 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Informally Romanized Language Identification
Apr 30, 2025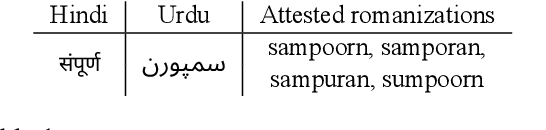
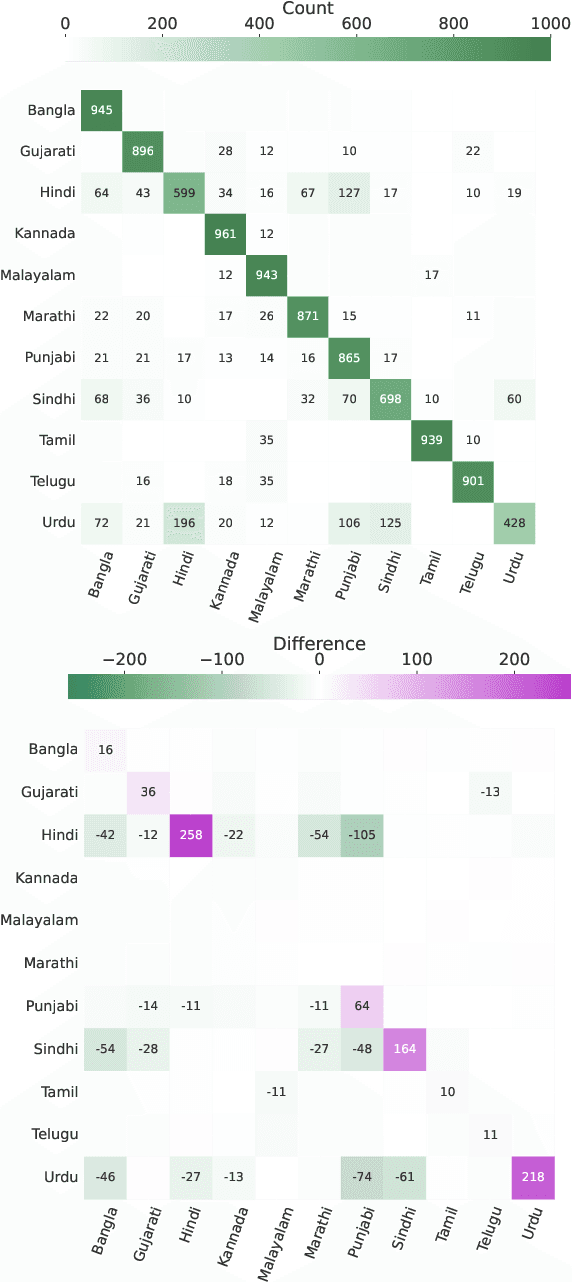

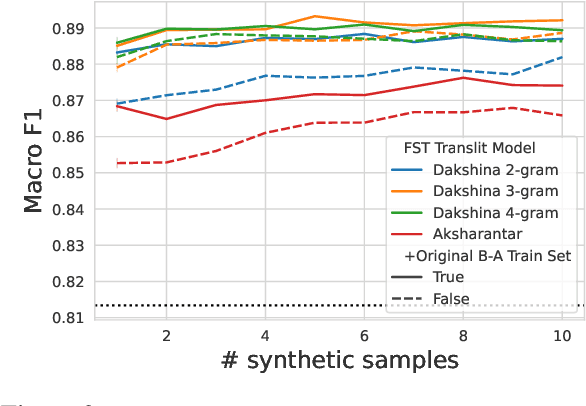
The Latin script is often used to informally write languages with non-Latin native scripts. In many cases (e.g., most languages in India), there is no conventional spelling of words in the Latin script, hence there will be high spelling variability in written text. Such romanization renders languages that are normally easily distinguished based on script highly confusable, such as Hindi and Urdu. In this work, we increase language identification (LID) accuracy for romanized text by improving the methods used to synthesize training sets. We find that training on synthetic samples which incorporate natural spelling variation yields higher LID system accuracy than including available naturally occurring examples in the training set, or even training higher capacity models. We demonstrate new state-of-the-art LID performance on romanized text from 20 Indic languages in the Bhasha-Abhijnaanam evaluation set (Madhani et al., 2023a), improving test F1 from the reported 74.7% (using a pretrained neural model) to 85.4% using a linear classifier trained solely on synthetic data and 88.2% when also training on available harvested text.
XTREME-UP: A User-Centric Scarce-Data Benchmark for Under-Represented Languages
May 24, 2023



Data scarcity is a crucial issue for the development of highly multilingual NLP systems. Yet for many under-represented languages (ULs) -- languages for which NLP re-search is particularly far behind in meeting user needs -- it is feasible to annotate small amounts of data. Motivated by this, we propose XTREME-UP, a benchmark defined by: its focus on the scarce-data scenario rather than zero-shot; its focus on user-centric tasks -- tasks with broad adoption by speakers of high-resource languages; and its focus on under-represented languages where this scarce-data scenario tends to be most realistic. XTREME-UP evaluates the capabilities of language models across 88 under-represented languages over 9 key user-centric technologies including ASR, OCR, MT, and information access tasks that are of general utility. We create new datasets for OCR, autocomplete, semantic parsing, and transliteration, and build on and refine existing datasets for other tasks. XTREME-UP provides methodology for evaluating many modeling scenarios including text-only, multi-modal (vision, audio, and text),supervised parameter tuning, and in-context learning. We evaluate commonly used models on the benchmark. We release all code and scripts to train and evaluate models
Spelling convention sensitivity in neural language models
Mar 06, 2023



We examine whether large neural language models, trained on very large collections of varied English text, learn the potentially long-distance dependency of British versus American spelling conventions, i.e., whether spelling is consistently one or the other within model-generated strings. In contrast to long-distance dependencies in non-surface underlying structure (e.g., syntax), spelling consistency is easier to measure both in LMs and the text corpora used to train them, which can provide additional insight into certain observed model behaviors. Using a set of probe words unique to either British or American English, we first establish that training corpora exhibit substantial (though not total) consistency. A large T5 language model does appear to internalize this consistency, though only with respect to observed lexical items (not nonce words with British/American spelling patterns). We further experiment with correcting for biases in the training data by fine-tuning T5 on synthetic data that has been debiased, and find that finetuned T5 remains only somewhat sensitive to spelling consistency. Further experiments show GPT2 to be similarly limited.
Structured abbreviation expansion in context
Oct 04, 2021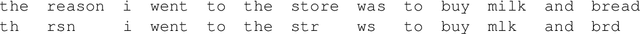
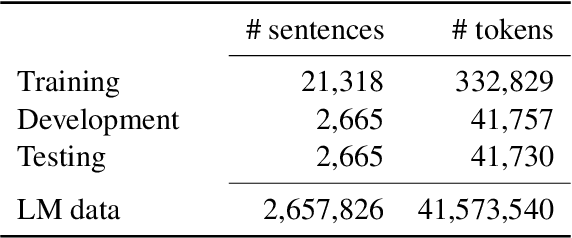
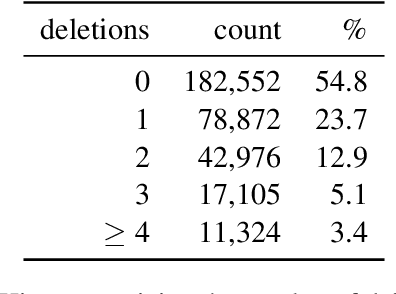
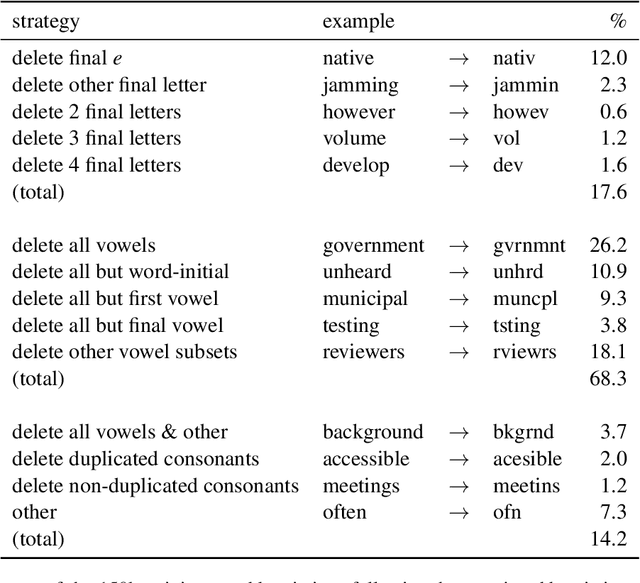
Ad hoc abbreviations are commonly found in informal communication channels that favor shorter messages. We consider the task of reversing these abbreviations in context to recover normalized, expanded versions of abbreviated messages. The problem is related to, but distinct from, spelling correction, in that ad hoc abbreviations are intentional and may involve substantial differences from the original words. Ad hoc abbreviations are productively generated on-the-fly, so they cannot be resolved solely by dictionary lookup. We generate a large, open-source data set of ad hoc abbreviations. This data is used to study abbreviation strategies and to develop two strong baselines for abbreviation expansion
SIGMORPHON 2020 Shared Task 0: Typologically Diverse Morphological Inflection
Jul 14, 2020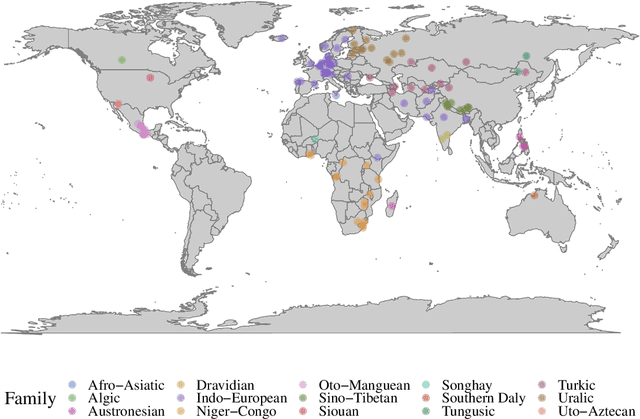
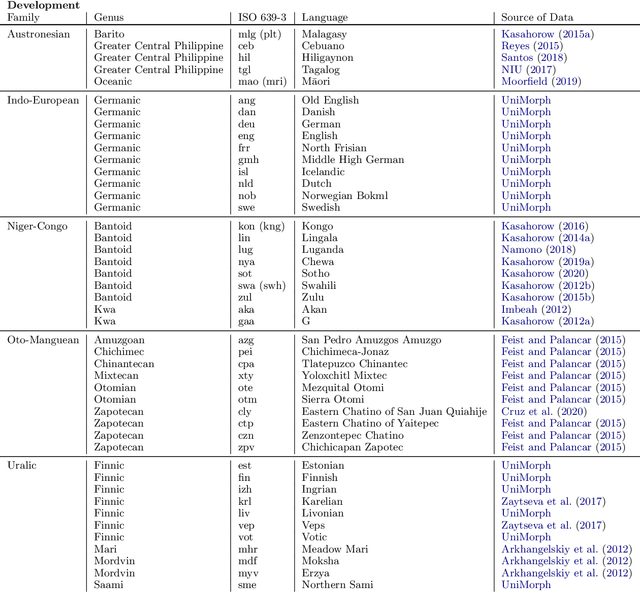
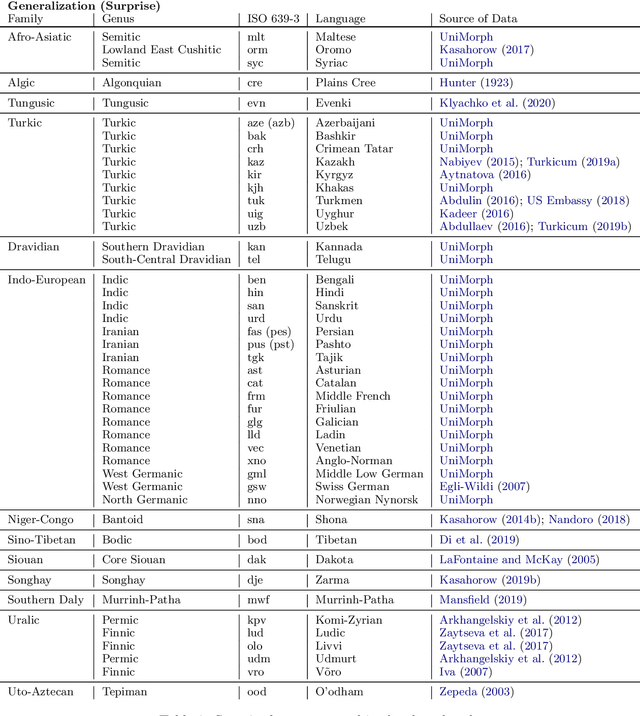
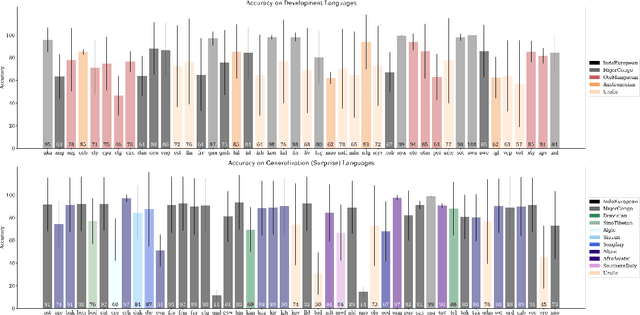
A broad goal in natural language processing (NLP) is to develop a system that has the capacity to process any natural language. Most systems, however, are developed using data from just one language such as English. The SIGMORPHON 2020 shared task on morphological reinflection aims to investigate systems' ability to generalize across typologically distinct languages, many of which are low resource. Systems were developed using data from 45 languages and just 5 language families, fine-tuned with data from an additional 45 languages and 10 language families (13 in total), and evaluated on all 90 languages. A total of 22 systems (19 neural) from 10 teams were submitted to the task. All four winning systems were neural (two monolingual transformers and two massively multilingual RNN-based models with gated attention). Most teams demonstrate utility of data hallucination and augmentation, ensembles, and multilingual training for low-resource languages. Non-neural learners and manually designed grammars showed competitive and even superior performance on some languages (such as Ingrian, Tajik, Tagalog, Zarma, Lingala), especially with very limited data. Some language families (Afro-Asiatic, Niger-Congo, Turkic) were relatively easy for most systems and achieved over 90% mean accuracy while others were more challenging.
Processing South Asian Languages Written in the Latin Script: the Dakshina Dataset
Jul 02, 2020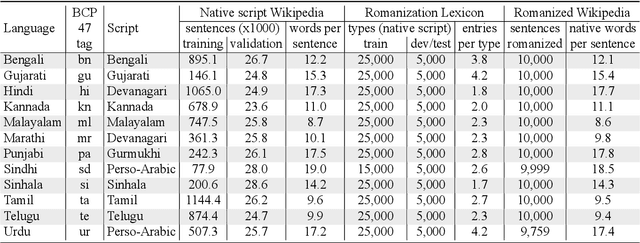
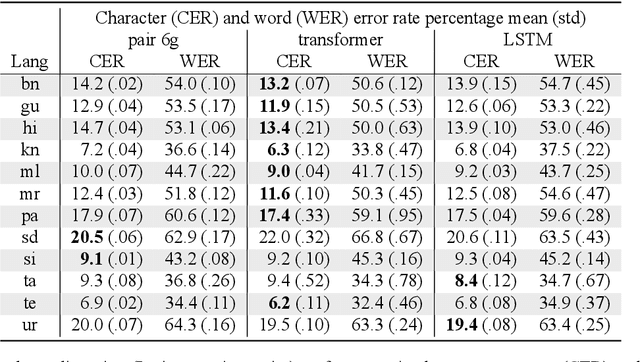

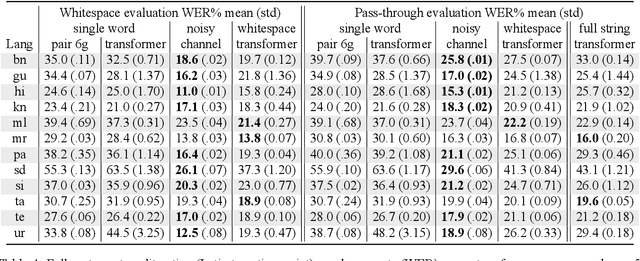
This paper describes the Dakshina dataset, a new resource consisting of text in both the Latin and native scripts for 12 South Asian languages. The dataset includes, for each language: 1) native script Wikipedia text; 2) a romanization lexicon; and 3) full sentence parallel data in both a native script of the language and the basic Latin alphabet. We document the methods used for preparation and selection of the Wikipedia text in each language; collection of attested romanizations for sampled lexicons; and manual romanization of held-out sentences from the native script collections. We additionally provide baseline results on several tasks made possible by the dataset, including single word transliteration, full sentence transliteration, and language modeling of native script and romanized text. Keywords: romanization, transliteration, South Asian languages
Neural Polysynthetic Language Modelling
May 13, 2020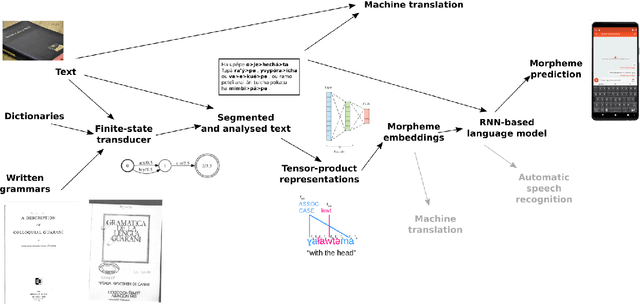

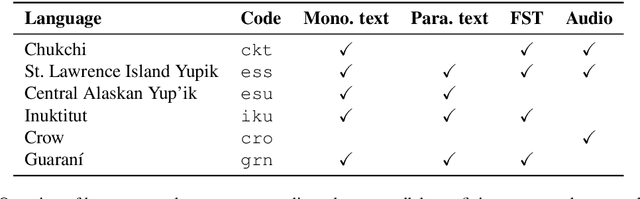
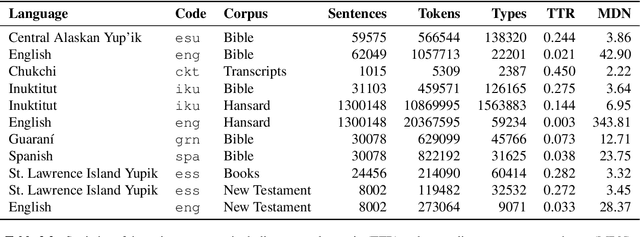
Research in natural language processing commonly assumes that approaches that work well for English and and other widely-used languages are "language agnostic". In high-resource languages, especially those that are analytic, a common approach is to treat morphologically-distinct variants of a common root as completely independent word types. This assumes, that there are limited morphological inflections per root, and that the majority will appear in a large enough corpus, so that the model can adequately learn statistics about each form. Approaches like stemming, lemmatization, or subword segmentation are often used when either of those assumptions do not hold, particularly in the case of synthetic languages like Spanish or Russian that have more inflection than English. In the literature, languages like Finnish or Turkish are held up as extreme examples of complexity that challenge common modelling assumptions. Yet, when considering all of the world's languages, Finnish and Turkish are closer to the average case. When we consider polysynthetic languages (those at the extreme of morphological complexity), approaches like stemming, lemmatization, or subword modelling may not suffice. These languages have very high numbers of hapax legomena, showing the need for appropriate morphological handling of words, without which it is not possible for a model to capture enough word statistics. We examine the current state-of-the-art in language modelling, machine translation, and text prediction for four polysynthetic languages: Guaran\'i, St. Lawrence Island Yupik, Central Alaskan Yupik, and Inuktitut. We then propose a novel framework for language modelling that combines knowledge representations from finite-state morphological analyzers with Tensor Product Representations in order to enable neural language models capable of handling the full range of typologically variant languages.
The SIGMORPHON 2019 Shared Task: Morphological Analysis in Context and Cross-Lingual Transfer for Inflection
Oct 25, 2019
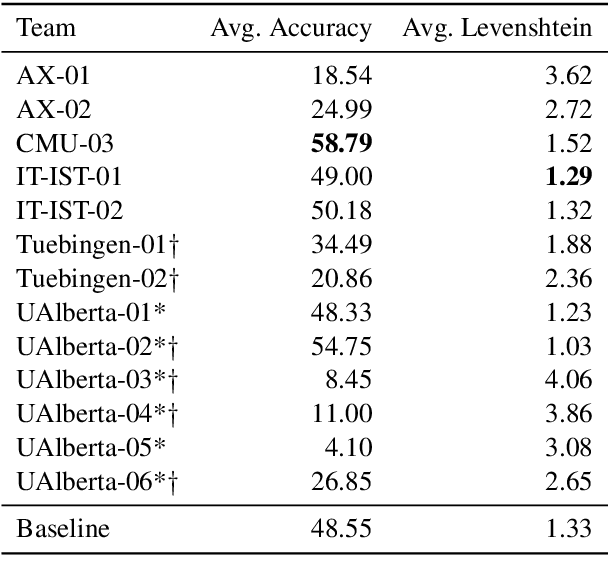
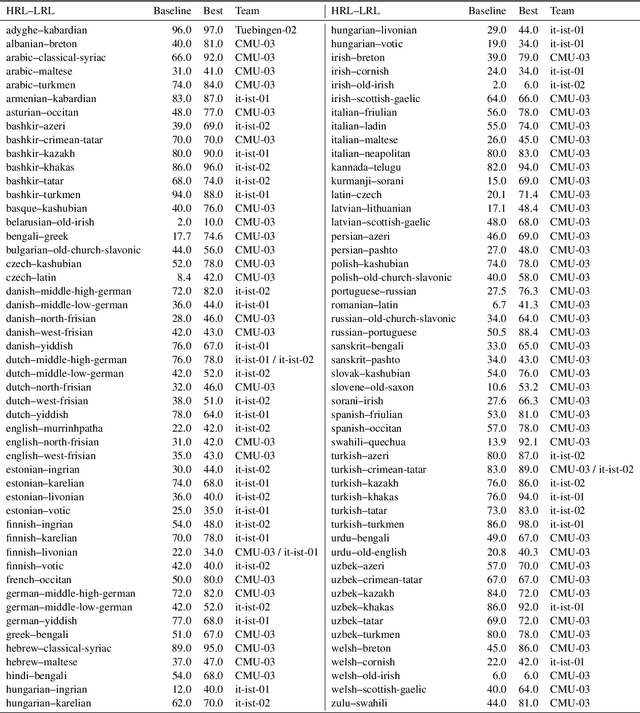
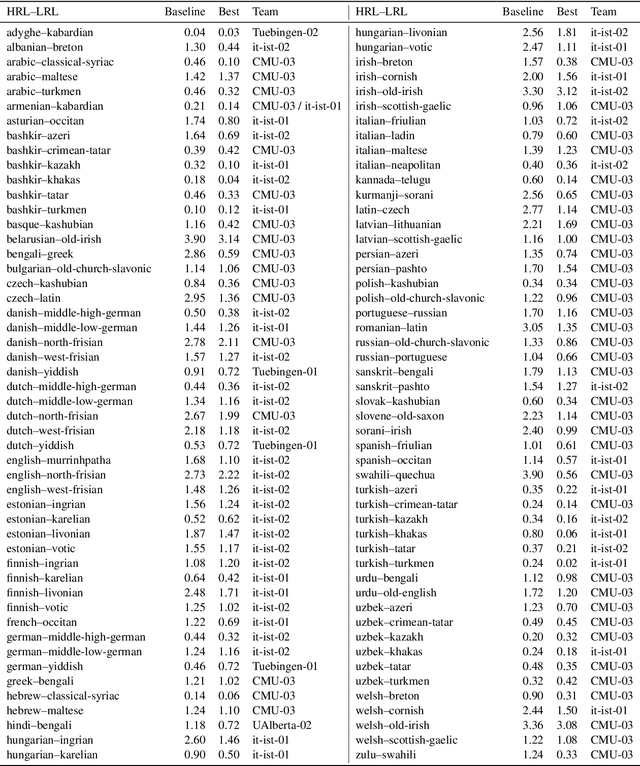
The SIGMORPHON 2019 shared task on cross-lingual transfer and contextual analysis in morphology examined transfer learning of inflection between 100 language pairs, as well as contextual lemmatization and morphosyntactic description in 66 languages. The first task evolves past years' inflection tasks by examining transfer of morphological inflection knowledge from a high-resource language to a low-resource language. This year also presents a new second challenge on lemmatization and morphological feature analysis in context. All submissions featured a neural component and built on either this year's strong baselines or highly ranked systems from previous years' shared tasks. Every participating team improved in accuracy over the baselines for the inflection task (though not Levenshtein distance), and every team in the contextual analysis task improved on both state-of-the-art neural and non-neural baselines.
* Presented at SIGMORPHON 2019
UniMorph 2.0: Universal Morphology
Oct 25, 2018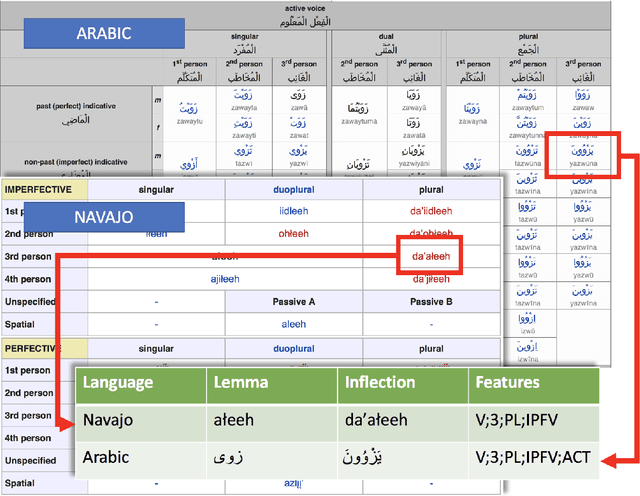
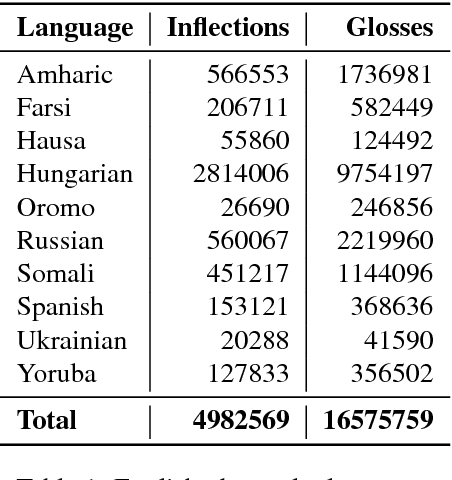

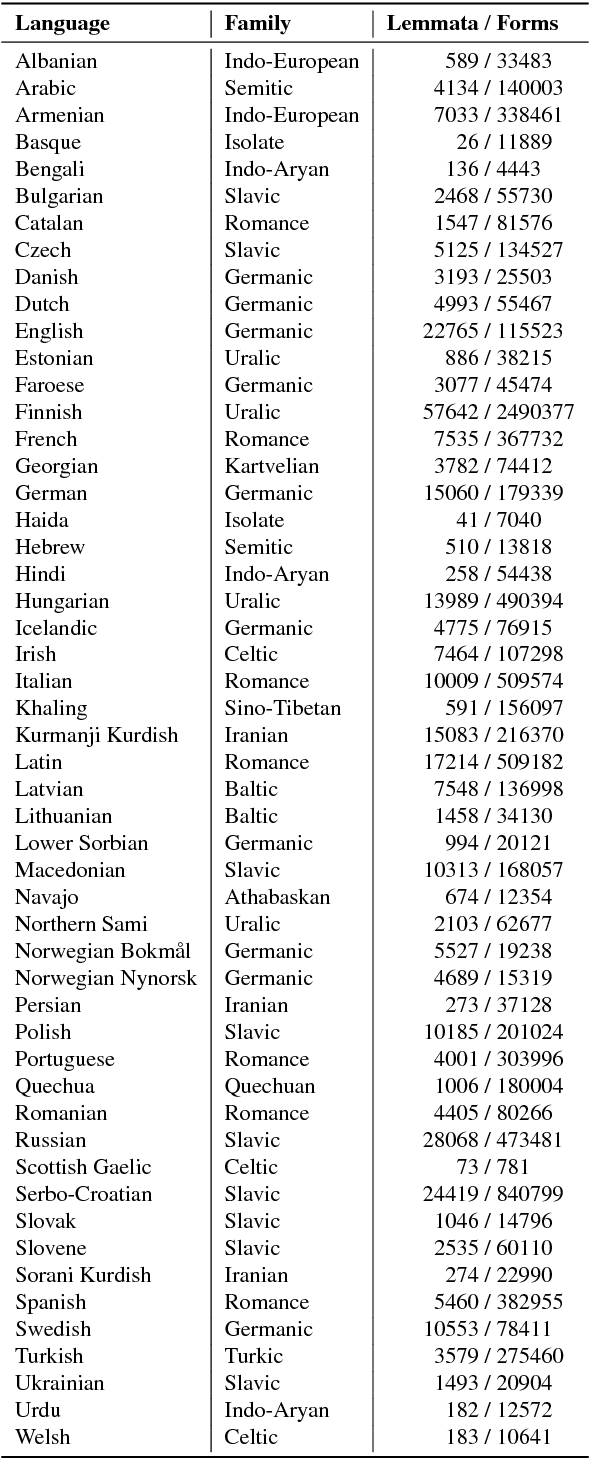
The Universal Morphology UniMorph project is a collaborative effort to improve how NLP handles complex morphology across the world's languages. The project releases annotated morphological data using a universal tagset, the UniMorph schema. Each inflected form is associated with a lemma, which typically carries its underlying lexical meaning, and a bundle of morphological features from our schema. Additional supporting data and tools are also released on a per-language basis when available. UniMorph is based at the Center for Language and Speech Processing (CLSP) at Johns Hopkins University in Baltimore, Maryland and is sponsored by the DARPA LORELEI program. This paper details advances made to the collection, annotation, and dissemination of project resources since the initial UniMorph release described at LREC 2016. lexical resources} }
The CoNLL--SIGMORPHON 2018 Shared Task: Universal Morphological Reinflection
Oct 18, 2018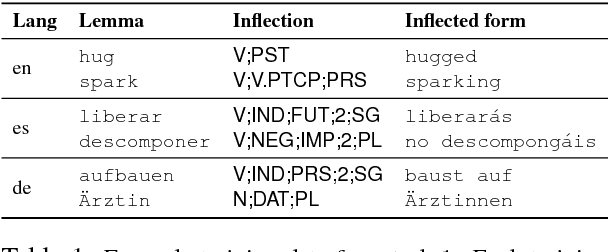
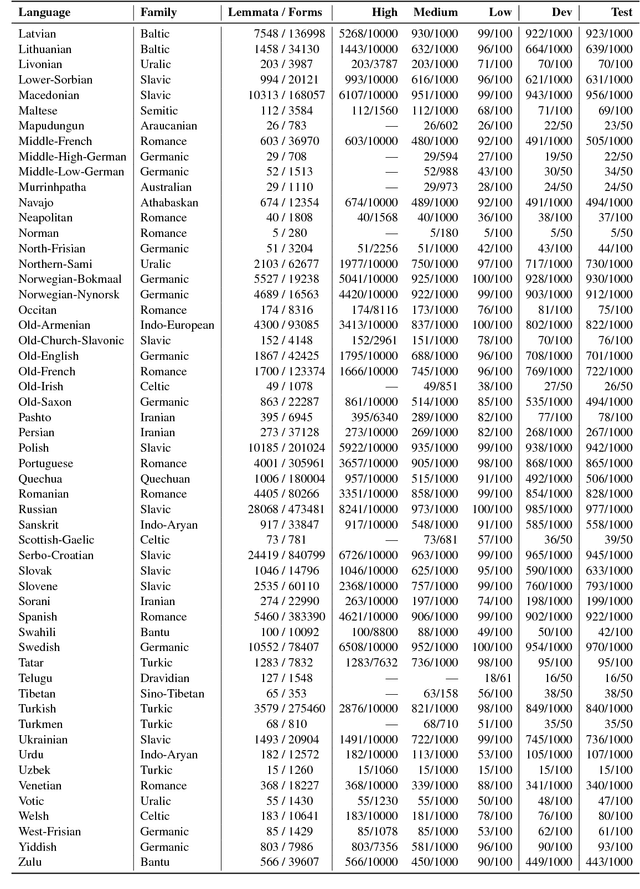

The CoNLL--SIGMORPHON 2018 shared task on supervised learning of morphological generation featured data sets from 103 typologically diverse languages. Apart from extending the number of languages involved in earlier supervised tasks of generating inflected forms, this year the shared task also featured a new second task which asked participants to inflect words in sentential context, similar to a cloze task. This second task featured seven languages. Task 1 received 27 submissions and task 2 received 6 submissions. Both tasks featured a low, medium, and high data condition. Nearly all submissions featured a neural component and built on highly-ranked systems from the earlier 2017 shared task. In the inflection task (task 1), 41 of the 52 languages present in last year's inflection task showed improvement by the best systems in the low-resource setting. The cloze task (task 2) proved to be difficult, and few submissions managed to consistently improve upon both a simple neural baseline system and a lemma-repeating baseline.