 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe SIGMORPHON 2019 Shared Task: Morphological Analysis in Context and Cross-Lingual Transfer for Inflection
Oct 25, 2019
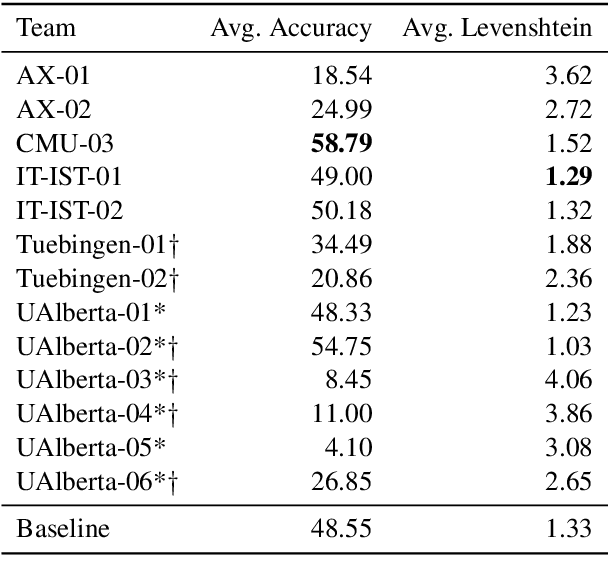
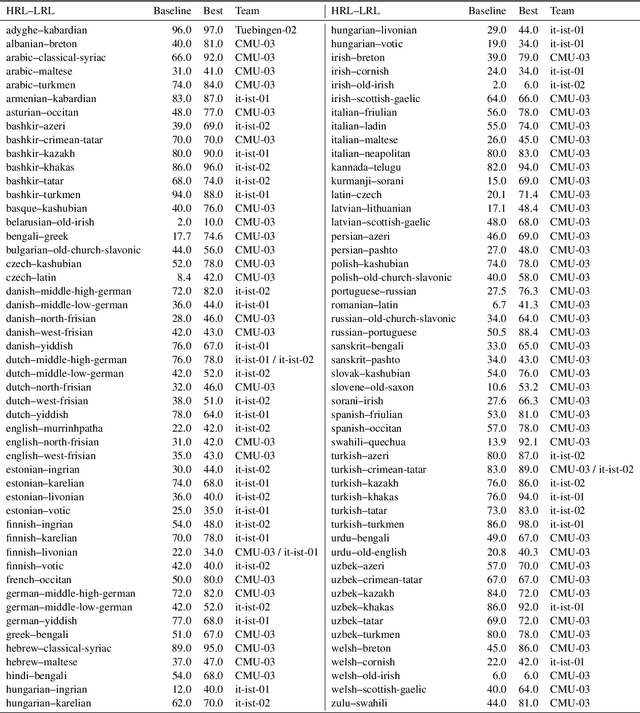
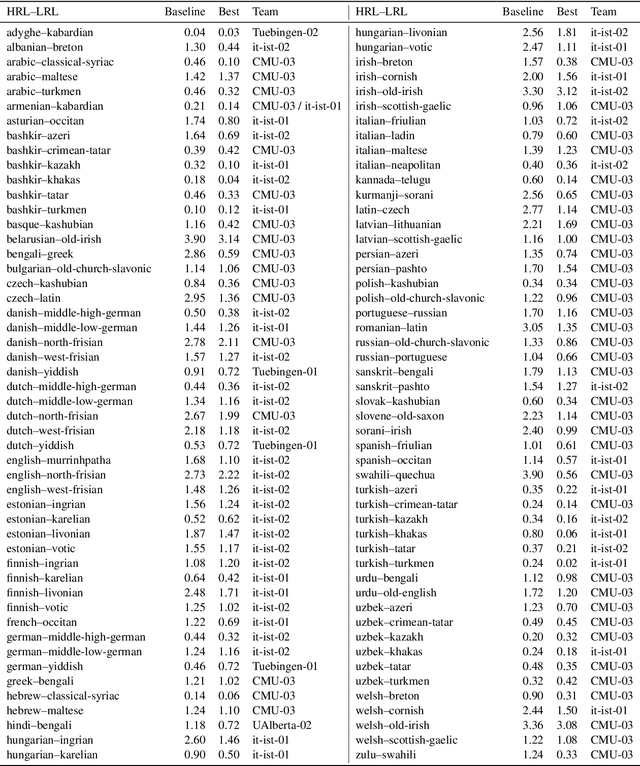
The SIGMORPHON 2019 shared task on cross-lingual transfer and contextual analysis in morphology examined transfer learning of inflection between 100 language pairs, as well as contextual lemmatization and morphosyntactic description in 66 languages. The first task evolves past years' inflection tasks by examining transfer of morphological inflection knowledge from a high-resource language to a low-resource language. This year also presents a new second challenge on lemmatization and morphological feature analysis in context. All submissions featured a neural component and built on either this year's strong baselines or highly ranked systems from previous years' shared tasks. Every participating team improved in accuracy over the baselines for the inflection task (though not Levenshtein distance), and every team in the contextual analysis task improved on both state-of-the-art neural and non-neural baselines.
* Presented at SIGMORPHON 2019
What Kind of Language Is Hard to Language-Model?
Jun 11, 2019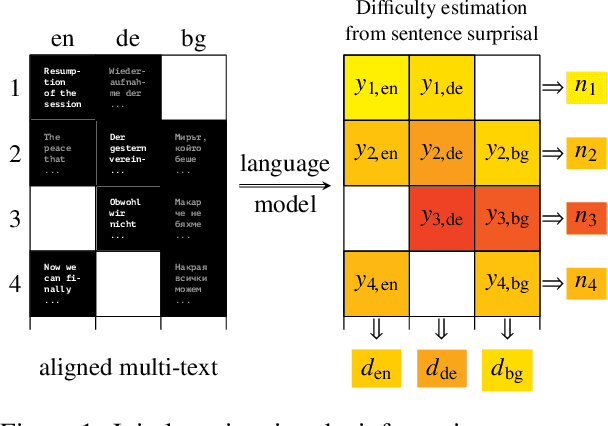
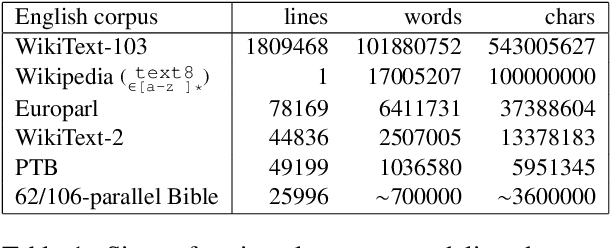
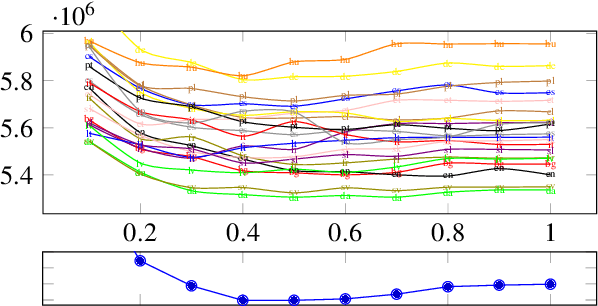
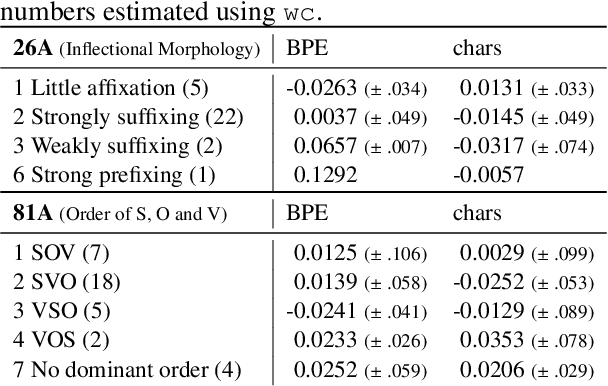
How language-agnostic are current state-of-the-art NLP tools? Are there some types of language that are easier to model with current methods? In prior work (Cotterell et al., 2018) we attempted to address this question for language modeling, and observed that recurrent neural network language models do not perform equally well over all the high-resource European languages found in the Europarl corpus. We speculated that inflectional morphology may be the primary culprit for the discrepancy. In this paper, we extend these earlier experiments to cover 69 languages from 13 language families using a multilingual Bible corpus. Methodologically, we introduce a new paired-sample multiplicative mixed-effects model to obtain language difficulty coefficients from at-least-pairwise parallel corpora. In other words, the model is aware of inter-sentence variation and can handle missing data. Exploiting this model, we show that "translationese" is not any easier to model than natively written language in a fair comparison. Trying to answer the question of what features difficult languages have in common, we try and fail to reproduce our earlier (Cotterell et al., 2018) observation about morphological complexity and instead reveal far simpler statistics of the data that seem to drive complexity in a much larger sample.
Counterfactual Data Augmentation for Mitigating Gender Stereotypes in Languages with Rich Morphology
Jun 11, 2019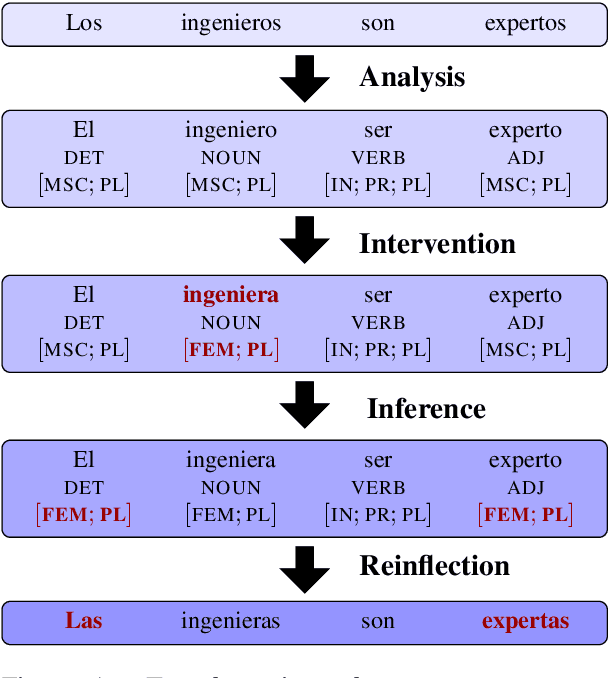
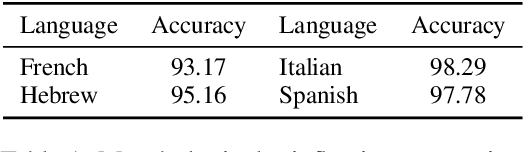
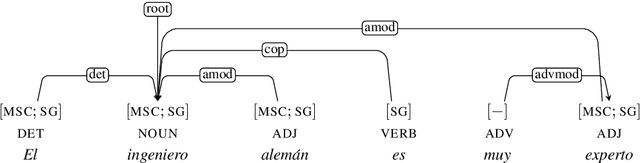
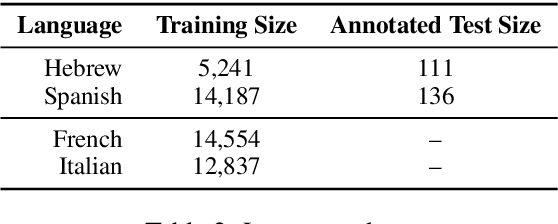
Gender stereotypes are manifest in most of the world's languages and are consequently propagated or amplified by NLP systems. Although research has focused on mitigating gender stereotypes in English, the approaches that are commonly employed produce ungrammatical sentences in morphologically rich languages. We present a novel approach for converting between masculine-inflected and feminine-inflected sentences in such languages. For Spanish and Hebrew, our approach achieves F1 scores of 82% and 73% at the level of tags and accuracies of 90% and 87% at the level of forms. By evaluating our approach using four different languages, we show that, on average, it reduces gender stereotyping by a factor of 2.5 without any sacrifice to grammaticality.
Spell Once, Summon Anywhere: A Two-Level Open-Vocabulary Language Model
Sep 06, 2018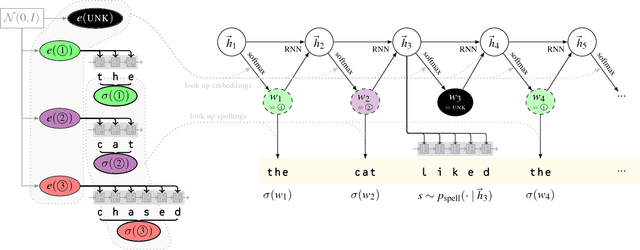

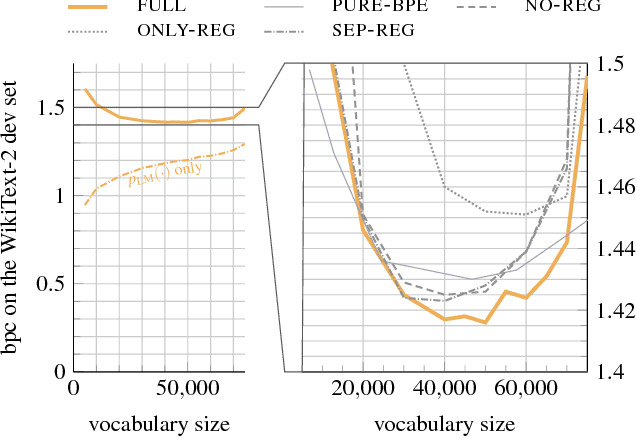

We show how the spellings of known words can help us deal with unknown words in open-vocabulary NLP tasks. The method we propose can be used to extend any closed-vocabulary generative model, but in this paper we specifically consider the case of neural language modeling. Our Bayesian generative story combines a standard RNN language model (generating the word tokens in each sentence) with an RNN-based spelling model (generating the letters in each word type). These two RNNs respectively capture sentence structure and word structure, and are kept separate as in linguistics. By invoking the second RNN to generate spellings for novel words in context, we obtain an open-vocabulary language model. For known words, embeddings are naturally inferred by combining evidence from type spelling and token context. Comparing to baselines (including a novel strong baseline), we beat previous work and establish state-of-the-art results on multiple datasets.
A Structured Variational Autoencoder for Contextual Morphological Inflection
Jun 10, 2018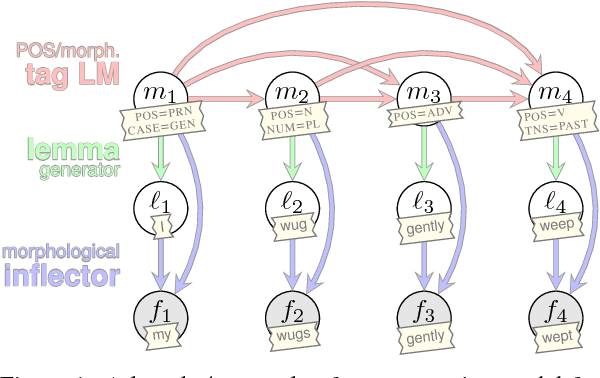

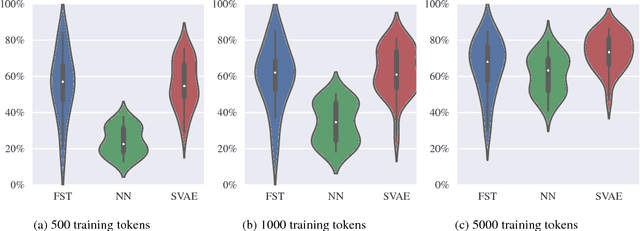
Statistical morphological inflectors are typically trained on fully supervised, type-level data. One remaining open research question is the following: How can we effectively exploit raw, token-level data to improve their performance? To this end, we introduce a novel generative latent-variable model for the semi-supervised learning of inflection generation. To enable posterior inference over the latent variables, we derive an efficient variational inference procedure based on the wake-sleep algorithm. We experiment on 23 languages, using the Universal Dependencies corpora in a simulated low-resource setting, and find improvements of over 10% absolute accuracy in some cases.
Are All Languages Equally Hard to Language-Model?
Jun 10, 2018
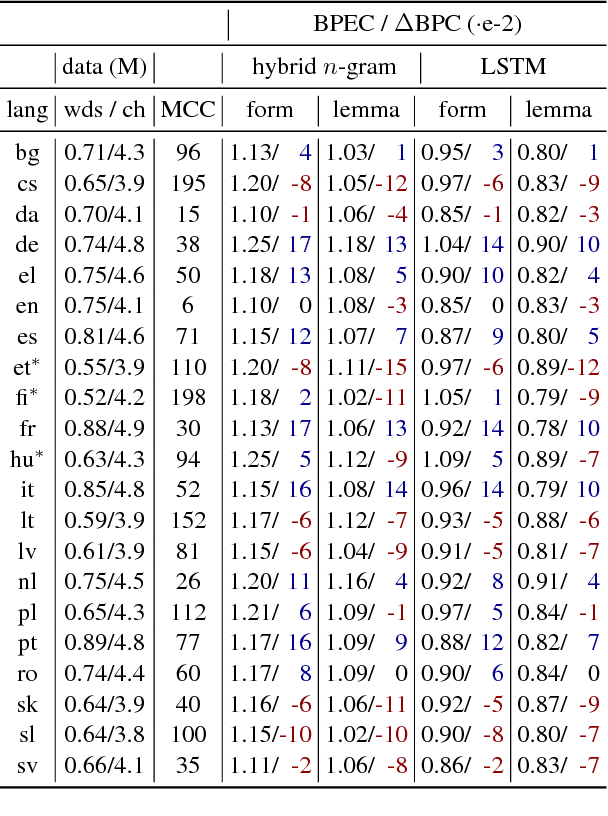

For general modeling methods applied to diverse languages, a natural question is: how well should we expect our models to work on languages with differing typological profiles? In this work, we develop an evaluation framework for fair cross-linguistic comparison of language models, using translated text so that all models are asked to predict approximately the same information. We then conduct a study on 21 languages, demonstrating that in some languages, the textual expression of the information is harder to predict with both $n$-gram and LSTM language models. We show complex inflectional morphology to be a cause of performance differences among languages.
Unsupervised Disambiguation of Syncretism in Inflected Lexicons
Jun 10, 2018

Lexical ambiguity makes it difficult to compute various useful statistics of a corpus. A given word form might represent any of several morphological feature bundles. One can, however, use unsupervised learning (as in EM) to fit a model that probabilistically disambiguates word forms. We present such an approach, which employs a neural network to smoothly model a prior distribution over feature bundles (even rare ones). Although this basic model does not consider a token's context, that very property allows it to operate on a simple list of unigram type counts, partitioning each count among different analyses of that unigram. We discuss evaluation metrics for this novel task and report results on 5 languages.