifying long textual documents using Transformers. However, there is a lack of consensus on a benchmark to enable a fair comparison among different approaches. In this paper, we provide a comprehensive evaluation of the relative efficacy measured against various baselines and diverse datasets -- both in terms of accuracy as well as time and space overheads. Our datasets cover binary, multi-class, and multi-label classification tasks and represent various ways information is organized in a long text (e.g. information that is critical to making the classification decision is at the beginning or towards the end of the document). Our results show that more complex models often fail to outperform simple baselines and yield inconsistent performance across datasets. These findings emphasize the need for future studies to consider comprehensive baselines and datasets that better represent the task of long document classification to develop robust models.
A Digital Corpus of St. Lawrence Island Yupik
Jan 26, 2021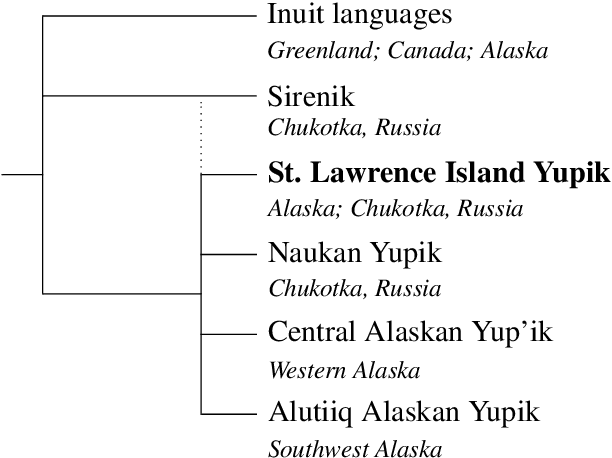
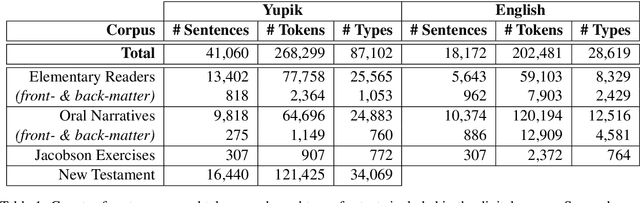
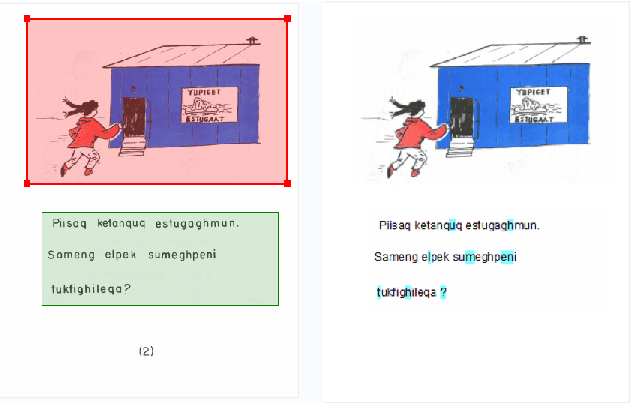

St. Lawrence Island Yupik (ISO 639-3: ess) is an endangered polysynthetic language in the Inuit-Yupik language family indigenous to Alaska and Chukotka. This work presents a step-by-step pipeline for the digitization of written texts, and the first publicly available digital corpus for St. Lawrence Island Yupik, created using that pipeline. This corpus has great potential for future linguistic inquiry and research in NLP. It was also developed for use in Yupik language education and revitalization, with a primary goal of enabling easy access to Yupik texts by educators and by members of the Yupik community. A secondary goal is to support development of language technology such as spell-checkers, text-completion systems, interactive e-books, and language learning apps for use by the Yupik community.
Morphology Matters: A Multilingual Language Modeling Analysis
Dec 11, 2020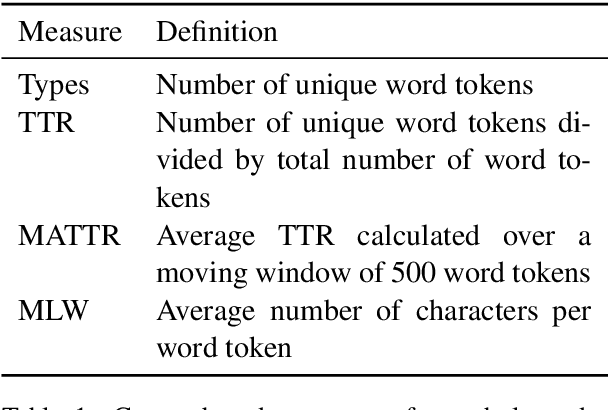
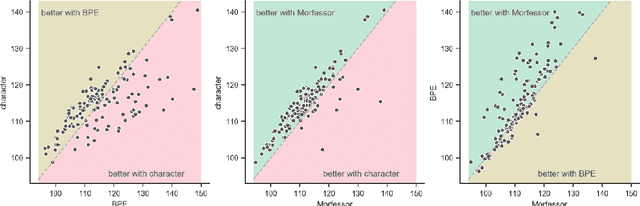
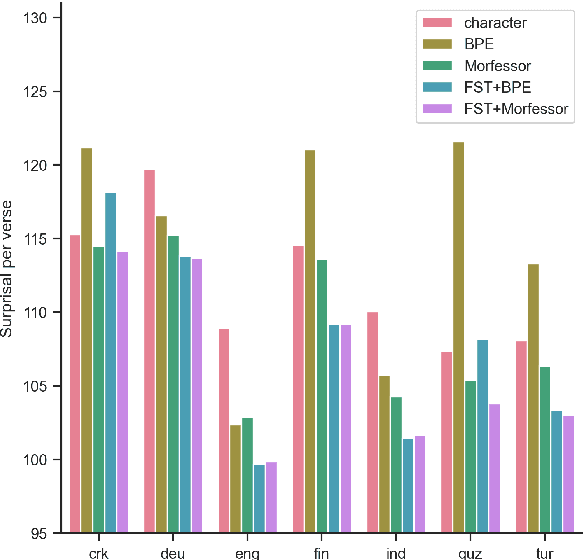
Prior studies in multilingual language modeling (e.g., Cotterell et al., 2018; Mielke et al., 2019) disagree on whether or not inflectional morphology makes languages harder to model. We attempt to resolve the disagreement and extend those studies. We compile a larger corpus of 145 Bible translations in 92 languages and a larger number of typological features. We fill in missing typological data for several languages and consider corpus-based measures of morphological complexity in addition to expert-produced typological features. We find that several morphological measures are significantly associated with higher surprisal when LSTM models are trained with BPE-segmented data. We also investigate linguistically-motivated subword segmentation strategies like Morfessor and Finite-State Transducers (FSTs) and find that these segmentation strategies yield better performance and reduce the impact of a language's morphology on language modeling.
Neural Polysynthetic Language Modelling
May 13, 2020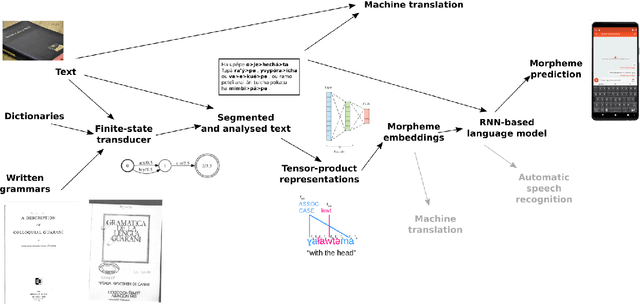

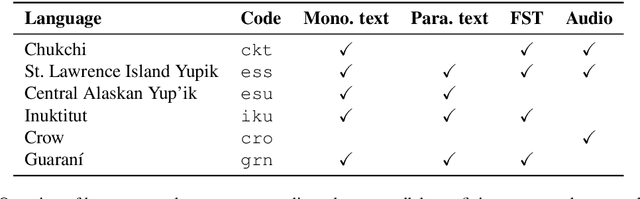
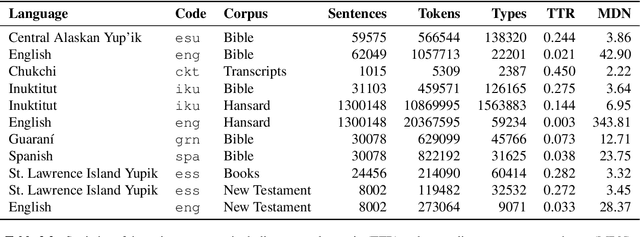
Research in natural language processing commonly assumes that approaches that work well for English and and other widely-used languages are "language agnostic". In high-resource languages, especially those that are analytic, a common approach is to treat morphologically-distinct variants of a common root as completely independent word types. This assumes, that there are limited morphological inflections per root, and that the majority will appear in a large enough corpus, so that the model can adequately learn statistics about each form. Approaches like stemming, lemmatization, or subword segmentation are often used when either of those assumptions do not hold, particularly in the case of synthetic languages like Spanish or Russian that have more inflection than English. In the literature, languages like Finnish or Turkish are held up as extreme examples of complexity that challenge common modelling assumptions. Yet, when considering all of the world's languages, Finnish and Turkish are closer to the average case. When we consider polysynthetic languages (those at the extreme of morphological complexity), approaches like stemming, lemmatization, or subword modelling may not suffice. These languages have very high numbers of hapax legomena, showing the need for appropriate morphological handling of words, without which it is not possible for a model to capture enough word statistics. We examine the current state-of-the-art in language modelling, machine translation, and text prediction for four polysynthetic languages: Guaran\'i, St. Lawrence Island Yupik, Central Alaskan Yupik, and Inuktitut. We then propose a novel framework for language modelling that combines knowledge representations from finite-state morphological analyzers with Tensor Product Representations in order to enable neural language models capable of handling the full range of typologically variant languages.