 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Digital Corpus of St. Lawrence Island Yupik
Jan 26, 2021

St. Lawrence Island Yupik (ISO 639-3: ess) is an endangered polysynthetic language in the Inuit-Yupik language family indigenous to Alaska and Chukotka. This work presents a step-by-step pipeline for the digitization of written texts, and the first publicly available digital corpus for St. Lawrence Island Yupik, created using that pipeline. This corpus has great potential for future linguistic inquiry and research in NLP. It was also developed for use in Yupik language education and revitalization, with a primary goal of enabling easy access to Yupik texts by educators and by members of the Yupik community. A secondary goal is to support development of language technology such as spell-checkers, text-completion systems, interactive e-books, and language learning apps for use by the Yupik community.
Morphology Matters: A Multilingual Language Modeling Analysis
Dec 11, 2020
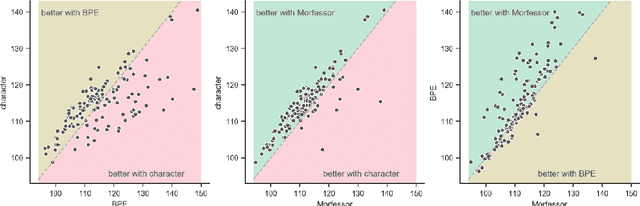
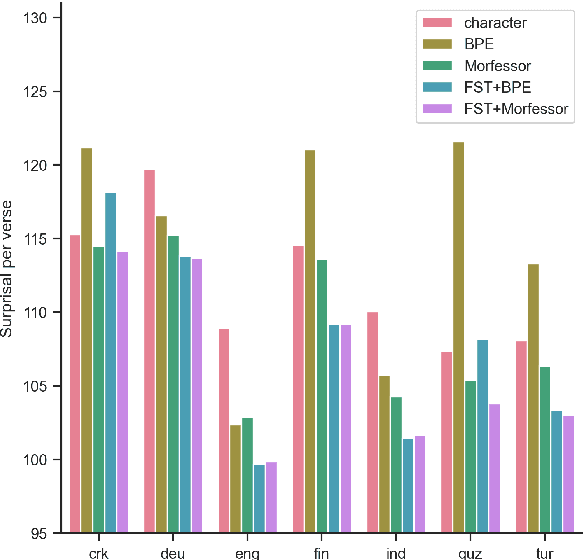
Prior studies in multilingual language modeling (e.g., Cotterell et al., 2018; Mielke et al., 2019) disagree on whether or not inflectional morphology makes languages harder to model. We attempt to resolve the disagreement and extend those studies. We compile a larger corpus of 145 Bible translations in 92 languages and a larger number of typological features. We fill in missing typological data for several languages and consider corpus-based measures of morphological complexity in addition to expert-produced typological features. We find that several morphological measures are significantly associated with higher surprisal when LSTM models are trained with BPE-segmented data. We also investigate linguistically-motivated subword segmentation strategies like Morfessor and Finite-State Transducers (FSTs) and find that these segmentation strategies yield better performance and reduce the impact of a language's morphology on language modeling.
Neural Polysynthetic Language Modelling
May 13, 2020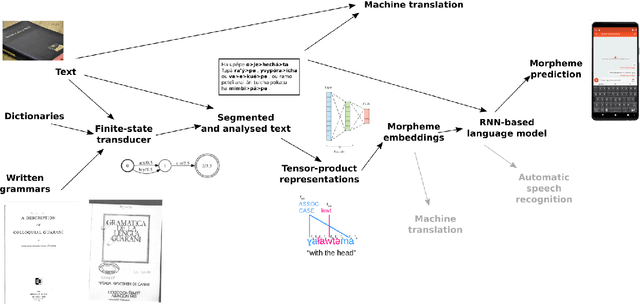

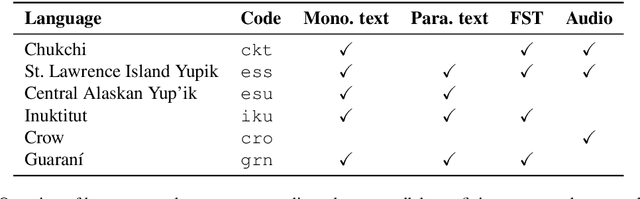
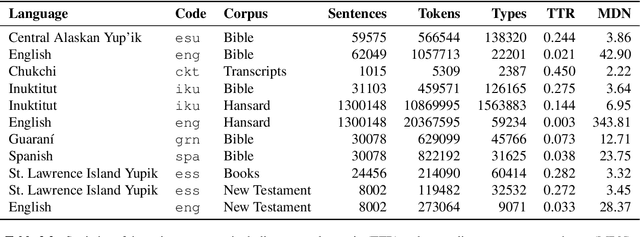
Research in natural language processing commonly assumes that approaches that work well for English and and other widely-used languages are "language agnostic". In high-resource languages, especially those that are analytic, a common approach is to treat morphologically-distinct variants of a common root as completely independent word types. This assumes, that there are limited morphological inflections per root, and that the majority will appear in a large enough corpus, so that the model can adequately learn statistics about each form. Approaches like stemming, lemmatization, or subword segmentation are often used when either of those assumptions do not hold, particularly in the case of synthetic languages like Spanish or Russian that have more inflection than English. In the literature, languages like Finnish or Turkish are held up as extreme examples of complexity that challenge common modelling assumptions. Yet, when considering all of the world's languages, Finnish and Turkish are closer to the average case. When we consider polysynthetic languages (those at the extreme of morphological complexity), approaches like stemming, lemmatization, or subword modelling may not suffice. These languages have very high numbers of hapax legomena, showing the need for appropriate morphological handling of words, without which it is not possible for a model to capture enough word statistics. We examine the current state-of-the-art in language modelling, machine translation, and text prediction for four polysynthetic languages: Guaran\'i, St. Lawrence Island Yupik, Central Alaskan Yupik, and Inuktitut. We then propose a novel framework for language modelling that combines knowledge representations from finite-state morphological analyzers with Tensor Product Representations in order to enable neural language models capable of handling the full range of typologically variant languages.
Depth-bounding is effective: Improvements and evaluation of unsupervised PCFG induction
Sep 10, 2018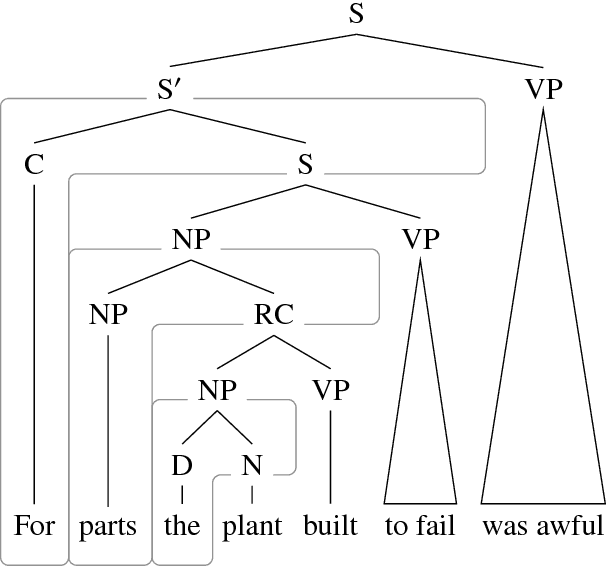
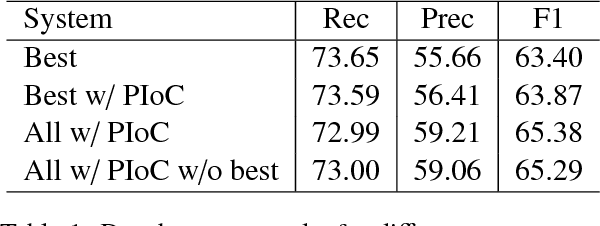
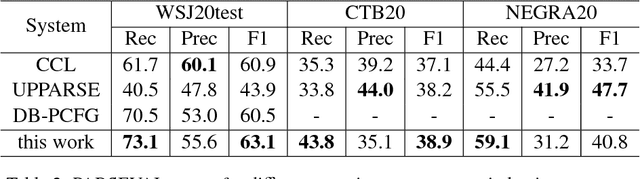
There have been several recent attempts to improve the accuracy of grammar induction systems by bounding the recursive complexity of the induction model (Ponvert et al., 2011; Noji and Johnson, 2016; Shain et al., 2016; Jin et al., 2018). Modern depth-bounded grammar inducers have been shown to be more accurate than early unbounded PCFG inducers, but this technique has never been compared against unbounded induction within the same system, in part because most previous depth-bounding models are built around sequence models, the complexity of which grows exponentially with the maximum allowed depth. The present work instead applies depth bounds within a chart-based Bayesian PCFG inducer (Johnson et al., 2007b), where bounding can be switched on and off, and then samples trees with and without bounding. Results show that depth-bounding is indeed significantly effective in limiting the search space of the inducer and thereby increasing the accuracy of the resulting parsing model. Moreover, parsing results on English, Chinese and German show that this bounded model with a new inference technique is able to produce parse trees more accurately than or competitively with state-of-the-art constituency-based grammar induction models.
Unsupervised Grammar Induction with Depth-bounded PCFG
Feb 26, 2018There has been recent interest in applying cognitively or empirically motivated bounds on recursion depth to limit the search space of grammar induction models (Ponvert et al., 2011; Noji and Johnson, 2016; Shain et al., 2016). This work extends this depth-bounding approach to probabilistic context-free grammar induction (DB-PCFG), which has a smaller parameter space than hierarchical sequence models, and therefore more fully exploits the space reductions of depth-bounding. Results for this model on grammar acquisition from transcribed child-directed speech and newswire text exceed or are competitive with those of other models when evaluated on parse accuracy. Moreover, gram- mars acquired from this model demonstrate a consistent use of category labels, something which has not been demonstrated by other acquisition models.
DLVM: A modern compiler infrastructure for deep learning systems
Feb 02, 2018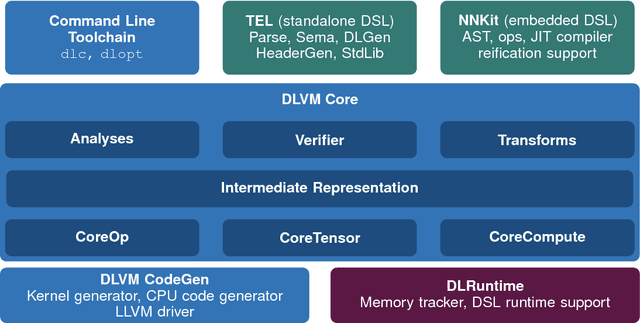



Deep learning software demands reliability and performance. However, many of the existing deep learning frameworks are software libraries that act as an unsafe DSL in Python and a computation graph interpreter. We present DLVM, a design and implementation of a compiler infrastructure with a linear algebra intermediate representation, algorithmic differentiation by adjoint code generation, domain-specific optimizations and a code generator targeting GPU via LLVM. Designed as a modern compiler infrastructure inspired by LLVM, DLVM is more modular and more generic than existing deep learning compiler frameworks, and supports tensor DSLs with high expressivity. With our prototypical staged DSL embedded in Swift, we argue that the DLVM system enables a form of modular, safe and performant frameworks for deep learning.
Fast, Scalable Phrase-Based SMT Decoding
Oct 18, 2016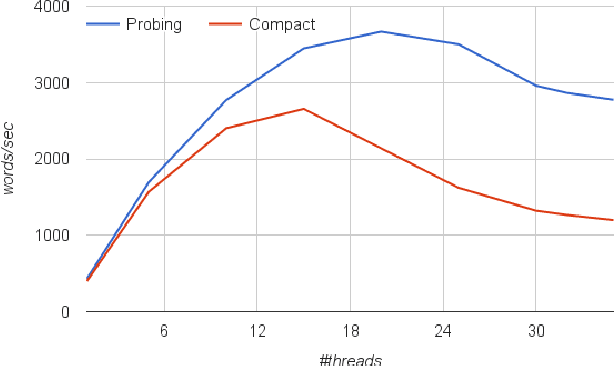

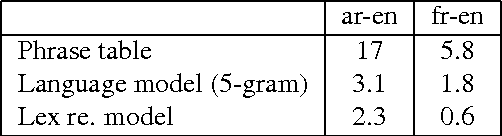
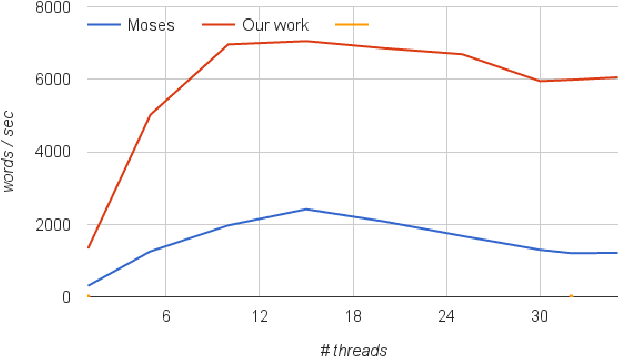
The utilization of statistical machine translation (SMT) has grown enormously over the last decade, many using open-source software developed by the NLP community. As commercial use has increased, there is need for software that is optimized for commercial requirements, in particular, fast phrase-based decoding and more efficient utilization of modern multicore servers. In this paper we re-examine the major components of phrase-based decoding and decoder implementation with particular emphasis on speed and scalability on multicore machines. The result is a drop-in replacement for the Moses decoder which is up to fifteen times faster and scales monotonically with the number of cores.