 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCode Compliance Assessment as a Learning Problem
Sep 10, 2022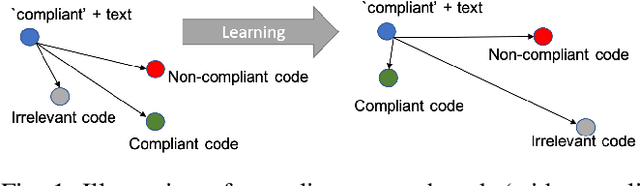

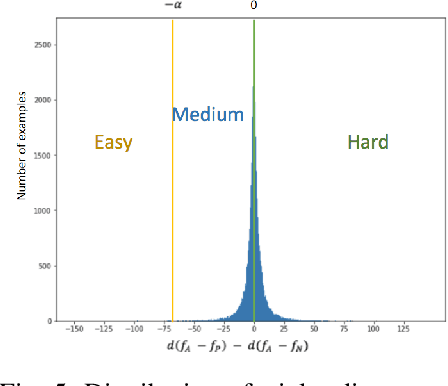
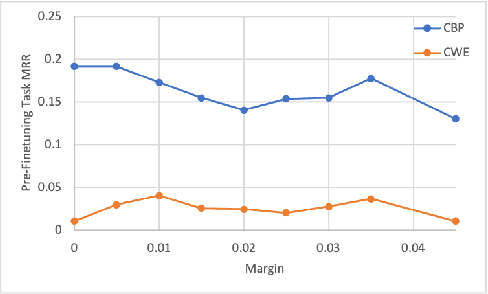
Manual code reviews and static code analyzers are the traditional mechanisms to verify if source code complies with coding policies. However, these mechanisms are hard to scale. We formulate code compliance assessment as a machine learning (ML) problem, to take as input a natural language policy and code, and generate a prediction on the code's compliance, non-compliance, or irrelevance. This can help scale compliance classification and search for policies not covered by traditional mechanisms. We explore key research questions on ML model formulation, training data, and evaluation setup. The core idea is to obtain a joint code-text embedding space which preserves compliance relationships via the vector distance of code and policy embeddings. As there is no task-specific data, we re-interpret and filter commonly available software datasets with additional pre-training and pre-finetuning tasks that reduce the semantic gap. We benchmarked our approach on two listings of coding policies (CWE and CBP). This is a zero-shot evaluation as none of the policies occur in the training set. On CWE and CBP respectively, our tool Policy2Code achieves classification accuracies of (59%, 71%) and search MRR of (0.05, 0.21) compared to CodeBERT with classification accuracies of (37%, 54%) and MRR of (0.02, 0.02). In a user study, 24% Policy2Code detections were accepted compared to 7% for CodeBERT.
Contextual Multi-Armed Bandits for Causal Marketing
Oct 02, 2018
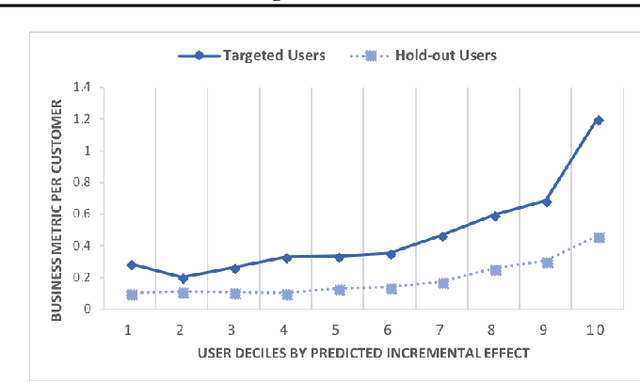
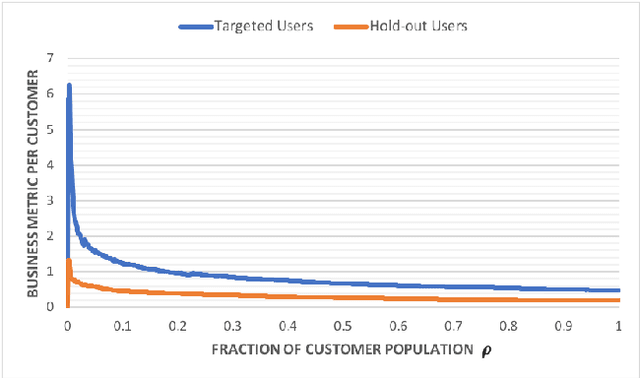
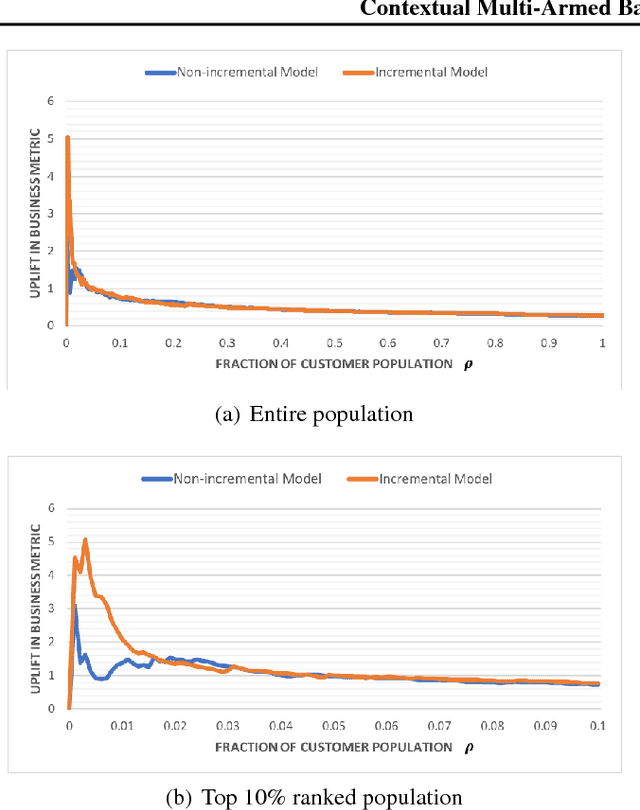
This work explores the idea of a causal contextual multi-armed bandit approach to automated marketing, where we estimate and optimize the causal (incremental) effects. Focusing on causal effect leads to better return on investment (ROI) by targeting only the persuadable customers who wouldn't have taken the action organically. Our approach draws on strengths of causal inference, uplift modeling, and multi-armed bandits. It optimizes on causal treatment effects rather than pure outcome, and incorporates counterfactual generation within data collection. Following uplift modeling results, we optimize over the incremental business metric. Multi-armed bandit methods allow us to scale to multiple treatments and to perform off-policy policy evaluation on logged data. The Thompson sampling strategy in particular enables exploration of treatments on similar customer contexts and materialization of counterfactual outcomes. Preliminary offline experiments on a retail Fashion marketing dataset show merits of our proposal.