 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAU: Reference-based Anatomical Understanding with Vision Language Models
Sep 26, 2025Anatomical understanding through deep learning is critical for automatic report generation, intra-operative navigation, and organ localization in medical imaging; however, its progress is constrained by the scarcity of expert-labeled data. A promising remedy is to leverage an annotated reference image to guide the interpretation of an unlabeled target. Although recent vision-language models (VLMs) exhibit non-trivial visual reasoning, their reference-based understanding and fine-grained localization remain limited. We introduce RAU, a framework for reference-based anatomical understanding with VLMs. We first show that a VLM learns to identify anatomical regions through relative spatial reasoning between reference and target images, trained on a moderately sized dataset. We validate this capability through visual question answering (VQA) and bounding box prediction. Next, we demonstrate that the VLM-derived spatial cues can be seamlessly integrated with the fine-grained segmentation capability of SAM2, enabling localization and pixel-level segmentation of small anatomical regions, such as vessel segments. Across two in-distribution and two out-of-distribution datasets, RAU consistently outperforms a SAM2 fine-tuning baseline using the same memory setup, yielding more accurate segmentations and more reliable localization. More importantly, its strong generalization ability makes it scalable to out-of-distribution datasets, a property crucial for medical image applications. To the best of our knowledge, RAU is the first to explore the capability of VLMs for reference-based identification, localization, and segmentation of anatomical structures in medical images. Its promising performance highlights the potential of VLM-driven approaches for anatomical understanding in automated clinical workflows.
Translationese-index: Using Likelihood Ratios for Graded and Generalizable Measurement of Translationese
Jul 16, 2025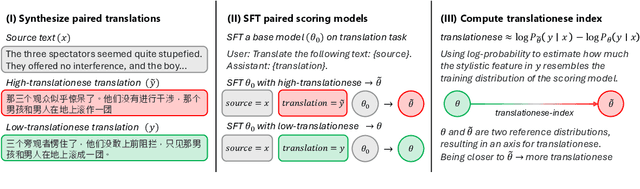
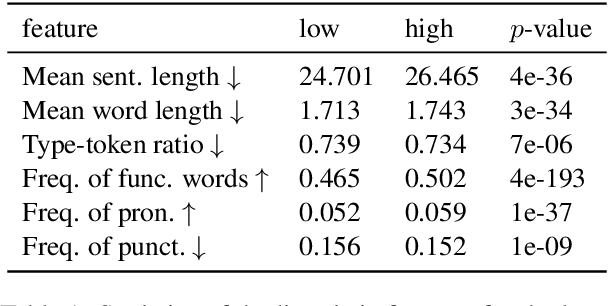
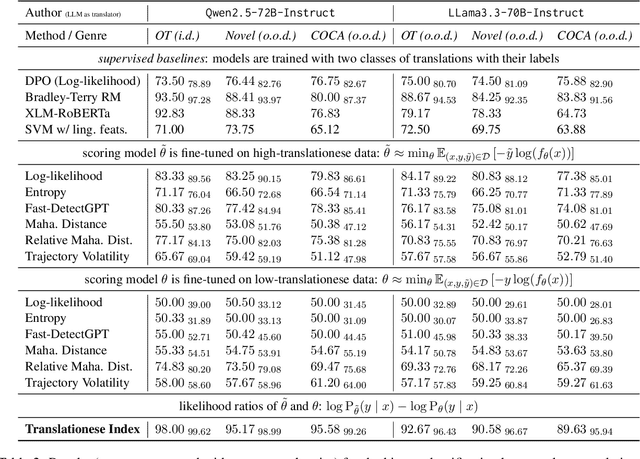
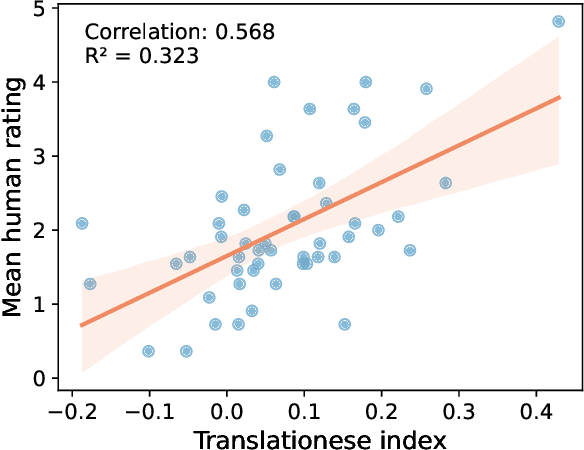
In this paper, we propose the first quantitative measure for translationese -- the translationese-index (T-index) for graded and generalizable measurement of translationese, computed from the likelihood ratios of two contrastively fine-tuned language models (LMs). We use a synthesized dataset and a dataset with translations in the wild to evaluate T-index's generalizability in cross-domain settings and its validity against human judgments. Our results show that T-index is both robust and efficient. T-index scored by two 0.5B LMs fine-tuned on only 1-5k pairs of synthetic data can well capture translationese in the wild. We find that the relative differences in T-indices between translations can well predict pairwise translationese annotations obtained from human annotators; and the absolute values of T-indices correlate well with human ratings of degrees of translationese (Pearson's $r = 0.568$). Additionally, the correlation between T-index and existing machine translation (MT) quality estimation (QE) metrics such as BLEU and COMET is low, suggesting that T-index is not covered by these metrics and can serve as a complementary metric in MT QE.
Leveraging Diffusion Model and Image Foundation Model for Improved Correspondence Matching in Coronary Angiography
Mar 31, 2025Accurate correspondence matching in coronary angiography images is crucial for reconstructing 3D coronary artery structures, which is essential for precise diagnosis and treatment planning of coronary artery disease (CAD). Traditional matching methods for natural images often fail to generalize to X-ray images due to inherent differences such as lack of texture, lower contrast, and overlapping structures, compounded by insufficient training data. To address these challenges, we propose a novel pipeline that generates realistic paired coronary angiography images using a diffusion model conditioned on 2D projections of 3D reconstructed meshes from Coronary Computed Tomography Angiography (CCTA), providing high-quality synthetic data for training. Additionally, we employ large-scale image foundation models to guide feature aggregation, enhancing correspondence matching accuracy by focusing on semantically relevant regions and keypoints. Our approach demonstrates superior matching performance on synthetic datasets and effectively generalizes to real-world datasets, offering a practical solution for this task. Furthermore, our work investigates the efficacy of different foundation models in correspondence matching, providing novel insights into leveraging advanced image foundation models for medical imaging applications.
Adapting Vision Foundation Models for Real-time Ultrasound Image Segmentation
Mar 31, 2025We propose a novel approach that adapts hierarchical vision foundation models for real-time ultrasound image segmentation. Existing ultrasound segmentation methods often struggle with adaptability to new tasks, relying on costly manual annotations, while real-time approaches generally fail to match state-of-the-art performance. To overcome these limitations, we introduce an adaptive framework that leverages the vision foundation model Hiera to extract multi-scale features, interleaved with DINOv2 representations to enhance visual expressiveness. These enriched features are then decoded to produce precise and robust segmentation. We conduct extensive evaluations on six public datasets and one in-house dataset, covering both cardiac and thyroid ultrasound segmentation. Experiments show that our approach outperforms state-of-the-art methods across multiple datasets and excels with limited supervision, surpassing nnUNet by over 20\% on average in the 1\% and 10\% data settings. Our method achieves $\sim$77 FPS inference speed with TensorRT on a single GPU, enabling real-time clinical applications.
DiffDenoise: Self-Supervised Medical Image Denoising with Conditional Diffusion Models
Mar 31, 2025Many self-supervised denoising approaches have been proposed in recent years. However, these methods tend to overly smooth images, resulting in the loss of fine structures that are essential for medical applications. In this paper, we propose DiffDenoise, a powerful self-supervised denoising approach tailored for medical images, designed to preserve high-frequency details. Our approach comprises three stages. First, we train a diffusion model on noisy images, using the outputs of a pretrained Blind-Spot Network as conditioning inputs. Next, we introduce a novel stabilized reverse sampling technique, which generates clean images by averaging diffusion sampling outputs initialized with a pair of symmetric noises. Finally, we train a supervised denoising network using noisy images paired with the denoised outputs generated by the diffusion model. Our results demonstrate that DiffDenoise outperforms existing state-of-the-art methods in both synthetic and real-world medical image denoising tasks. We provide both a theoretical foundation and practical insights, demonstrating the method's effectiveness across various medical imaging modalities and anatomical structures.
Label-Efficient Data Augmentation with Video Diffusion Models for Guidewire Segmentation in Cardiac Fluoroscopy
Dec 23, 2024The accurate segmentation of guidewires in interventional cardiac fluoroscopy videos is crucial for computer-aided navigation tasks. Although deep learning methods have demonstrated high accuracy and robustness in wire segmentation, they require substantial annotated datasets for generalizability, underscoring the need for extensive labeled data to enhance model performance. To address this challenge, we propose the Segmentation-guided Frame-consistency Video Diffusion Model (SF-VD) to generate large collections of labeled fluoroscopy videos, augmenting the training data for wire segmentation networks. SF-VD leverages videos with limited annotations by independently modeling scene distribution and motion distribution. It first samples the scene distribution by generating 2D fluoroscopy images with wires positioned according to a specified input mask, and then samples the motion distribution by progressively generating subsequent frames, ensuring frame-to-frame coherence through a frame-consistency strategy. A segmentation-guided mechanism further refines the process by adjusting wire contrast, ensuring a diverse range of visibility in the synthesized image. Evaluation on a fluoroscopy dataset confirms the superior quality of the generated videos and shows significant improvements in guidewire segmentation.
ZhoBLiMP: a Systematic Assessment of Language Models with Linguistic Minimal Pairs in Chinese
Nov 09, 2024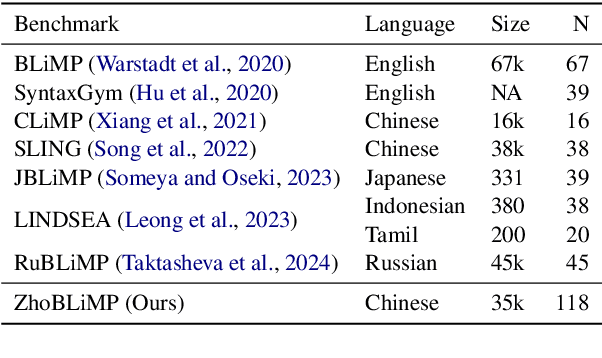

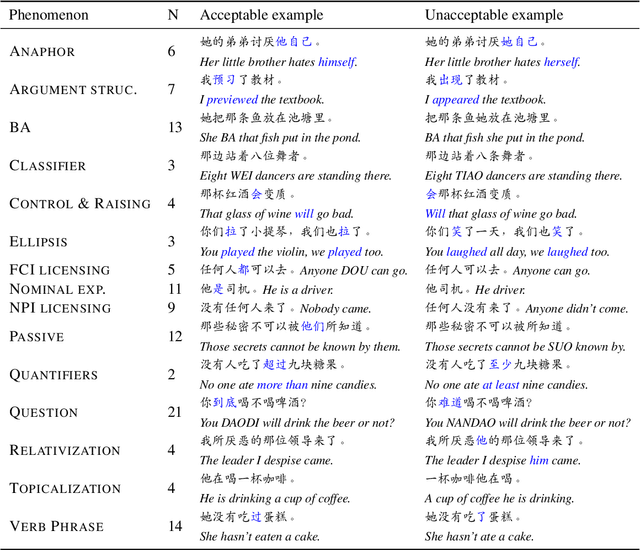
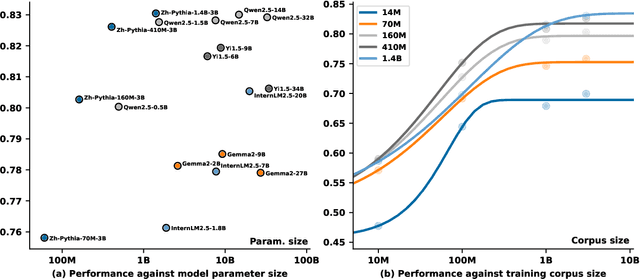
Whether and how language models (LMs) acquire the syntax of natural languages has been widely evaluated under the minimal pair paradigm. However, a lack of wide-coverage benchmarks in languages other than English has constrained systematic investigations into the issue. Addressing it, we first introduce ZhoBLiMP, the most comprehensive benchmark of linguistic minimal pairs for Chinese to date, with 118 paradigms, covering 15 linguistic phenomena. We then train 20 LMs of different sizes (14M to 1.4B) on Chinese corpora of various volumes (100M to 3B tokens) and evaluate them along with 14 off-the-shelf LLMs on ZhoBLiMP. The overall results indicate that Chinese grammar can be mostly learned by models with around 500M parameters, trained on 1B tokens with one epoch, showing limited benefits for further scaling. Most (N=95) linguistic paradigms are of easy or medium difficulty for LMs, while there are still 13 paradigms that remain challenging even for models with up to 32B parameters. In regard to how LMs acquire Chinese grammar, we observe a U-shaped learning pattern in several phenomena, similar to those observed in child language acquisition.
Auxiliary Input in Training: Incorporating Catheter Features into Deep Learning Models for ECG-Free Dynamic Coronary Roadmapping
Aug 28, 2024



Dynamic coronary roadmapping is a technology that overlays the vessel maps (the "roadmap") extracted from an offline image sequence of X-ray angiography onto a live stream of X-ray fluoroscopy in real-time. It aims to offer navigational guidance for interventional surgeries without the need for repeated contrast agent injections, thereby reducing the risks associated with radiation exposure and kidney failure. The precision of the roadmaps is contingent upon the accurate alignment of angiographic and fluoroscopic images based on their cardiac phases, as well as precise catheter tip tracking. The former ensures the selection of a roadmap that closely matches the vessel shape in the current frame, while the latter uses catheter tips as reference points to adjust for translational motion between the roadmap and the present vessel tree. Training deep learning models for both tasks is challenging and underexplored. However, incorporating catheter features into the models could offer substantial benefits, given humans heavily rely on catheters to complete the tasks. To this end, we introduce a simple but effective method, auxiliary input in training (AIT), and demonstrate that it enhances model performance across both tasks, outperforming baseline methods in knowledge incorporation and transfer learning.
Retrieval-augmented Few-shot Medical Image Segmentation with Foundation Models
Aug 16, 2024



Medical image segmentation is crucial for clinical decision-making, but the scarcity of annotated data presents significant challenges. Few-shot segmentation (FSS) methods show promise but often require retraining on the target domain and struggle to generalize across different modalities. Similarly, adapting foundation models like the Segment Anything Model (SAM) for medical imaging has limitations, including the need for finetuning and domain-specific adaptation. To address these issues, we propose a novel method that adapts DINOv2 and Segment Anything Model 2 (SAM 2) for retrieval-augmented few-shot medical image segmentation. Our approach uses DINOv2's feature as query to retrieve similar samples from limited annotated data, which are then encoded as memories and stored in memory bank. With the memory attention mechanism of SAM 2, the model leverages these memories as conditions to generate accurate segmentation of the target image. We evaluated our framework on three medical image segmentation tasks, demonstrating superior performance and generalizability across various modalities without the need for any retraining or finetuning. Overall, this method offers a practical and effective solution for few-shot medical image segmentation and holds significant potential as a valuable annotation tool in clinical applications.
Spatiotemporal Diffusion Model with Paired Sampling for Accelerated Cardiac Cine MRI
Mar 13, 2024Current deep learning reconstruction for accelerated cardiac cine MRI suffers from spatial and temporal blurring. We aim to improve image sharpness and motion delineation for cine MRI under high undersampling rates. A spatiotemporal diffusion enhancement model conditional on an existing deep learning reconstruction along with a novel paired sampling strategy was developed. The diffusion model provided sharper tissue boundaries and clearer motion than the original reconstruction in experts evaluation on clinical data. The innovative paired sampling strategy substantially reduced artificial noises in the generative results.