 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScience Out of Its Ivory Tower: Improving Accessibility with Reinforcement Learning
Oct 22, 2024A vast amount of scholarly work is published daily, yet much of it remains inaccessible to the general public due to dense jargon and complex language. To address this challenge in science communication, we introduce a reinforcement learning framework that fine-tunes a language model to rewrite scholarly abstracts into more comprehensible versions. Guided by a carefully balanced combination of word- and sentence-level accessibility rewards, our language model effectively substitutes technical terms with more accessible alternatives, a task which models supervised fine-tuned or guided by conventional readability measures struggle to accomplish. Our best model adjusts the readability level of scholarly abstracts by approximately six U.S. grade levels -- in other words, from a postgraduate to a high school level. This translates to roughly a 90% relative boost over the supervised fine-tuning baseline, all while maintaining factual accuracy and high-quality language. An in-depth analysis of our approach shows that balanced rewards lead to systematic modifications in the base model, likely contributing to smoother optimization and superior performance. We envision this work as a step toward bridging the gap between scholarly research and the general public, particularly younger readers and those without a college degree.
UM-IU@LING at SemEval-2019 Task 6: Identifying Offensive Tweets Using BERT and SVMs
Apr 06, 2019

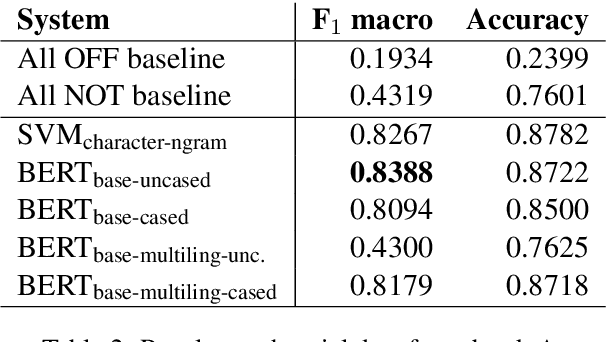

This paper describes the UM-IU@LING's system for the SemEval 2019 Task 6: OffensEval. We take a mixed approach to identify and categorize hate speech in social media. In subtask A, we fine-tuned a BERT based classifier to detect abusive content in tweets, achieving a macro F1 score of 0.8136 on the test data, thus reaching the 3rd rank out of 103 submissions. In subtasks B and C, we used a linear SVM with selected character n-gram features. For subtask C, our system could identify the target of abuse with a macro F1 score of 0.5243, ranking it 27th out of 65 submissions.
UniMorph 2.0: Universal Morphology
Oct 25, 2018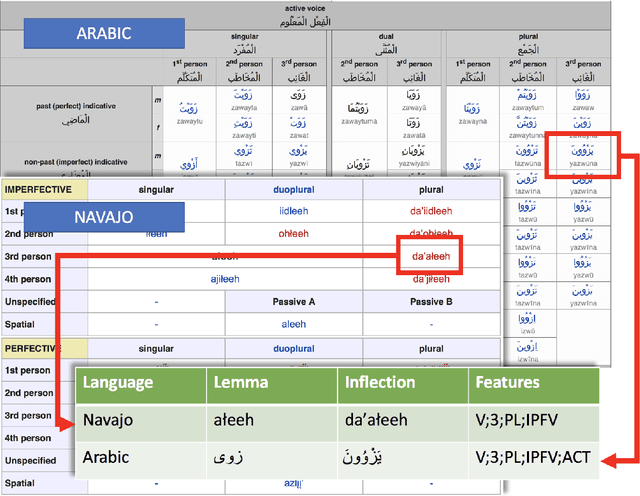
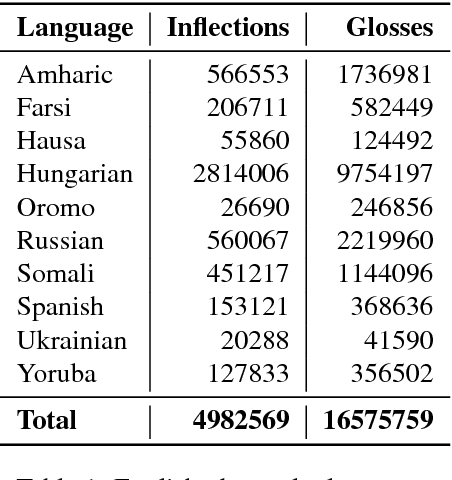

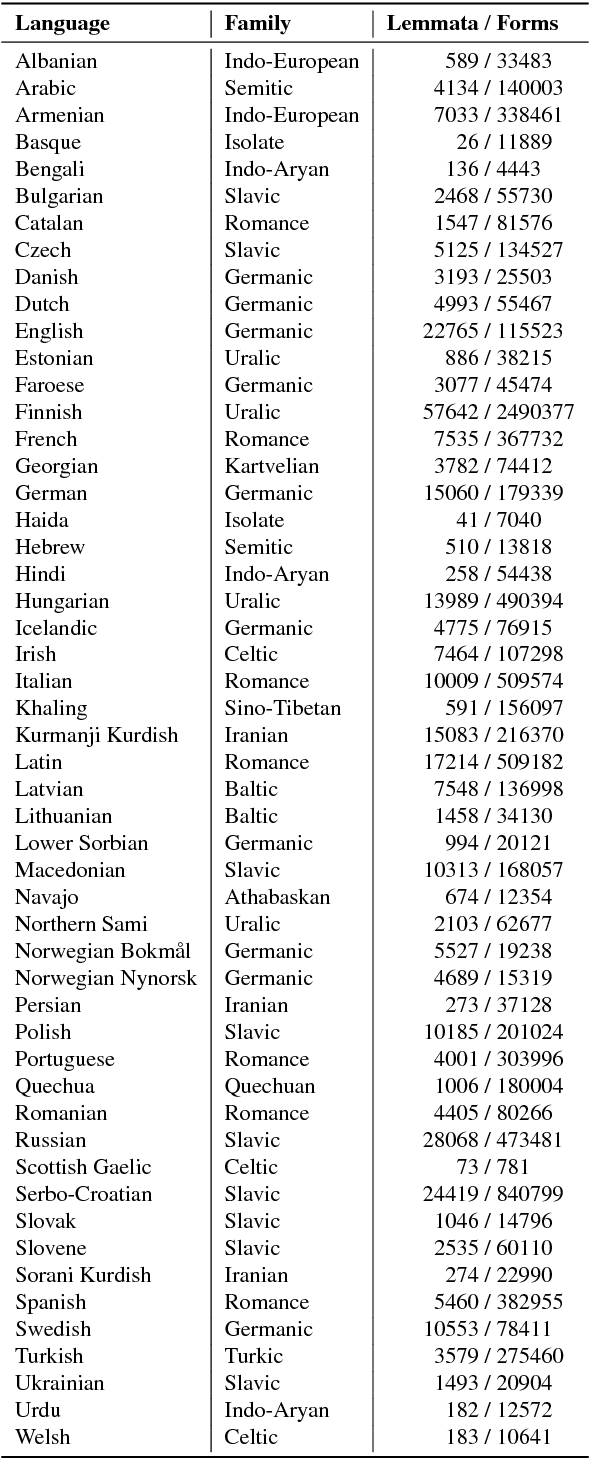
The Universal Morphology UniMorph project is a collaborative effort to improve how NLP handles complex morphology across the world's languages. The project releases annotated morphological data using a universal tagset, the UniMorph schema. Each inflected form is associated with a lemma, which typically carries its underlying lexical meaning, and a bundle of morphological features from our schema. Additional supporting data and tools are also released on a per-language basis when available. UniMorph is based at the Center for Language and Speech Processing (CLSP) at Johns Hopkins University in Baltimore, Maryland and is sponsored by the DARPA LORELEI program. This paper details advances made to the collection, annotation, and dissemination of project resources since the initial UniMorph release described at LREC 2016. lexical resources} }
Detecting Syntactic Features of Translated Chinese
Apr 23, 2018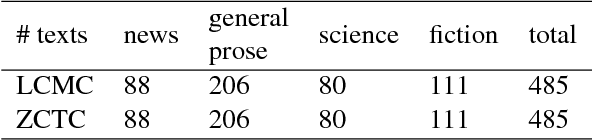



We present a machine learning approach to distinguish texts translated to Chinese (by humans) from texts originally written in Chinese, with a focus on a wide range of syntactic features. Using Support Vector Machines (SVMs) as classifier on a genre-balanced corpus in translation studies of Chinese, we find that constituent parse trees and dependency triples as features without lexical information perform very well on the task, with an F-measure above 90%, close to the results of lexical n-gram features, without the risk of learning topic information rather than translation features. Thus, we claim syntactic features alone can accurately distinguish translated from original Chinese. Translated Chinese exhibits an increased use of determiners, subject position pronouns, NP + 'de' as NP modifiers, multiple NPs or VPs conjoined by a Chinese specific punctuation, among other structures. We also interpret the syntactic features with reference to previous translation studies in Chinese, particularly the usage of pronouns.
CoNLL-SIGMORPHON 2017 Shared Task: Universal Morphological Reinflection in 52 Languages
Jul 04, 2017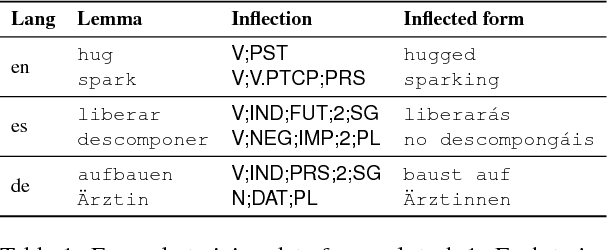
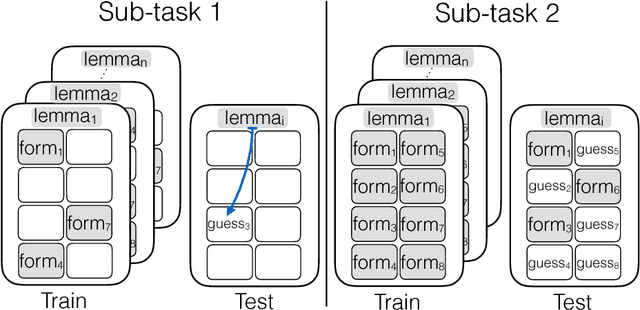
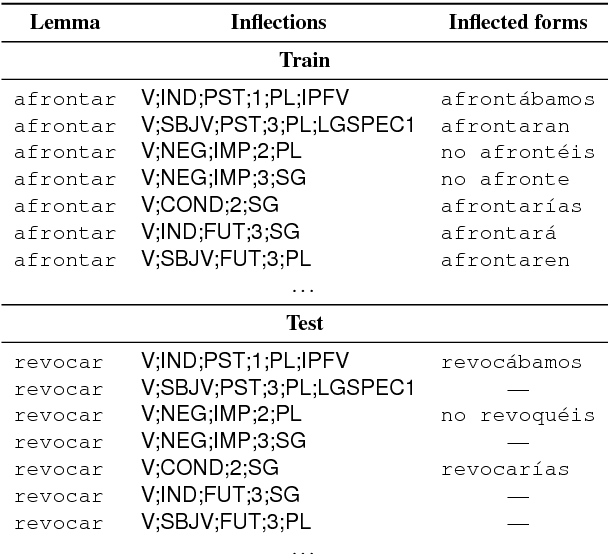
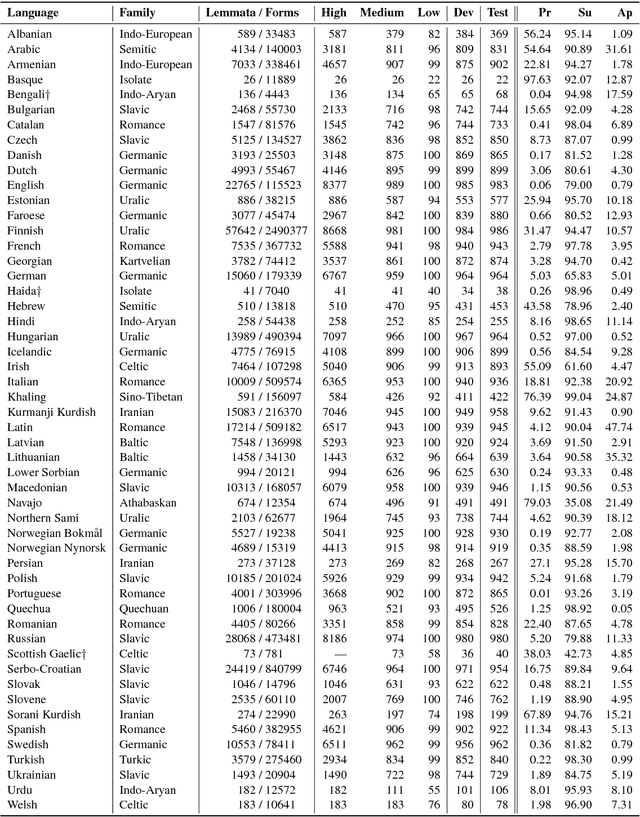
The CoNLL-SIGMORPHON 2017 shared task on supervised morphological generation required systems to be trained and tested in each of 52 typologically diverse languages. In sub-task 1, submitted systems were asked to predict a specific inflected form of a given lemma. In sub-task 2, systems were given a lemma and some of its specific inflected forms, and asked to complete the inflectional paradigm by predicting all of the remaining inflected forms. Both sub-tasks included high, medium, and low-resource conditions. Sub-task 1 received 24 system submissions, while sub-task 2 received 3 system submissions. Following the success of neural sequence-to-sequence models in the SIGMORPHON 2016 shared task, all but one of the submissions included a neural component. The results show that high performance can be achieved with small training datasets, so long as models have appropriate inductive bias or make use of additional unlabeled data or synthetic data. However, different biasing and data augmentation resulted in disjoint sets of inflected forms being predicted correctly, suggesting that there is room for future improvement.
Performing Stance Detection on Twitter Data using Computational Linguistics Techniques
Mar 06, 2017



As humans, we can often detect from a persons utterances if he or she is in favor of or against a given target entity (topic, product, another person, etc). But from the perspective of a computer, we need means to automatically deduce the stance of the tweeter, given just the tweet text. In this paper, we present our results of performing stance detection on twitter data using a supervised approach. We begin by extracting bag-of-words to perform classification using TIMBL, then try and optimize the features to improve stance detection accuracy, followed by extending the dataset with two sets of lexicons - arguing, and MPQA subjectivity; next we explore the MALT parser and construct features using its dependency triples, finally we perform analysis using Scikit-learn Random Forest implementation.