 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Large Language Models Understand Conversational Implicature -- A case study with a chinese sitcom
Apr 30, 2024Understanding the non-literal meaning of an utterance is critical for large language models (LLMs) to become human-like social communicators. In this work, we introduce SwordsmanImp, the first Chinese multi-turn-dialogue-based dataset aimed at conversational implicature, sourced from dialogues in the Chinese sitcom $\textit{My Own Swordsman}$. It includes 200 carefully handcrafted questions, all annotated on which Gricean maxims have been violated. We test eight close-source and open-source LLMs under two tasks: a multiple-choice question task and an implicature explanation task. Our results show that GPT-4 attains human-level accuracy (94%) on multiple-choice questions. CausalLM demonstrates a 78.5% accuracy following GPT-4. Other models, including GPT-3.5 and several open-source models, demonstrate a lower accuracy ranging from 20% to 60% on multiple-choice questions. Human raters were asked to rate the explanation of the implicatures generated by LLMs on their reasonability, logic and fluency. While all models generate largely fluent and self-consistent text, their explanations score low on reasonability except for GPT-4, suggesting that most LLMs cannot produce satisfactory explanations of the implicatures in the conversation. Moreover, we find LLMs' performance does not vary significantly by Gricean maxims, suggesting that LLMs do not seem to process implicatures derived from different maxims differently. Our data and code are available at https://github.com/sjtu-compling/llm-pragmatics.
Frequency Explains the Inverse Correlation of Large Language Models' Size, Training Data Amount, and Surprisal's Fit to Reading Times
Feb 03, 2024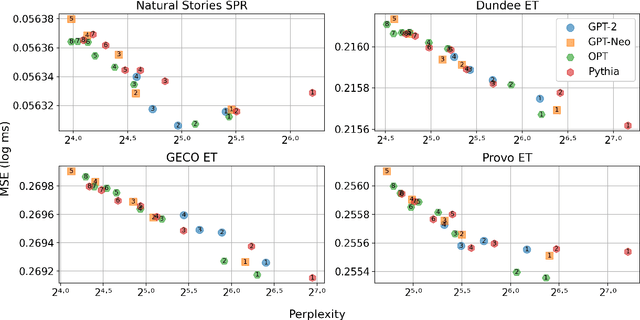

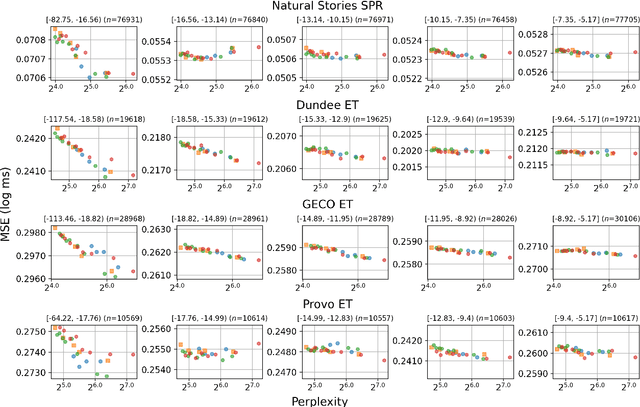
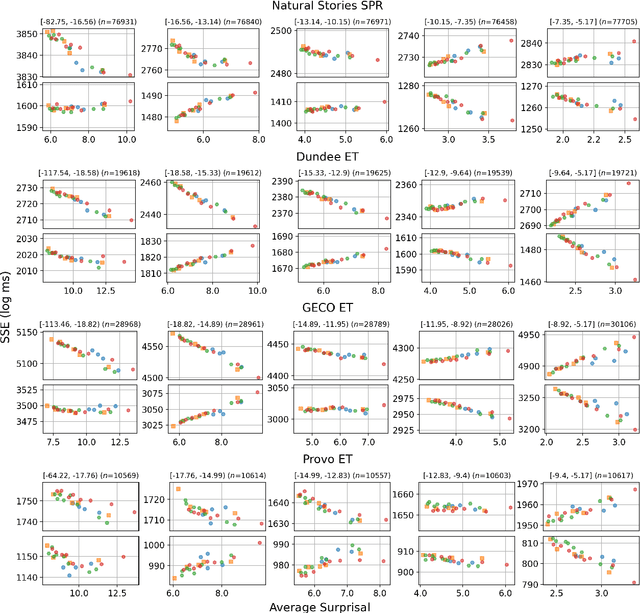
Recent studies have shown that as Transformer-based language models become larger and are trained on very large amounts of data, the fit of their surprisal estimates to naturalistic human reading times degrades. The current work presents a series of analyses showing that word frequency is a key explanatory factor underlying these two trends. First, residual errors from four language model families on four corpora show that the inverse correlation between model size and fit to reading times is the strongest on the subset of least frequent words, which is driven by excessively accurate predictions of larger model variants. Additionally, training dynamics reveal that during later training steps, all model variants learn to predict rare words and that larger model variants do so more accurately, which explains the detrimental effect of both training data amount and model size on fit to reading times. Finally, a feature attribution analysis demonstrates that larger model variants are able to accurately predict rare words based on both an effectively longer context window size as well as stronger local associations compared to smaller model variants. Taken together, these results indicate that Transformer-based language models' surprisal estimates diverge from human-like expectations due to the superhumanly complex associations they learn for predicting rare words.
ArguGPT: evaluating, understanding and identifying argumentative essays generated by GPT models
Apr 16, 2023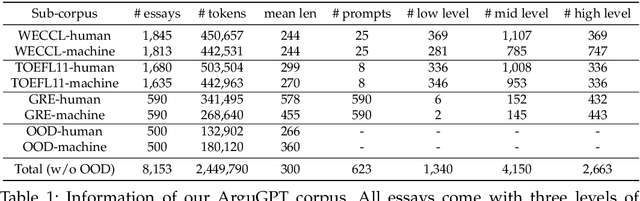
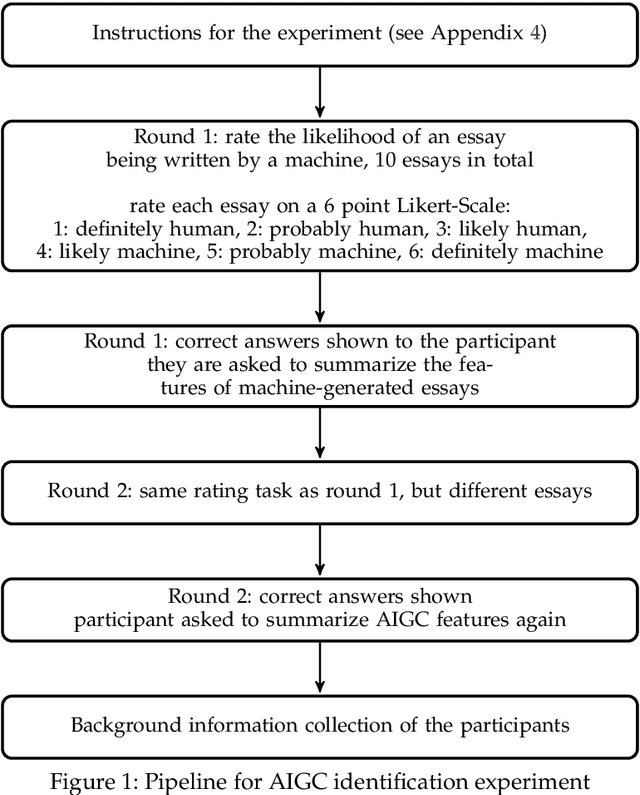

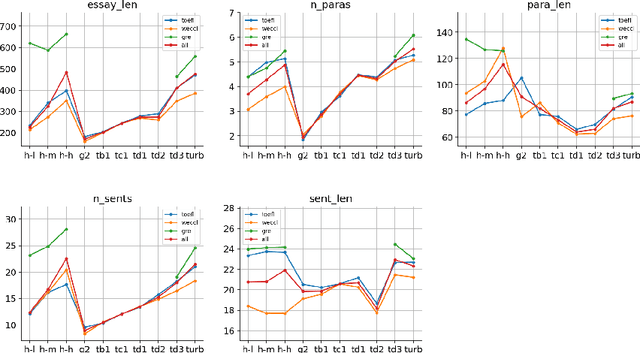
AI generated content (AIGC) presents considerable challenge to educators around the world. Instructors need to be able to detect such text generated by large language models, either with the naked eye or with the help of some tools. There is also growing need to understand the lexical, syntactic and stylistic features of AIGC. To address these challenges in English language teaching, we first present ArguGPT, a balanced corpus of 4,038 argumentative essays generated by 7 GPT models in response to essay prompts from three sources: (1) in-class or homework exercises, (2) TOEFL and (3) GRE writing tasks. Machine-generated texts are paired with roughly equal number of human-written essays with three score levels matched in essay prompts. We then hire English instructors to distinguish machine essays from human ones. Results show that when first exposed to machine-generated essays, the instructors only have an accuracy of 61% in detecting them. But the number rises to 67% after one round of minimal self-training. Next, we perform linguistic analyses of these essays, which show that machines produce sentences with more complex syntactic structures while human essays tend to be lexically more complex. Finally, we test existing AIGC detectors and build our own detectors using SVMs and RoBERTa. Results suggest that a RoBERTa fine-tuned with the training set of ArguGPT achieves above 90% accuracy in both essay- and sentence-level classification. To the best of our knowledge, this is the first comprehensive analysis of argumentative essays produced by generative large language models. Machine-authored essays in ArguGPT and our models will be made publicly available at https://github.com/huhailinguist/ArguGPT