 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Neural Networks as Recognizers of Formal Languages
Nov 11, 2024Characterizing the computational power of neural network architectures in terms of formal language theory remains a crucial line of research, as it describes lower and upper bounds on the reasoning capabilities of modern AI. However, when empirically testing these bounds, existing work often leaves a discrepancy between experiments and the formal claims they are meant to support. The problem is that formal language theory pertains specifically to recognizers: machines that receive a string as input and classify whether it belongs to a language. On the other hand, it is common to instead use proxy tasks that are similar in only an informal sense, such as language modeling or sequence-to-sequence transduction. We correct this mismatch by training and evaluating neural networks directly as binary classifiers of strings, using a general method that can be applied to a wide variety of languages. As part of this, we extend an algorithm recently proposed by Sn{\ae}bjarnarson et al. (2024) to do length-controlled sampling of strings from regular languages, with much better asymptotic time complexity than previous methods. We provide results on a variety of languages across the Chomsky hierarchy for three neural architectures: a simple RNN, an LSTM, and a causally-masked transformer. We find that the RNN and LSTM often outperform the transformer, and that auxiliary training objectives such as language modeling can help, although no single objective uniformly improves performance across languages and architectures. Our contributions will facilitate theoretically sound empirical testing of language recognition claims in future work. We have released our datasets as a benchmark called FLaRe (Formal Language Recognition), along with our code.
HR-Agent: A Task-Oriented Dialogue (TOD) LLM Agent Tailored for HR Applications
Oct 15, 2024Recent LLM (Large Language Models) advancements benefit many fields such as education and finance, but HR has hundreds of repetitive processes, such as access requests, medical claim filing and time-off submissions, which are unaddressed. We relate these tasks to the LLM agent, which has addressed tasks such as writing assisting and customer support. We present HR-Agent, an efficient, confidential, and HR-specific LLM-based task-oriented dialogue system tailored for automating repetitive HR processes such as medical claims and access requests. Since conversation data is not sent to an LLM during inference, it preserves confidentiality required in HR-related tasks.
A Fundamental Trade-off in Aligned Language Models and its Relation to Sampling Adaptors
Jun 14, 2024



The relationship between the quality of a string and its probability $p(\boldsymbol{y})$ under a language model has been influential in the development of techniques to build good text generation systems. For example, several decoding algorithms have been motivated to manipulate $p(\boldsymbol{y})$ to produce higher-quality text. In this work, we examine the probability--quality relationship in language models explicitly aligned to human preferences, e.g., through Reinforcement Learning through Human Feedback (RLHF). We find that, given a general language model and its aligned version, for corpora sampled from an aligned language model, there exists a trade-off between the average reward and average log-likelihood of the strings under the general language model. We provide a formal treatment of this issue and demonstrate how a choice of sampling adaptor allows for a selection of how much likelihood we exchange for the reward.
What Languages are Easy to Language-Model? A Perspective from Learning Probabilistic Regular Languages
Jun 07, 2024What can large language models learn? By definition, language models (LM) are distributions over strings. Therefore, an intuitive way of addressing the above question is to formalize it as a matter of learnability of classes of distributions over strings. While prior work in this direction focused on assessing the theoretical limits, in contrast, we seek to understand the empirical learnability. Unlike prior empirical work, we evaluate neural LMs on their home turf-learning probabilistic languages-rather than as classifiers of formal languages. In particular, we investigate the learnability of regular LMs (RLMs) by RNN and Transformer LMs. We empirically test the learnability of RLMs as a function of various complexity parameters of the RLM and the hidden state size of the neural LM. We find that the RLM rank, which corresponds to the size of linear space spanned by the logits of its conditional distributions, and the expected length of sampled strings are strong and significant predictors of learnability for both RNNs and Transformers. Several other predictors also reach significance, but with differing patterns between RNNs and Transformers.
Towards Explainability in Legal Outcome Prediction Models
Mar 25, 2024
Current legal outcome prediction models - a staple of legal NLP - do not explain their reasoning. However, to employ these models in the real world, human legal actors need to be able to understand their decisions. In the case of common law, legal practitioners reason towards the outcome of a case by referring to past case law, known as precedent. We contend that precedent is, therefore, a natural way of facilitating explainability for legal NLP models. In this paper, we contribute a novel method for identifying the precedent employed by legal outcome prediction models. Furthermore, by developing a taxonomy of legal precedent, we are able to compare human judges and our models with respect to the different types of precedent they rely on. We find that while the models learn to predict outcomes reasonably well, their use of precedent is unlike that of human judges.
The Ethics of Automating Legal Actors
Dec 01, 2023The introduction of large public legal datasets has brought about a renaissance in legal NLP. Many of these datasets are comprised of legal judgements - the product of judges deciding cases. This fact, together with the way machine learning works, means that several legal NLP models are models of judges. While some have argued for the automation of judges, in this position piece, we argue that automating the role of the judge raises difficult ethical challenges, in particular for common law legal systems. Our argument follows from the social role of the judge in actively shaping the law, rather than merely applying it. Since current NLP models come nowhere close to having the facilities necessary for this task, they should not be used to automate judges. Furthermore, even in the case the models could achieve human-level capabilities, there would still be remaining ethical concerns inherent in the automation of the legal process.
The Architectural Bottleneck Principle
Nov 11, 2022In this paper, we seek to measure how much information a component in a neural network could extract from the representations fed into it. Our work stands in contrast to prior probing work, most of which investigates how much information a model's representations contain. This shift in perspective leads us to propose a new principle for probing, the architectural bottleneck principle: In order to estimate how much information a given component could extract, a probe should look exactly like the component. Relying on this principle, we estimate how much syntactic information is available to transformers through our attentional probe, a probe that exactly resembles a transformer's self-attention head. Experimentally, we find that, in three models (BERT, ALBERT, and RoBERTa), a sentence's syntax tree is mostly extractable by our probe, suggesting these models have access to syntactic information while composing their contextual representations. Whether this information is actually used by these models, however, remains an open question.
An Ordinal Latent Variable Model of Conflict Intensity
Oct 08, 2022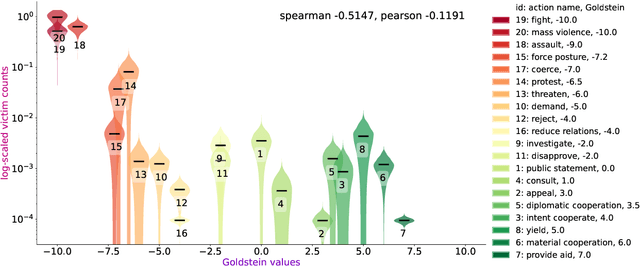
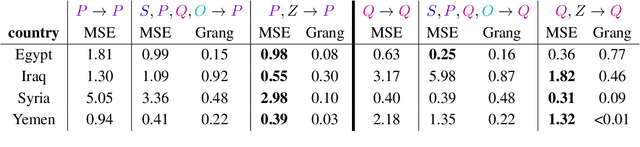
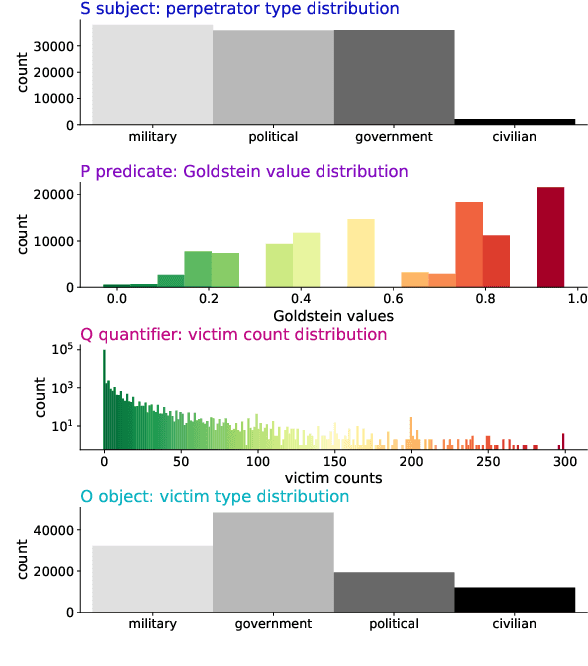

For the quantitative monitoring of international relations, political events are extracted from the news and parsed into "who-did-what-to-whom" patterns. This has resulted in large data collections which require aggregate statistics for analysis. The Goldstein Scale is an expert-based measure that ranks individual events on a one-dimensional scale from conflictual to cooperative. However, the scale disregards fatality counts as well as perpetrator and victim types involved in an event. This information is typically considered in qualitative conflict assessment. To address this limitation, we propose a probabilistic generative model over the full subject-predicate-quantifier-object tuples associated with an event. We treat conflict intensity as an interpretable, ordinal latent variable that correlates conflictual event types with high fatality counts. Taking a Bayesian approach, we learn a conflict intensity scale from data and find the optimal number of intensity classes. We evaluate the model by imputing missing data. Our scale proves to be more informative than the original Goldstein Scale in autoregressive forecasting and when compared with global online attention towards armed conflicts.
Prompting for a conversation: How to control a dialog model?
Sep 22, 2022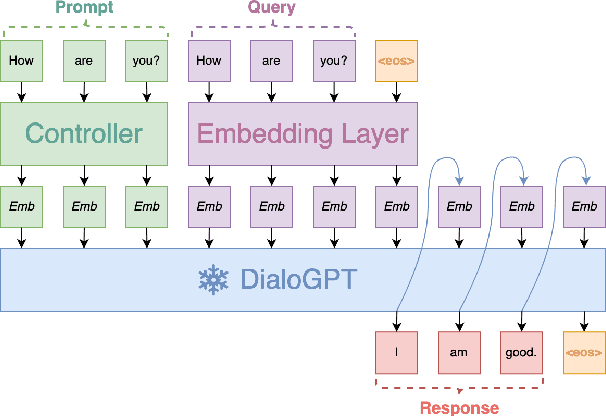
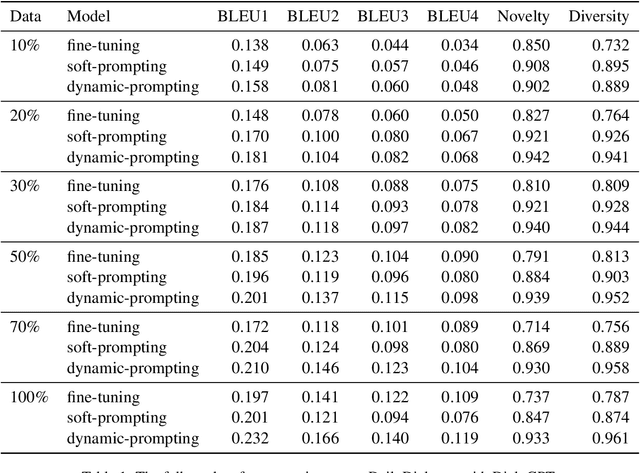
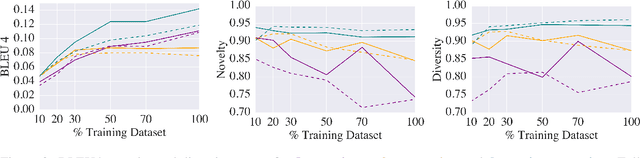
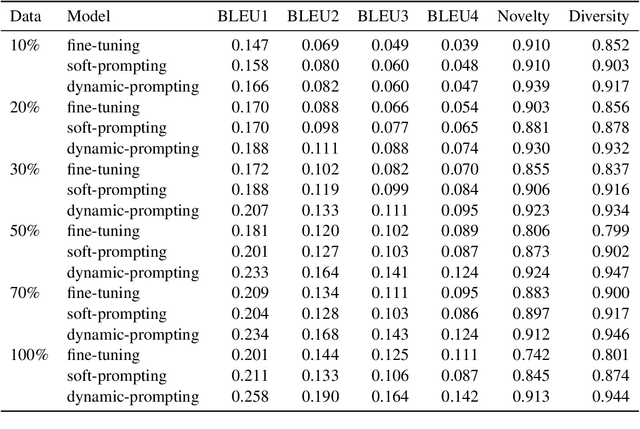
Dialog modelling faces a difficult trade-off. Models are trained on a large amount of text, yet their responses need to be limited to a desired scope and style of a dialog agent. Because the datasets used to achieve the former contain language that is not compatible with the latter, pre-trained dialog models are fine-tuned on smaller curated datasets. However, the fine-tuning process robs them of the ability to produce diverse responses, eventually reducing them to dull conversation partners. In this paper we investigate if prompting can mitigate the above trade-off. Specifically, we experiment with conditioning the prompt on the query, rather than training a single prompt for all queries. By following the intuition that freezing the pre-trained language model will conserve its expressivity, we find that compared to fine-tuning, prompting can achieve a higher BLEU score and substantially improve the diversity and novelty of the responses.
On the Role of Negative Precedent in Legal Outcome Prediction
Aug 17, 2022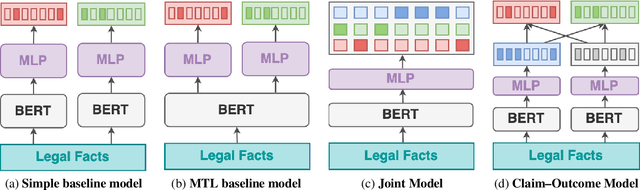
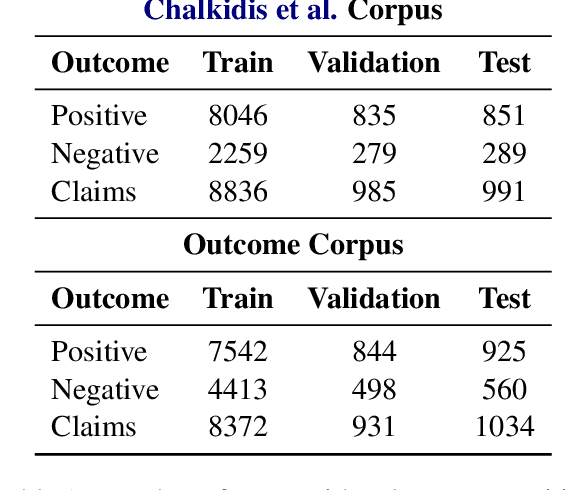
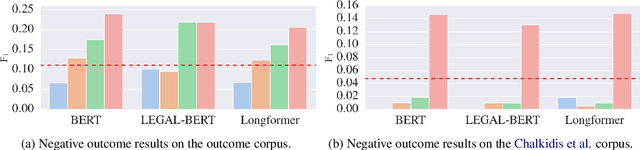
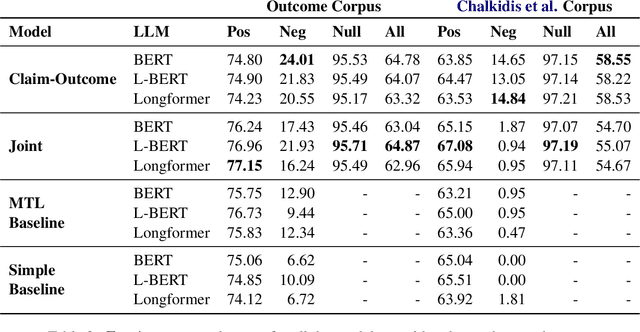
Every legal case sets a precedent by developing the law in one of the following two ways. It either expands its scope, in which case it sets positive precedent, or it narrows it down, in which case it sets negative precedent. While legal outcome prediction, which is nothing other than the prediction of positive precedents, is an increasingly popular task in AI, we are the first to investigate negative precedent prediction by focusing on negative outcomes. We discover an asymmetry in existing models' ability to predict positive and negative outcomes. Where state-of-the-art outcome prediction models predicts positive outcomes at 75.06 F1, they predicts negative outcomes at only 10.09 F1, worse than a random baseline. To address this performance gap, we develop two new models inspired by the dynamics of a court process. Our first model significantly improves positive outcome prediction score to 77.15 F1 and our second model more than doubles the negative outcome prediction performance to 24.01 F1. Despite this improvement, shifting focus to negative outcomes reveals that there is still plenty of room to grow when it comes to modelling law.