 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinear Recency Bias During Training Improves Transformers' Fit to Reading Times
Paper and Code
Sep 17, 2024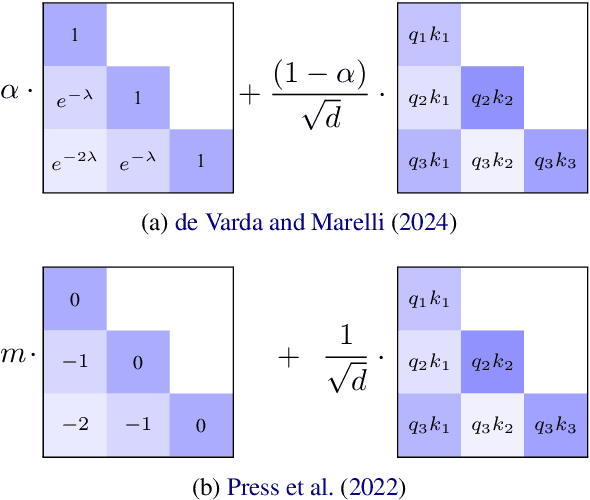


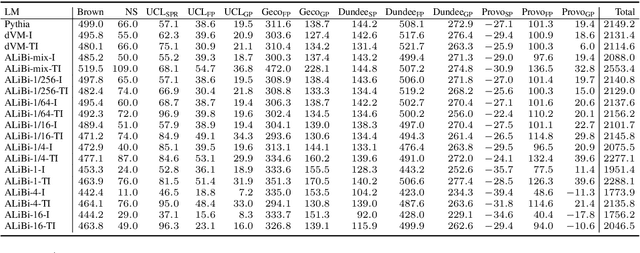
Recent psycholinguistic research has compared human reading times to surprisal estimates from language models to study the factors shaping human sentence processing difficulty. Previous studies have shown a strong fit between surprisal values from Transformers and reading times. However, standard Transformers work with a lossless representation of the entire previous linguistic context, unlike models of human language processing that include memory decay. To bridge this gap, this paper evaluates a modification of the Transformer model that uses ALiBi (Press et al., 2022), a recency bias added to attention scores. Surprisal estimates with ALiBi show an improved fit to human reading times compared to a standard Transformer baseline. A subsequent analysis of attention heads suggests that ALiBi's mixture of slopes -- which determine the rate of memory decay in each attention head -- may play a role in the improvement by helping models with ALiBi to track different kinds of linguistic dependencies.