 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Well Does First-Token Entropy Approximate Word Entropy as a Psycholinguistic Predictor?
Jul 29, 2025Contextual entropy is a psycholinguistic measure capturing the anticipated difficulty of processing a word just before it is encountered. Recent studies have tested for entropy-related effects as a potential complement to well-known effects from surprisal. For convenience, entropy is typically estimated based on a language model's probability distribution over a word's first subword token. However, this approximation results in underestimation and potential distortion of true word entropy. To address this, we generate Monte Carlo (MC) estimates of word entropy that allow words to span a variable number of tokens. Regression experiments on reading times show divergent results between first-token and MC word entropy, suggesting a need for caution in using first-token approximations of contextual entropy.
Surprisal from Larger Transformer-based Language Models Predicts fMRI Data More Poorly
Jun 12, 2025As Transformers become more widely incorporated into natural language processing tasks, there has been considerable interest in using surprisal from these models as predictors of human sentence processing difficulty. Recent work has observed a positive relationship between Transformer-based models' perplexity and the predictive power of their surprisal estimates on reading times, showing that language models with more parameters and trained on more data are less predictive of human reading times. However, these studies focus on predicting latency-based measures (i.e., self-paced reading times and eye-gaze durations) with surprisal estimates from Transformer-based language models. This trend has not been tested on brain imaging data. This study therefore evaluates the predictive power of surprisal estimates from 17 pre-trained Transformer-based models across three different language families on two functional magnetic resonance imaging datasets. Results show that the positive relationship between model perplexity and model fit still obtains, suggesting that this trend is not specific to latency-based measures and can be generalized to neural measures.
Vectors from Larger Language Models Predict Human Reading Time and fMRI Data More Poorly when Dimensionality Expansion is Controlled
May 18, 2025The impressive linguistic abilities of large language models (LLMs) have recommended them as models of human sentence processing, with some conjecturing a positive 'quality-power' relationship (Wilcox et al., 2023), in which language models' (LMs') fit to psychometric data continues to improve as their ability to predict words in context increases. This is important because it suggests that elements of LLM architecture, such as veridical attention to context and a unique objective of predicting upcoming words, reflect the architecture of the human sentence processing faculty, and that any inadequacies in predicting human reading time and brain imaging data may be attributed to insufficient model complexity, which recedes as larger models become available. Recent studies (Oh and Schuler, 2023) have shown this scaling inverts after a point, as LMs become excessively large and accurate, when word prediction probability (as information-theoretic surprisal) is used as a predictor. Other studies propose the use of entire vectors from differently sized LLMs, still showing positive scaling (Schrimpf et al., 2021), casting doubt on the value of surprisal as a predictor, but do not control for the larger number of predictors in vectors from larger LMs. This study evaluates LLM scaling using entire LLM vectors, while controlling for the larger number of predictors in vectors from larger LLMs. Results show that inverse scaling obtains, suggesting that inadequacies in predicting human reading time and brain imaging data may be due to substantial misalignment between LLMs and human sentence processing, which worsens as larger models are used.
The Impact of Token Granularity on the Predictive Power of Language Model Surprisal
Dec 16, 2024



Word-by-word language model surprisal is often used to model the incremental processing of human readers, which raises questions about how various choices in language modeling influence its predictive power. One factor that has been overlooked in cognitive modeling is the granularity of subword tokens, which explicitly encodes information about word length and frequency, and ultimately influences the quality of vector representations that are learned. This paper presents experiments that manipulate the token granularity and evaluate its impact on the ability of surprisal to account for processing difficulty of naturalistic text and garden-path constructions. Experiments with naturalistic reading times reveal a substantial influence of token granularity on surprisal, with tokens defined by a vocabulary size of 8,000 resulting in surprisal that is most predictive. In contrast, on garden-path constructions, language models trained on coarser-grained tokens generally assigned higher surprisal to critical regions, suggesting their increased sensitivity to syntax. Taken together, these results suggest a large role of token granularity on the quality of language model surprisal for cognitive modeling.
Linear Recency Bias During Training Improves Transformers' Fit to Reading Times
Sep 17, 2024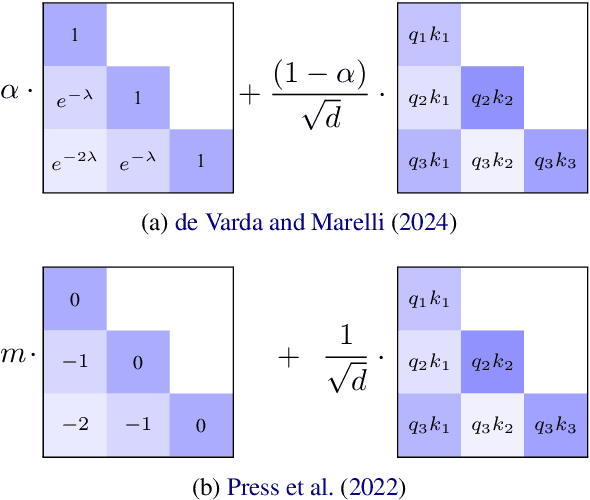


Recent psycholinguistic research has compared human reading times to surprisal estimates from language models to study the factors shaping human sentence processing difficulty. Previous studies have shown a strong fit between surprisal values from Transformers and reading times. However, standard Transformers work with a lossless representation of the entire previous linguistic context, unlike models of human language processing that include memory decay. To bridge this gap, this paper evaluates a modification of the Transformer model that uses ALiBi (Press et al., 2022), a recency bias added to attention scores. Surprisal estimates with ALiBi show an improved fit to human reading times compared to a standard Transformer baseline. A subsequent analysis of attention heads suggests that ALiBi's mixture of slopes -- which determine the rate of memory decay in each attention head -- may play a role in the improvement by helping models with ALiBi to track different kinds of linguistic dependencies.
Leading Whitespaces of Language Models' Subword Vocabulary Poses a Confound for Calculating Word Probabilities
Jun 16, 2024Word-by-word conditional probabilities from Transformer-based language models are increasingly being used to evaluate their predictions over minimal pairs or to model the incremental processing difficulty of human readers. In this paper, we argue that there is a confound posed by the subword tokenization scheme of such language models, which has gone unaddressed thus far. This is due to the fact that tokens in the subword vocabulary of most language models have leading whitespaces and therefore do not naturally define stop probabilities of words. We first prove that this can result in word probabilities that sum to more than one, thereby violating the axiom that $\mathsf{P}(\Omega) = 1$. This property results in a misallocation of word-by-word surprisal, where the unacceptability of the current 'end of word' is incorrectly carried over to the next word. Additionally, language models' such implicit prediction of word boundaries is incongruous with psycholinguistic experiments where human subjects directly observe upcoming word boundaries. We present a simple decoding technique to reaccount the probability of the trailing whitespace into that of the current word, which resolves this confound. As a case study, we show that this results in significantly different estimates of garden-path effects in transitive/intransitive sentences, where a comma is strongly expected before the critical word.
Frequency Explains the Inverse Correlation of Large Language Models' Size, Training Data Amount, and Surprisal's Fit to Reading Times
Feb 03, 2024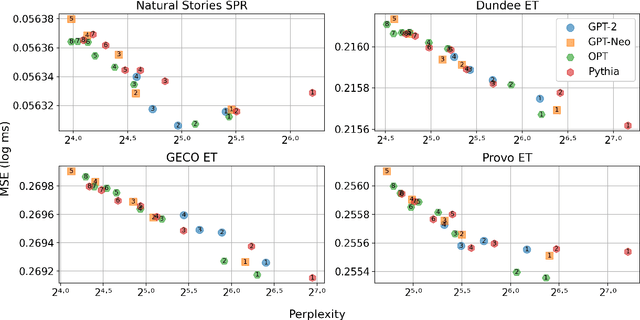

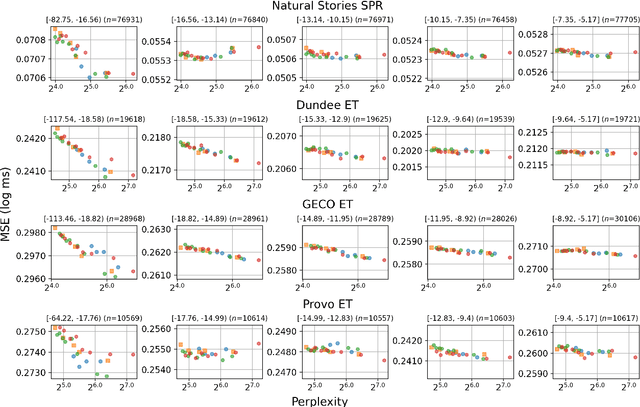
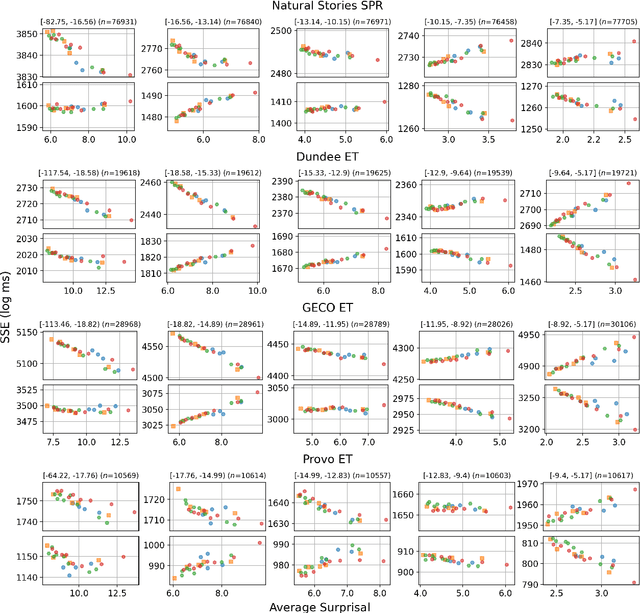
Recent studies have shown that as Transformer-based language models become larger and are trained on very large amounts of data, the fit of their surprisal estimates to naturalistic human reading times degrades. The current work presents a series of analyses showing that word frequency is a key explanatory factor underlying these two trends. First, residual errors from four language model families on four corpora show that the inverse correlation between model size and fit to reading times is the strongest on the subset of least frequent words, which is driven by excessively accurate predictions of larger model variants. Additionally, training dynamics reveal that during later training steps, all model variants learn to predict rare words and that larger model variants do so more accurately, which explains the detrimental effect of both training data amount and model size on fit to reading times. Finally, a feature attribution analysis demonstrates that larger model variants are able to accurately predict rare words based on both an effectively longer context window size as well as stronger local associations compared to smaller model variants. Taken together, these results indicate that Transformer-based language models' surprisal estimates diverge from human-like expectations due to the superhumanly complex associations they learn for predicting rare words.
Token-wise Decomposition of Autoregressive Language Model Hidden States for Analyzing Model Predictions
May 17, 2023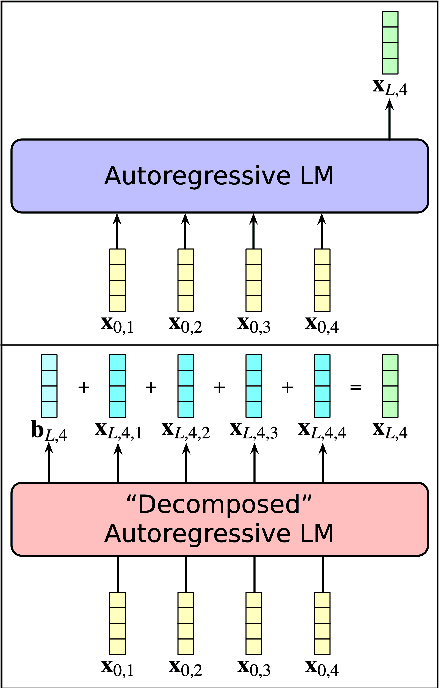

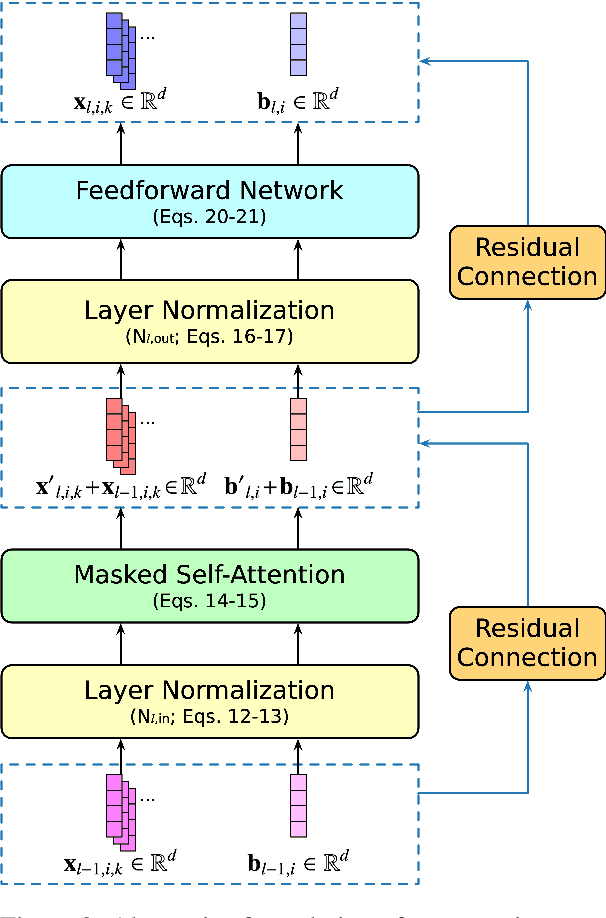

While there is much recent interest in studying why Transformer-based large language models make predictions the way they do, the complex computations performed within each layer have traditionally posed a strong bottleneck. To mitigate this shortcoming, this work presents a linear decomposition of final hidden states from autoregressive language models based on each initial input token, which is exact for virtually all contemporary Transformer architectures. This decomposition allows the definition of probability distributions that ablate the contribution of specific input tokens, which can be used to analyze their influence on model probabilities over a sequence of upcoming words with only one forward pass from the model. Using the change in next-word probability as a measure of importance, this work first examines which context words make the biggest contribution to language model predictions. Regression experiments suggest that Transformer-based language models rely primarily on collocational associations, followed by linguistic factors such as syntactic dependencies and coreference relationships in making next-word predictions. Additionally, analyses using these measures to predict syntactic dependencies and coreferent mention spans show that collocational association and repetitions of the same token respectively, largely explain the language model's predictions on the tasks.
Transformer-Based LM Surprisal Predicts Human Reading Times Best with About Two Billion Training Tokens
Apr 22, 2023Recent psycholinguistic studies have drawn conflicting conclusions about the relationship between the quality of a language model and the ability of its surprisal estimates to predict human reading times, which has been speculated to be due to the large gap in both the amount of training data and model capacity across studies. The current work aims to consolidate these findings by evaluating surprisal estimates from Transformer-based language model variants that vary systematically in the amount of training data and model capacity on their ability to predict human reading times. The results show that surprisal estimates from most variants with contemporary model capacities provide the best fit after seeing about two billion training tokens, after which they begin to diverge from humanlike expectations. Additionally, newly-trained smaller model variants reveal a 'tipping point' at convergence, after which the decrease in language model perplexity begins to result in poorer fits to human reading times. These results suggest that the massive amount of training data is mainly responsible for the poorer fit achieved by surprisal from larger pre-trained language models, and that a certain degree of model capacity is necessary for Transformer-based language models to capture humanlike expectations.
Why Does Surprisal From Larger Transformer-Based Language Models Provide a Poorer Fit to Human Reading Times?
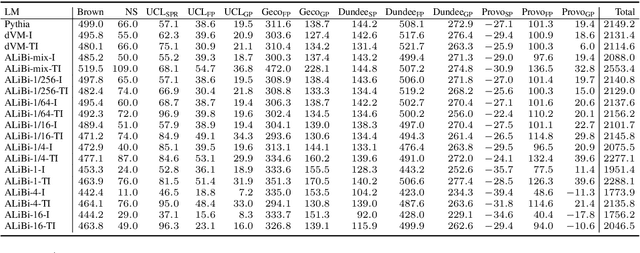
Dec 23, 2022This work presents a detailed linguistic analysis into why larger Transformer-based pre-trained language models with more parameters and lower perplexity nonetheless yield surprisal estimates that are less predictive of human reading times. First, regression analyses show a strictly monotonic, positive log-linear relationship between perplexity and fit to reading times for the more recently released five GPT-Neo variants and eight OPT variants on two separate datasets, replicating earlier results limited to just GPT-2 (Oh et al., 2022). Subsequently, analysis of residual errors reveals a systematic deviation of the larger variants, such as underpredicting reading times of named entities and making compensatory overpredictions for reading times of function words such as modals and conjunctions. These results suggest that the propensity of larger Transformer-based models to 'memorize' sequences during training makes their surprisal estimates diverge from humanlike expectations, which warrants caution in using pre-trained language models to study human language processing.