 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Polysynthetic Language Modelling
May 13, 2020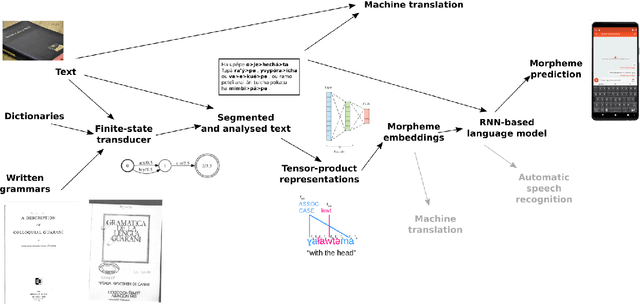

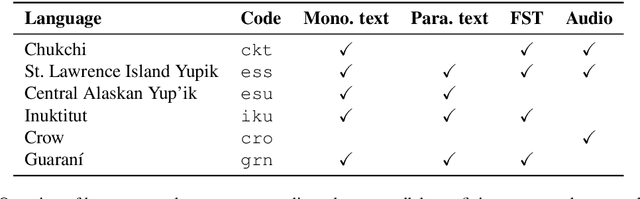
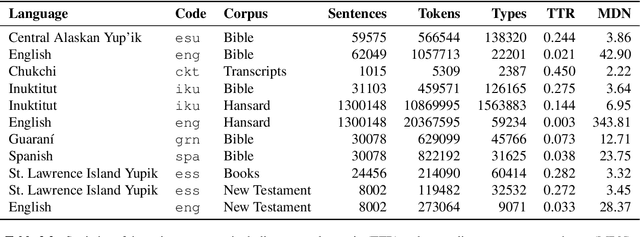
Research in natural language processing commonly assumes that approaches that work well for English and and other widely-used languages are "language agnostic". In high-resource languages, especially those that are analytic, a common approach is to treat morphologically-distinct variants of a common root as completely independent word types. This assumes, that there are limited morphological inflections per root, and that the majority will appear in a large enough corpus, so that the model can adequately learn statistics about each form. Approaches like stemming, lemmatization, or subword segmentation are often used when either of those assumptions do not hold, particularly in the case of synthetic languages like Spanish or Russian that have more inflection than English. In the literature, languages like Finnish or Turkish are held up as extreme examples of complexity that challenge common modelling assumptions. Yet, when considering all of the world's languages, Finnish and Turkish are closer to the average case. When we consider polysynthetic languages (those at the extreme of morphological complexity), approaches like stemming, lemmatization, or subword modelling may not suffice. These languages have very high numbers of hapax legomena, showing the need for appropriate morphological handling of words, without which it is not possible for a model to capture enough word statistics. We examine the current state-of-the-art in language modelling, machine translation, and text prediction for four polysynthetic languages: Guaran\'i, St. Lawrence Island Yupik, Central Alaskan Yupik, and Inuktitut. We then propose a novel framework for language modelling that combines knowledge representations from finite-state morphological analyzers with Tensor Product Representations in order to enable neural language models capable of handling the full range of typologically variant languages.
A Summary of the First Workshop on Language Technology for Language Documentation and Revitalization
Apr 27, 2020


Despite recent advances in natural language processing and other language technology, the application of such technology to language documentation and conservation has been limited. In August 2019, a workshop was held at Carnegie Mellon University in Pittsburgh to attempt to bring together language community members, documentary linguists, and technologists to discuss how to bridge this gap and create prototypes of novel and practical language revitalization technologies. This paper reports the results of this workshop, including issues discussed, and various conceived and implemented technologies for nine languages: Arapaho, Cayuga, Inuktitut, Irish Gaelic, Kidaw'ida, Kwak'wala, Ojibwe, San Juan Quiahije Chatino, and Seneca.
AlloVera: A Multilingual Allophone Database
Apr 17, 2020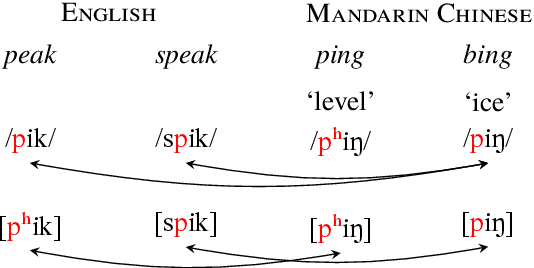



We introduce a new resource, AlloVera, which provides mappings from 218 allophones to phonemes for 14 languages. Phonemes are contrastive phonological units, and allophones are their various concrete realizations, which are predictable from phonological context. While phonemic representations are language specific, phonetic representations (stated in terms of (allo)phones) are much closer to a universal (language-independent) transcription. AlloVera allows the training of speech recognition models that output phonetic transcriptions in the International Phonetic Alphabet (IPA), regardless of the input language. We show that a "universal" allophone model, Allosaurus, built with AlloVera, outperforms "universal" phonemic models and language-specific models on a speech-transcription task. We explore the implications of this technology (and related technologies) for the documentation of endangered and minority languages. We further explore other applications for which AlloVera will be suitable as it grows, including phonological typology.
Universal Phone Recognition with a Multilingual Allophone System
Feb 26, 2020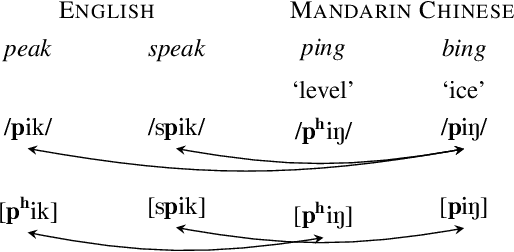

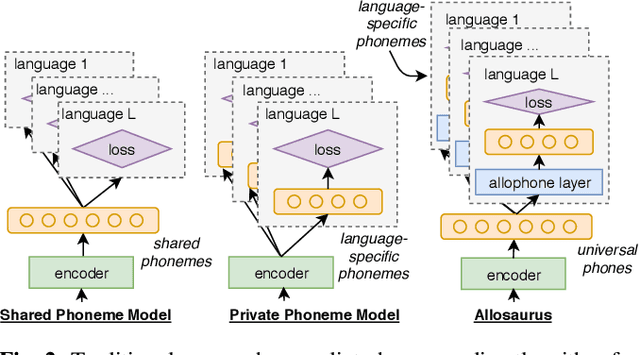

Multilingual models can improve language processing, particularly for low resource situations, by sharing parameters across languages. Multilingual acoustic models, however, generally ignore the difference between phonemes (sounds that can support lexical contrasts in a particular language) and their corresponding phones (the sounds that are actually spoken, which are language independent). This can lead to performance degradation when combining a variety of training languages, as identically annotated phonemes can actually correspond to several different underlying phonetic realizations. In this work, we propose a joint model of both language-independent phone and language-dependent phoneme distributions. In multilingual ASR experiments over 11 languages, we find that this model improves testing performance by 2% phoneme error rate absolute in low-resource conditions. Additionally, because we are explicitly modeling language-independent phones, we can build a (nearly-)universal phone recognizer that, when combined with the PHOIBLE large, manually curated database of phone inventories, can be customized into 2,000 language dependent recognizers. Experiments on two low-resourced indigenous languages, Inuktitut and Tusom, show that our recognizer achieves phone accuracy improvements of more than 17%, moving a step closer to speech recognition for all languages in the world.
Choosing Transfer Languages for Cross-Lingual Learning
Jun 07, 2019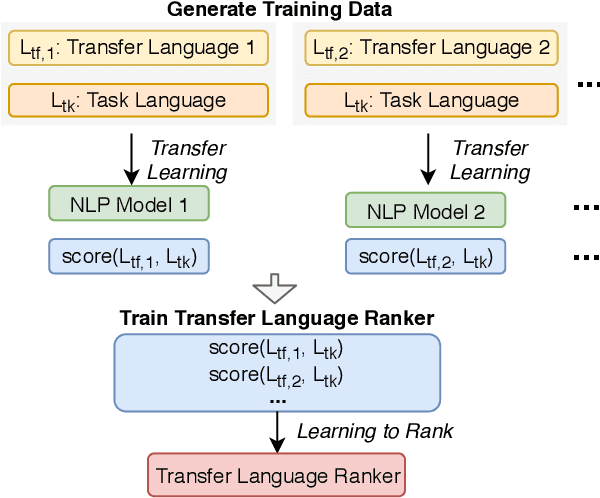
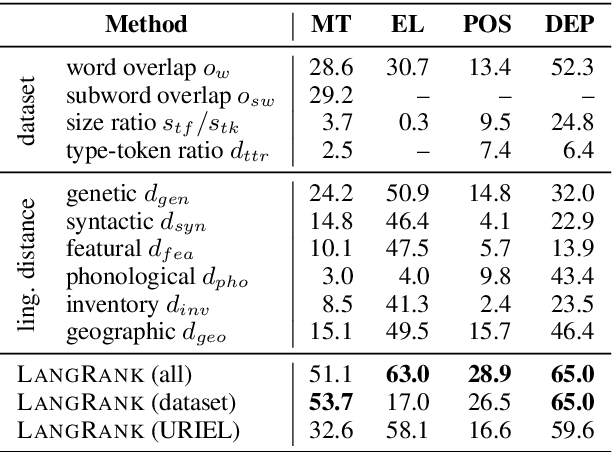
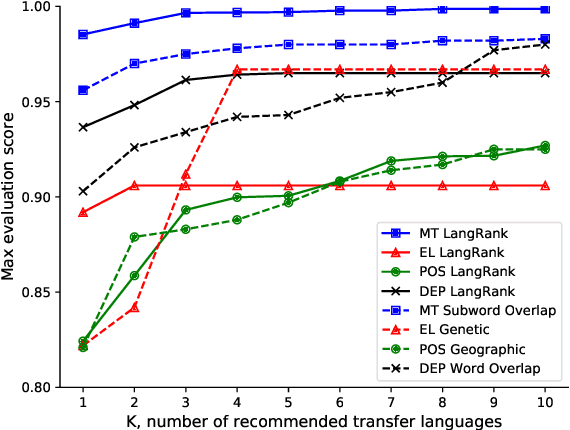
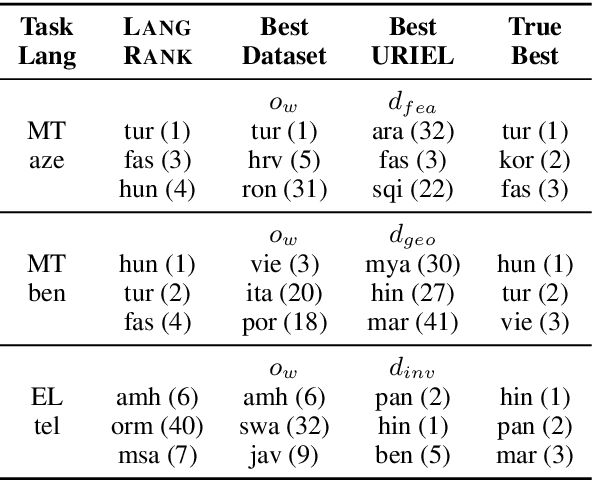
Cross-lingual transfer, where a high-resource transfer language is used to improve the accuracy of a low-resource task language, is now an invaluable tool for improving performance of natural language processing (NLP) on low-resource languages. However, given a particular task language, it is not clear which language to transfer from, and the standard strategy is to select languages based on ad hoc criteria, usually the intuition of the experimenter. Since a large number of features contribute to the success of cross-lingual transfer (including phylogenetic similarity, typological properties, lexical overlap, or size of available data), even the most enlightened experimenter rarely considers all these factors for the particular task at hand. In this paper, we consider this task of automatically selecting optimal transfer languages as a ranking problem, and build models that consider the aforementioned features to perform this prediction. In experiments on representative NLP tasks, we demonstrate that our model predicts good transfer languages much better than ad hoc baselines considering single features in isolation, and glean insights on what features are most informative for each different NLP tasks, which may inform future ad hoc selection even without use of our method. Code, data, and pre-trained models are available at https://github.com/neulab/langrank
Towards a General-Purpose Linguistic Annotation Backend
Dec 13, 2018



Language documentation is inherently a time-intensive process; transcription, glossing, and corpus management consume a significant portion of documentary linguists' work. Advances in natural language processing can help to accelerate this work, using the linguists' past decisions as training material, but questions remain about how to prioritize human involvement. In this extended abstract, we describe the beginnings of a new project that will attempt to ease this language documentation process through the use of natural language processing (NLP) technology. It is based on (1) methods to adapt NLP tools to new languages, based on recent advances in massively multilingual neural networks, and (2) backend APIs and interfaces that allow linguists to upload their data. We then describe our current progress on two fronts: automatic phoneme transcription, and glossing. Finally, we briefly describe our future directions.
Learning Language Representations for Typology Prediction
Jul 29, 2017
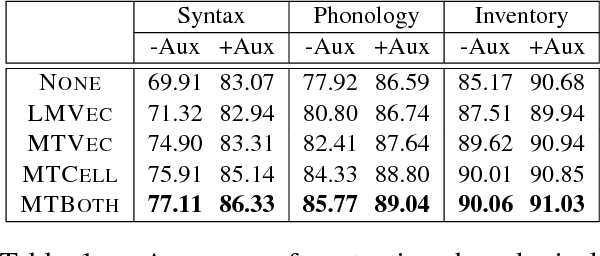

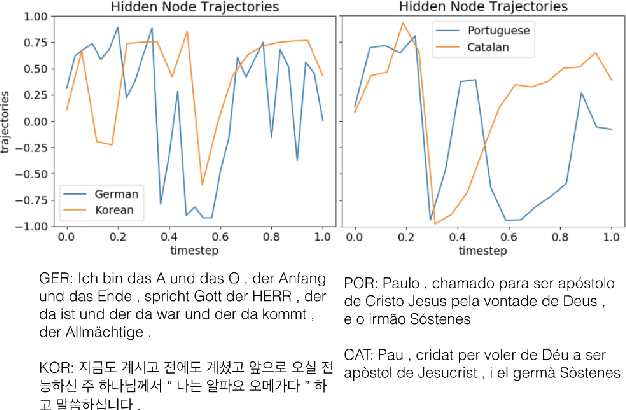
One central mystery of neural NLP is what neural models "know" about their subject matter. When a neural machine translation system learns to translate from one language to another, does it learn the syntax or semantics of the languages? Can this knowledge be extracted from the system to fill holes in human scientific knowledge? Existing typological databases contain relatively full feature specifications for only a few hundred languages. Exploiting the existence of parallel texts in more than a thousand languages, we build a massive many-to-one neural machine translation (NMT) system from 1017 languages into English, and use this to predict information missing from typological databases. Experiments show that the proposed method is able to infer not only syntactic, but also phonological and phonetic inventory features, and improves over a baseline that has access to information about the languages' geographic and phylogenetic neighbors.
Polyglot Neural Language Models: A Case Study in Cross-Lingual Phonetic Representation Learning
May 12, 2016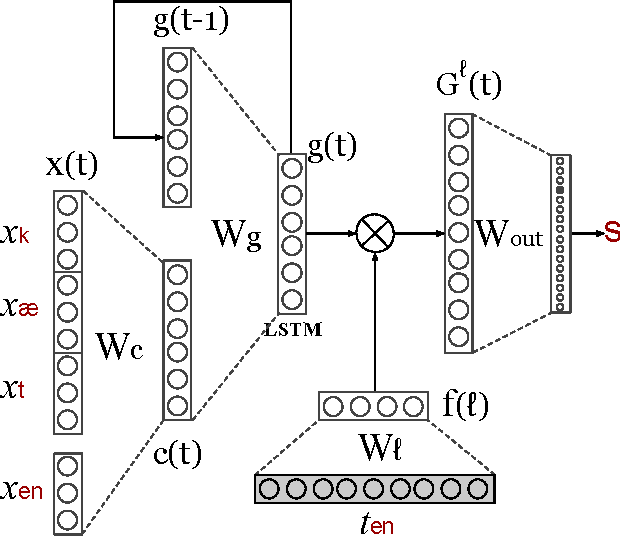



We introduce polyglot language models, recurrent neural network models trained to predict symbol sequences in many different languages using shared representations of symbols and conditioning on typological information about the language to be predicted. We apply these to the problem of modeling phone sequences---a domain in which universal symbol inventories and cross-linguistically shared feature representations are a natural fit. Intrinsic evaluation on held-out perplexity, qualitative analysis of the learned representations, and extrinsic evaluation in two downstream applications that make use of phonetic features show (i) that polyglot models better generalize to held-out data than comparable monolingual models and (ii) that polyglot phonetic feature representations are of higher quality than those learned monolingually.