 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCode Compliance Assessment as a Learning Problem
Paper and Code
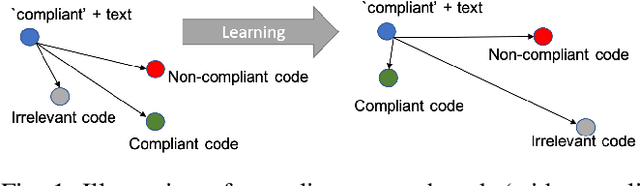

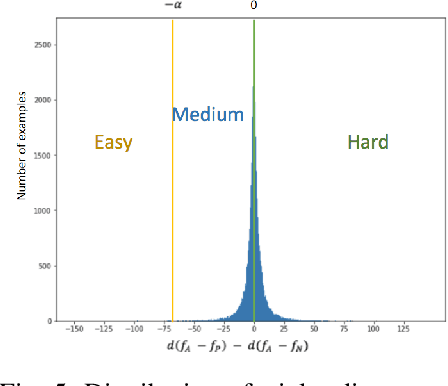
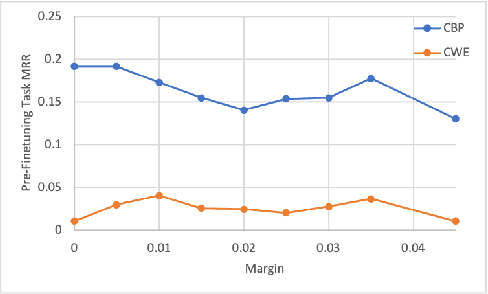
Manual code reviews and static code analyzers are the traditional mechanisms to verify if source code complies with coding policies. However, these mechanisms are hard to scale. We formulate code compliance assessment as a machine learning (ML) problem, to take as input a natural language policy and code, and generate a prediction on the code's compliance, non-compliance, or irrelevance. This can help scale compliance classification and search for policies not covered by traditional mechanisms. We explore key research questions on ML model formulation, training data, and evaluation setup. The core idea is to obtain a joint code-text embedding space which preserves compliance relationships via the vector distance of code and policy embeddings. As there is no task-specific data, we re-interpret and filter commonly available software datasets with additional pre-training and pre-finetuning tasks that reduce the semantic gap. We benchmarked our approach on two listings of coding policies (CWE and CBP). This is a zero-shot evaluation as none of the policies occur in the training set. On CWE and CBP respectively, our tool Policy2Code achieves classification accuracies of (59%, 71%) and search MRR of (0.05, 0.21) compared to CodeBERT with classification accuracies of (37%, 54%) and MRR of (0.02, 0.02). In a user study, 24% Policy2Code detections were accepted compared to 7% for CodeBERT.