 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHealthiVert-GAN: A Novel Framework of Pseudo-Healthy Vertebral Image Synthesis for Interpretable Compression Fracture Grading
Mar 08, 2025Osteoporotic vertebral compression fractures (VCFs) are prevalent in the elderly population, typically assessed on computed tomography (CT) scans by evaluating vertebral height loss. This assessment helps determine the fracture's impact on spinal stability and the need for surgical intervention. However, clinical data indicate that many VCFs exhibit irregular compression, complicating accurate diagnosis. While deep learning methods have shown promise in aiding VCFs screening, they often lack interpretability and sufficient sensitivity, limiting their clinical applicability. To address these challenges, we introduce a novel vertebra synthesis-height loss quantification-VCFs grading framework. Our proposed model, HealthiVert-GAN, utilizes a coarse-to-fine synthesis network designed to generate pseudo-healthy vertebral images that simulate the pre-fracture state of fractured vertebrae. This model integrates three auxiliary modules that leverage the morphology and height information of adjacent healthy vertebrae to ensure anatomical consistency. Additionally, we introduce the Relative Height Loss of Vertebrae (RHLV) as a quantification metric, which divides each vertebra into three sections to measure height loss between pre-fracture and post-fracture states, followed by fracture severity classification using a Support Vector Machine (SVM). Our approach achieves state-of-the-art classification performance on both the Verse2019 dataset and our private dataset, and it provides cross-sectional distribution maps of vertebral height loss. This practical tool enhances diagnostic sensitivity in clinical settings and assisting in surgical decision-making. Our code is available: https://github.com/zhibaishouheilab/HealthiVert-GAN.
Federated Data Model
Mar 13, 2024In artificial intelligence (AI), especially deep learning, data diversity and volume play a pivotal role in model development. However, training a robust deep learning model often faces challenges due to data privacy, regulations, and the difficulty of sharing data between different locations, especially for medical applications. To address this, we developed a method called the Federated Data Model (FDM). This method uses diffusion models to learn the characteristics of data at one site and then creates synthetic data that can be used at another site without sharing the actual data. We tested this approach with a medical image segmentation task, focusing on cardiac magnetic resonance images from different hospitals. Our results show that models trained with this method perform well both on the data they were originally trained on and on data from other sites. This approach offers a promising way to train accurate and privacy-respecting AI models across different locations.
Towards Bursting Filter Bubble via Contextual Risks and Uncertainties
Jun 30, 2017
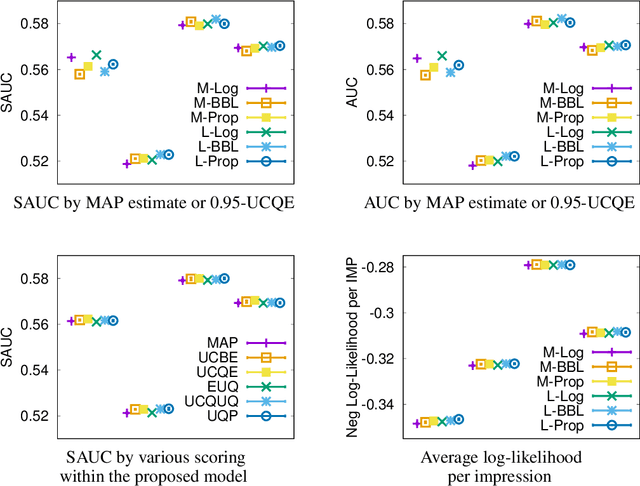
A rising topic in computational journalism is how to enhance the diversity in news served to subscribers to foster exploration behavior in news reading. Despite the success of preference learning in personalized news recommendation, their over-exploitation causes filter bubble that isolates readers from opposing viewpoints and hurts long-term user experiences with lack of serendipity. Since news providers can recommend neither opposite nor diversified opinions if unpopularity of these articles is surely predicted, they can only bet on the articles whose forecasts of click-through rate involve high variability (risks) or high estimation errors (uncertainties). We propose a novel Bayesian model of uncertainty-aware scoring and ranking for news articles. The Bayesian binary classifier models probability of success (defined as a news click) as a Beta-distributed random variable conditional on a vector of the context (user features, article features, and other contextual features). The posterior of the contextual coefficients can be computed efficiently using a low-rank version of Laplace's method via thin Singular Value Decomposition. Efficiencies in personalized targeting of exceptional articles, which are chosen by each subscriber in test period, are evaluated on real-world news datasets. The proposed estimator slightly outperformed existing training and scoring algorithms, in terms of efficiency in identifying successful outliers.