 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAmory: Building Coherent Narrative-Driven Agent Memory through Agentic Reasoning
Jan 09, 2026Long-term conversational agents face a fundamental scalability challenge as interactions extend over time: repeatedly processing entire conversation histories becomes computationally prohibitive. Current approaches attempt to solve this through memory frameworks that predominantly fragment conversations into isolated embeddings or graph representations and retrieve relevant ones in a RAG style. While computationally efficient, these methods often treat memory formation minimally and fail to capture the subtlety and coherence of human memory. We introduce Amory, a working memory framework that actively constructs structured memory representations through enhancing agentic reasoning during offline time. Amory organizes conversational fragments into episodic narratives, consolidates memories with momentum, and semanticizes peripheral facts into semantic memory. At retrieval time, the system employs coherence-driven reasoning over narrative structures. Evaluated on the LOCOMO benchmark for long-term reasoning, Amory achieves considerable improvements over previous state-of-the-art, with performance comparable to full context reasoning while reducing response time by 50%. Analysis shows that momentum-aware consolidation significantly enhances response quality, while coherence-driven retrieval provides superior memory coverage compared to embedding-based approaches.
HR-Agent: A Task-Oriented Dialogue (TOD) LLM Agent Tailored for HR Applications
Oct 15, 2024Recent LLM (Large Language Models) advancements benefit many fields such as education and finance, but HR has hundreds of repetitive processes, such as access requests, medical claim filing and time-off submissions, which are unaddressed. We relate these tasks to the LLM agent, which has addressed tasks such as writing assisting and customer support. We present HR-Agent, an efficient, confidential, and HR-specific LLM-based task-oriented dialogue system tailored for automating repetitive HR processes such as medical claims and access requests. Since conversation data is not sent to an LLM during inference, it preserves confidentiality required in HR-related tasks.
Synthesizing Conversations from Unlabeled Documents using Automatic Response Segmentation
Jun 06, 2024
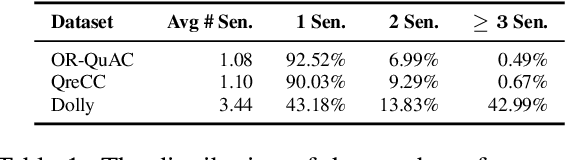
In this study, we tackle the challenge of inadequate and costly training data that has hindered the development of conversational question answering (ConvQA) systems. Enterprises have a large corpus of diverse internal documents. Instead of relying on a searching engine, a more compelling approach for people to comprehend these documents is to create a dialogue system. In this paper, we propose a robust dialog synthesising method. We learn the segmentation of data for the dialog task instead of using segmenting at sentence boundaries. The synthetic dataset generated by our proposed method achieves superior quality when compared to WikiDialog, as assessed through machine and human evaluations. By employing our inpainted data for ConvQA retrieval system pre-training, we observed a notable improvement in performance across OR-QuAC benchmarks.
LOLAMEME: Logic, Language, Memory, Mechanistic Framework
May 31, 2024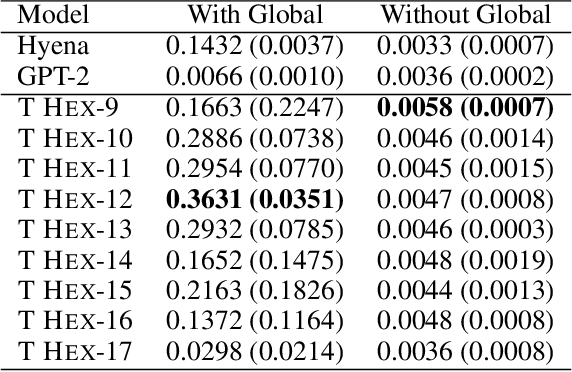
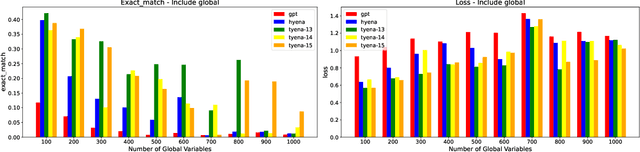
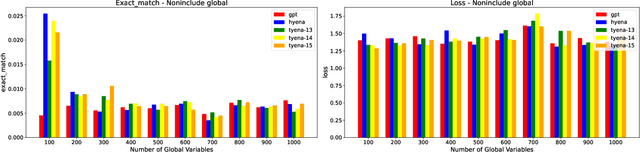

The performance of Large Language Models has achieved superhuman breadth with unprecedented depth. At the same time, the language models are mostly black box models and the underlying mechanisms for performance have been evaluated using synthetic or mechanistic schemes. We extend current mechanistic schemes to incorporate Logic, memory, and nuances of Language such as latent structure. The proposed framework is called LOLAMEME and we provide two instantiations of LOLAMEME: LoLa and MeMe languages. We then consider two generative language model architectures: transformer-based GPT-2 and convolution-based Hyena. We propose the hybrid architecture T HEX and use LOLAMEME framework is used to compare three architectures. T HEX outperforms GPT-2 and Hyena on select tasks.
JADS: A Framework for Self-supervised Joint Aspect Discovery and Summarization
May 28, 2024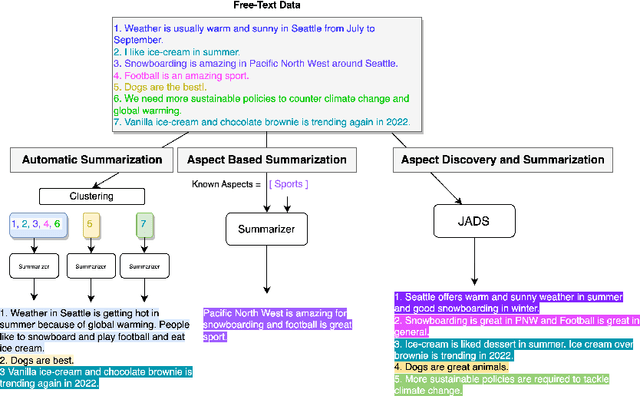
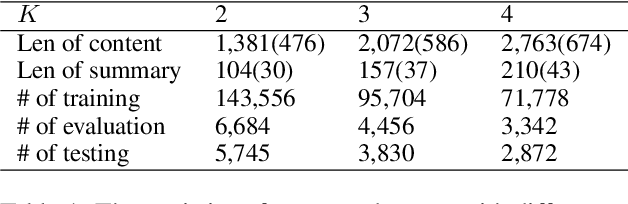
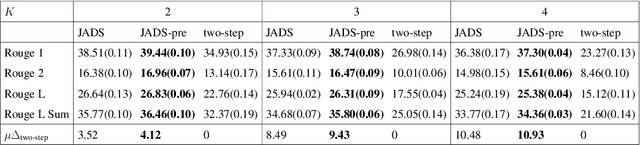
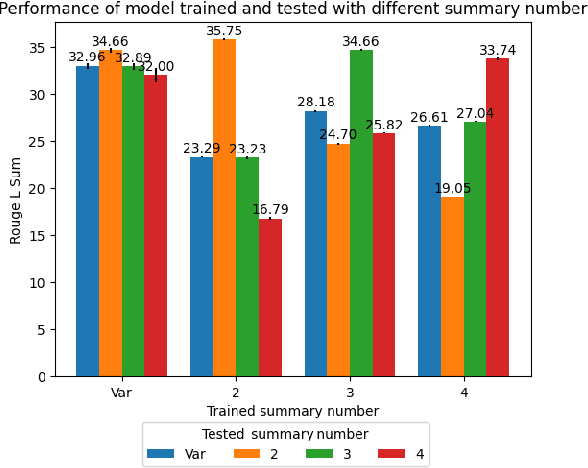
To generate summaries that include multiple aspects or topics for text documents, most approaches use clustering or topic modeling to group relevant sentences and then generate a summary for each group. These approaches struggle to optimize the summarization and clustering algorithms jointly. On the other hand, aspect-based summarization requires known aspects. Our solution integrates topic discovery and summarization into a single step. Given text data, our Joint Aspect Discovery and Summarization algorithm (JADS) discovers aspects from the input and generates a summary of the topics, in one step. We propose a self-supervised framework that creates a labeled dataset by first mixing sentences from multiple documents (e.g., CNN/DailyMail articles) as the input and then uses the article summaries from the mixture as the labels. The JADS model outperforms the two-step baselines. With pretraining, the model achieves better performance and stability. Furthermore, embeddings derived from JADS exhibit superior clustering capabilities. Our proposed method achieves higher semantic alignment with ground truth and is factual.
HR-MultiWOZ: A Task Oriented Dialogue Dataset for HR LLM Agent
Feb 01, 2024



Recent advancements in Large Language Models (LLMs) have been reshaping Natural Language Processing (NLP) task in several domains. Their use in the field of Human Resources (HR) has still room for expansions and could be beneficial for several time consuming tasks. Examples such as time-off submissions, medical claims filing, and access requests are noteworthy, but they are by no means the sole instances. However, the aforementioned developments must grapple with the pivotal challenge of constructing a high-quality training dataset. On one hand, most conversation datasets are solving problems for customers not employees. On the other hand, gathering conversations with HR could raise privacy concerns. To solve it, we introduce HR-Multiwoz, a fully-labeled dataset of 550 conversations spanning 10 HR domains to evaluate LLM Agent. Our work has the following contributions: (1) It is the first labeled open-sourced conversation dataset in the HR domain for NLP research. (2) It provides a detailed recipe for the data generation procedure along with data analysis and human evaluations. The data generation pipeline is transferable and can be easily adapted for labeled conversation data generation in other domains. (3) The proposed data-collection pipeline is mostly based on LLMs with minimal human involvement for annotation, which is time and cost-efficient.
* 13 pages, 9 figures
Sequence-Level Certainty Reduces Hallucination In Knowledge-Grounded Dialogue Generation
Oct 28, 2023Model hallucination has been a crucial interest of research in Natural Language Generation (NLG). In this work, we propose sequence-level certainty as a common theme over hallucination in NLG, and explore the correlation between sequence-level certainty and the level of hallucination in model responses. We categorize sequence-level certainty into two aspects: probabilistic certainty and semantic certainty, and reveal through experiments on Knowledge-Grounded Dialogue Generation (KGDG) task that both a higher level of probabilistic certainty and a higher level of semantic certainty in model responses are significantly correlated with a lower level of hallucination. What's more, we provide theoretical proof and analysis to show that semantic certainty is a good estimator of probabilistic certainty, and therefore has the potential as an alternative to probability-based certainty estimation in black-box scenarios. Based on the observation on the relationship between certainty and hallucination, we further propose Certainty-based Response Ranking (CRR), a decoding-time method for mitigating hallucination in NLG. Based on our categorization of sequence-level certainty, we propose 2 types of CRR approach: Probabilistic CRR (P-CRR) and Semantic CRR (S-CRR). P-CRR ranks individually sampled model responses using their arithmetic mean log-probability of the entire sequence. S-CRR approaches certainty estimation from meaning-space, and ranks a number of model response candidates based on their semantic certainty level, which is estimated by the entailment-based Agreement Score (AS). Through extensive experiments across 3 KGDG datasets, 3 decoding methods, and on 4 different models, we validate the effectiveness of our 2 proposed CRR methods to reduce model hallucination.
vONTSS: vMF based semi-supervised neural topic modeling with optimal transport
Jul 03, 2023
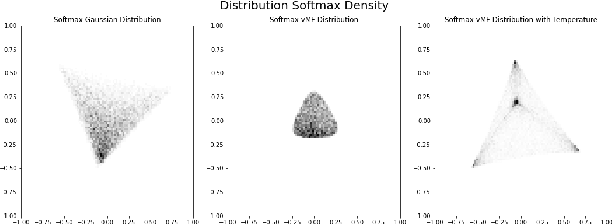
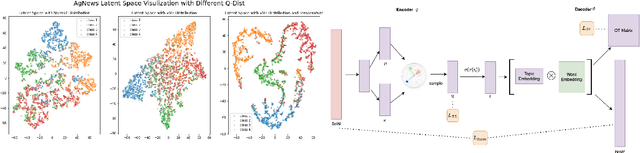
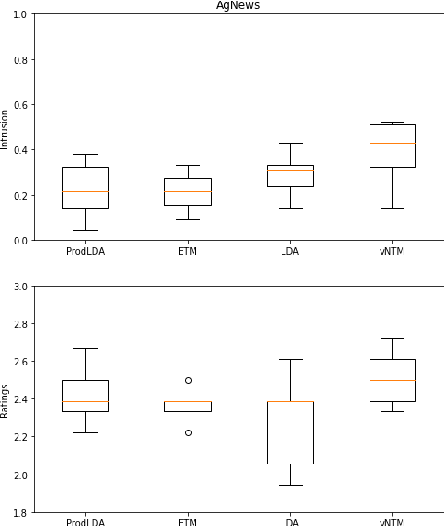
Recently, Neural Topic Models (NTM), inspired by variational autoencoders, have attracted a lot of research interest; however, these methods have limited applications in the real world due to the challenge of incorporating human knowledge. This work presents a semi-supervised neural topic modeling method, vONTSS, which uses von Mises-Fisher (vMF) based variational autoencoders and optimal transport. When a few keywords per topic are provided, vONTSS in the semi-supervised setting generates potential topics and optimizes topic-keyword quality and topic classification. Experiments show that vONTSS outperforms existing semi-supervised topic modeling methods in classification accuracy and diversity. vONTSS also supports unsupervised topic modeling. Quantitative and qualitative experiments show that vONTSS in the unsupervised setting outperforms recent NTMs on multiple aspects: vONTSS discovers highly clustered and coherent topics on benchmark datasets. It is also much faster than the state-of-the-art weakly supervised text classification method while achieving similar classification performance. We further prove the equivalence of optimal transport loss and cross-entropy loss at the global minimum.
* 24 pages, 12 figures, ACL findings 2023
Code Compliance Assessment as a Learning Problem
Sep 10, 2022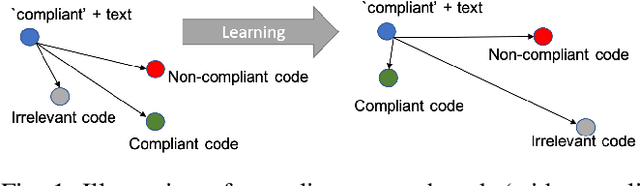

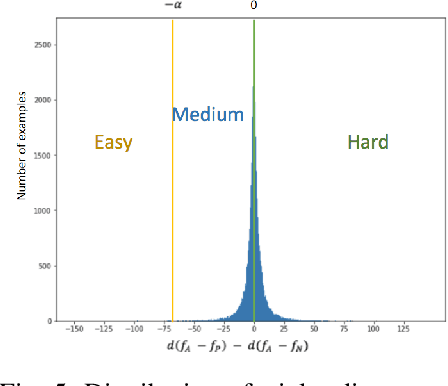
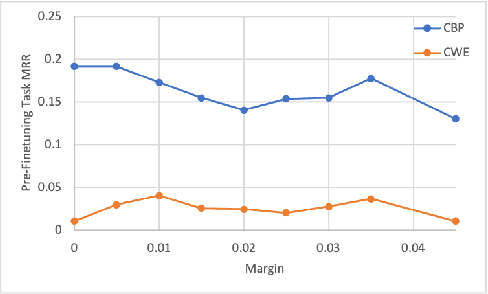
Manual code reviews and static code analyzers are the traditional mechanisms to verify if source code complies with coding policies. However, these mechanisms are hard to scale. We formulate code compliance assessment as a machine learning (ML) problem, to take as input a natural language policy and code, and generate a prediction on the code's compliance, non-compliance, or irrelevance. This can help scale compliance classification and search for policies not covered by traditional mechanisms. We explore key research questions on ML model formulation, training data, and evaluation setup. The core idea is to obtain a joint code-text embedding space which preserves compliance relationships via the vector distance of code and policy embeddings. As there is no task-specific data, we re-interpret and filter commonly available software datasets with additional pre-training and pre-finetuning tasks that reduce the semantic gap. We benchmarked our approach on two listings of coding policies (CWE and CBP). This is a zero-shot evaluation as none of the policies occur in the training set. On CWE and CBP respectively, our tool Policy2Code achieves classification accuracies of (59%, 71%) and search MRR of (0.05, 0.21) compared to CodeBERT with classification accuracies of (37%, 54%) and MRR of (0.02, 0.02). In a user study, 24% Policy2Code detections were accepted compared to 7% for CodeBERT.
E-commerce Anomaly Detection: A Bayesian Semi-Supervised Tensor Decomposition Approach using Natural Gradients
May 29, 2018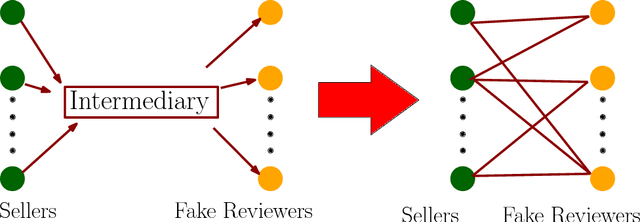
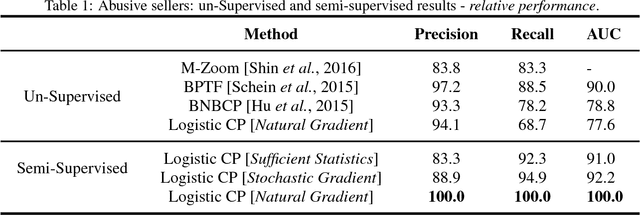
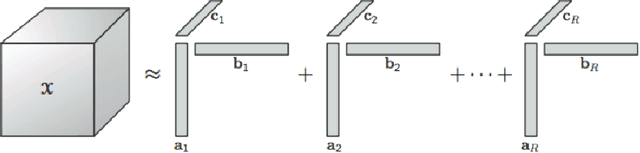
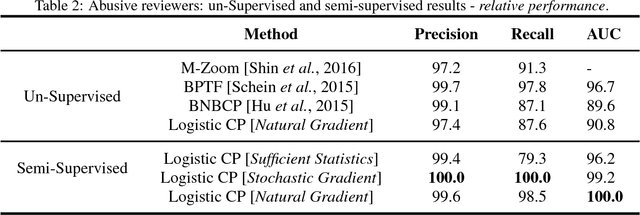
Anomaly Detection has several important applications. In this paper, our focus is on detecting anomalies in seller-reviewer data using tensor decomposition. While tensor-decomposition is mostly unsupervised, we formulate Bayesian semi-supervised tensor decomposition to take advantage of sparse labeled data. In addition, we use Polya-Gamma data augmentation for the semi-supervised Bayesian tensor decomposition. Finally, we show that the P\'olya-Gamma formulation simplifies calculation of the Fisher information matrix for partial natural gradient learning. Our experimental results show that our semi-supervised approach outperforms state of the art unsupervised baselines. And that the partial natural gradient learning outperforms stochastic gradient learning and Online-EM with sufficient statistics.